A la découverte d'Hadoop
LeMagIT part à la découverte d'Hadoop, le framework Java emblématique du mouvement dit "big data". Premier article, pour comprendre Hadoop et le rôle de ses principaux composants.

La première technologie qui vient à l’esprit lorsque l’on évoque aujourd’hui le sujet du Big Data est Hadoop est le framework analytique Java développé au sein de la fondation Apache. Populaire, Hadoop reste toutefois un mystère pour nombre d’utilisateurs. Pour mieux comprendre les fondements technologiques d’Hadoop et les différentes briques qui le composent, LeMagIT s’est plongé dans l’histoire et l’architecture du framework.
 Doug Cutting, créateur d’Hadoop, avec l’éléphant
Doug Cutting, créateur d’Hadoop, avec l’éléphant
qui servait de peluche à son fils, et est aujourd'hui
la mascotte du framework Java
Hadoop trouve ses racines dans les technologies propriétaires d’analyse de données de Google. En 2004, le moteur de recherche a publié un article de recherche présentant son algorithme MapReduce, conçu pour réaliser des opérations analytiques à grande échelle sur un grand cluster de serveurs, et sur son système de fichier en cluster, Google Filesystem (GFS). Doug Cutting, qui travaillait alors sur le développement du moteur de recherche libre Apache Lucene et butait sur les mêmes problèmes de volumétrie de données qu’avait rencontré Google, s’est alors emparé des concepts décrits dans l’article du géant de la recherche et a décidé de répliquer en open source les outils développés par Google pour ses besoins. Employé chez Yahoo, il s’est alors lancé dans le développement de ce qui est aujourd’hui le projet Apache Hadoop – pour la petite histoire, Hadoop est le nom de l’éléphant qui servait de doudou à son jeune fils.
Hadoop : un framework modulaire
Hadoop n’a pas été conçu pour traiter de grandes quantités de données structurées à grande vitesse. Cette mission reste largement l’apanage des grands systèmes de Datawarehouse et de datamart reposant sur des SGBD traditionnelles et faisant usage de SQL comme langage de requête. La spécialité d’Hadoop, ce serait plutôt le traitement à très grande échelle de grands volumes de données non structurées tels que des documents textuels, des images, des fichiers audio… même s’il est aussi possible de traiter des données semi-structurées ou structurées avec Hadoop.
HDFS : le système de gestion de fichier en cluster au cœur d’Hadoop
Au cœur du framework open source se trouve avant tout un système de fichiers en cluster, baptisé HDFS (Hadoop Distributed Filesystem). HDFS a été conçu pour stocker de très gros volumes de données sur un grand nombre de machines équipées de disques durs banalisés.
Le filesystem HDFS est conçu pour assurer la sécurité des données en répliquant de multiples fois l’ensemble des données écrites sur le cluster. Par défaut, chaque donnée est écrite sur trois nœuds différents. Il ne s’agit pas du plus élégant des mécanismes de redondance, ni du plus efficace, mais étant donné que l’on s’appuie sur des disques durs SATA économiques, un cluster HDFS a le bénéfice d’offrir une solution de stockage très économique par rapport à celui des baies de stockage traditionnelles. En l’état, HDFS est optimisé pour maximiser les débits de données et non pas pour les opérations transactionnelles aléatoires. La taille d’un bloc de données est ainsi de 64 Mo dans HDFS contre 512 octets à 4 Ko dans la plupart des systèmes de fichiers traditionnels. Cette taille de bloc s’explique par le fait que Hadoop doit analyser de grandes quantités de données en local.
Avec la version 2.0 d’Hadoop, la principale faiblesse d’HDFS a été levée : jusqu’alors la gestion des métadonnées associées aux fichiers étaient la mission d’un unique « name node » ; ce qui constituait un point de faille unique. Depuis la version 2.0 et l’arrivée de la fonction HDFS High Availability, le "name node" est répliqué en mode actif/passif, ce qui offre une tolérance aux pannes. Un autre « défaut » d’HDFS est que le système n’est pas conforme au standard POSIX et que certaines commandes familières sur un filesystem traditionnel ne sont pas disponibles.
Il est à noter que si HDFS est le système de fichiers par défaut d’Hadoop, le framework peut aussi être déployé sur des systèmes tiers, souvent grâce à des couches de compatibilité. MapR, l’un des pionniers d’Hadoop, a ainsi développé son propre système de gestion de fichiers qui règle le problème de fragilité lié aux "name nodes" d’HDFS (en distribuant les informations de métadonnées sur les nœuds de données) et qui ajoute aussi des fonctions avancées comme les snapshots, la réplication ou le clonage. Plusieurs constructeurs de baies de stockage comme EMC, HP ou IBM ont aussi développé des couches de compatibilité HDFS au dessus de certaines de leurs baies ; ce qui leur permet de stocker les données d’un cluster Hadoop.
MapReduce : distribuer le traitement des données entre les nœuds
Le second composant majeur d’Hadoop est MapReduce, qui gère la répartition et l’exécution des requêtes sur les données stockées par le cluster. Le framework MapReduce est conçu pour traiter des problèmes parallèlisables à très grande échelle en s’appuyant sur un très grand nombre de nœuds. L’objectif de MapReduce et de son mécanisme avancé de distribution de tâches est de tirer parti de la localité entre données et traitements sur le même nœud de façon à minimiser l’impact des transferts de données entre les nœuds du cluster sur la performance.
MapReduce est un processus en plusieurs étapes. Dans la phase « Map », le nœud maitre divise le problème posé en sous-problèmes et les distribue entre nœuds de traitement. Ces nœuds peuvent en cascade distribuer à nouveau les tâches qui leur ont été assignées. Les réponses sont ensuite remontées de nœuds en nœuds jusqu’au nœud maitre ayant assigné les travaux à l’origine.
C’est alors que s’opère l’étape "Reduce" : le nœud maitre collationne les réponses remontant des nœuds de traitement et les combine afin de fournir la réponse à la question posée à l’origine. Il est à noter que les traitements Mapreduce s’opèrent sur des données structurées sous la forme (clé, valeur) et que des mécanismes d’optimisation assurent que les traitements sont distribués de telle sorte qu’ils s’opèrent au plus proche des données (c’est-à-dire idéalement sur les neuds qui hébergent les données concernées).
De nouveaux outils et langages pour faciliter les requêtes sur Hadoop
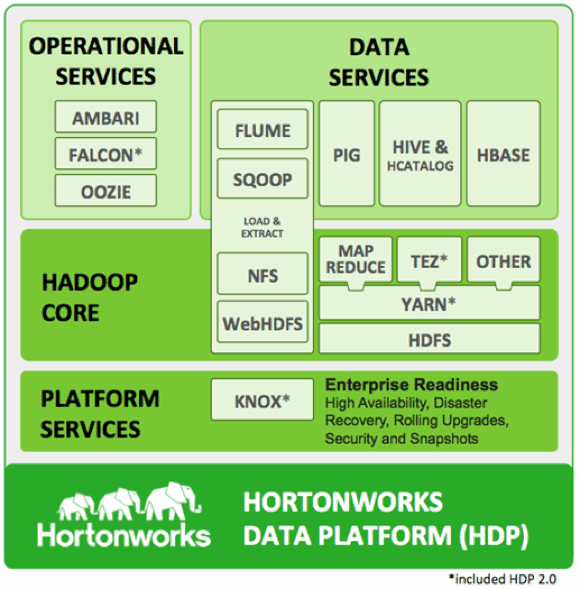
L'architecture de la distribution Hadoop d'Hortonworks
Les API clés de MapReduce sont accessibles en Java, un langage certes populaire mais qui requiert des compétences bien plus pointues que la maîtrise d’un langage d’interrogation comme SQL. Plusieurs langages ont donc émergé pour tenter de simplifier le travail des utilisateurs d’Hadoop, dont Pig et Hive. Né chez Yahoo, Pig est conçu pour traiter toute forme de données. Le langage de Pig est PigLatin, complété par un runtime destiné à exécuter les programmes rédigés en PigLatin. PigLatin a une sémantique assez simple. Il permet de charger des données, puis de les manipuler (appliquer des filtres, des groupements, des opérations mathématiques…).
Chez Facebook, des développeurs ont quant à eux conçu Hive, pour permettre à des développeurs familiers du langage SQL de manipuler des données dans Hadoop. Hive dispose d’un langage baptisé HQL (Hive Query Langage) dont la syntaxe est similaire à celle de SQL. Le service Hive découpe les requêtes en jobs MapReduce afin de les exécuter sur le cluster.
Au fil des ans, Hadoop a continué à s’enrichir de nouvelles applications, comme la base de données Hbase, qui fournit des services similaires au service BigTable de Google. Hbase est une base de données en colonnes (dans la mouvance NoSQL) qui s’appuie sur le système de gestion de fichiers en cluster HDFS pour le stockage de ses données. Hbase est notamment utile pour ceux qui ont besoin d’accès aléatoires en lecture/écriture à de grands volumes de données. La base intègre des fonctions de compression et de traitement « in-memory ».
Parmi les autres composants connus, on peut aussi citer la technologie d’apprentissage Apache Mahout, ainsi que la technologie d’administration de cluster Zookeeper. Zookeeper est lui-même un service distribué qui permet de coordonner l’ensemble des processus distribués sur le cluster, mais aussi de gérer les configurations de ses différents éléments.
Un écosystème qui ne cesse de s’enrichir
Signalons pour terminer que le périmètre d’Hadoop continue de s’élargir, les différents développeurs de distributions Hadoop ajoutant progressivement de nouveaux composants, outils ou langages afin d’enrichir les composants de base du framework. Cloudera a ainsi récemment publié Impala, sa technologie de query SQL massivement parallèle, pour le traitement en temps réel de données stockées dans Hbase ou dans HDFS. Dans le cadre de son projet Hawq, Pivotal a, quant à lui, porté sa base de données massivement parallèle Greenplum sur HDFS et étendu sa technologie de query aux données non structurées et semi-structurées stockées sur HDFS. Et c’est sans compter sur les multiples intégrations réalisées par des acteurs des bases de données traditionnelles et de l’analytique, comme Teradata, Oracle ou Microsoft… Un signe évident du dynamisme de l’écosystème Hadoop, mais aussi de sa relative jeunesse.