OpenStack ou le difficile passage à l’âge de raison (selon Sébastien Déon)
Avec un taux de pénétration qui grandit d’année en année, OpenStack a vu son champ fonctionnel évoluer… et les projets se multiplier. A tel point que la question de son orientation future se pose : le projet, aujourd’hui symbole de Cloud privé Open Source restera-t-il cantonné à fournir des services d’infrastructure unifié ou amorcera-t-il une transition vers les couches plus hautes et fournir des services au plus près des métiers ? Sébastien Déon livre son point de vue.
OpenStack a grandi en 7 ans. La version dernière version Ocata propose plus de 30 modules. La multiplication de ces modules est-il un problème pour son implémentation ? Quelle va être désormais son évolution ?
La multiplication des modules n’est pas un problème pour son implémentation à condition de cartographier les modules et de définir le périmètre du projet d’implémentation
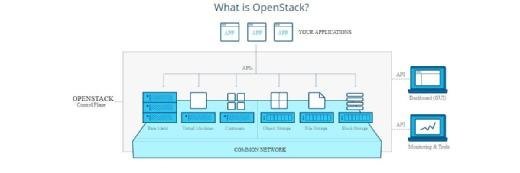
Sortie en février 2017, Ocata, la 15ème distribution du framework, comporte plus de 30 modules ou services. Ces services peuvent être classés selon 3 axes :
- Les services de base
Parmi les services de base, on retrouve les inévitables services historiques comme la gestion des identités (KeyStone), la gestion des images (Glance), la gestion du compute (Nova), la gestion du réseau (Neutron), la gestion de l’IHM web (dashboard) et la gestion du stockage (stockage bloc avec Cinder et stockage objet avec Swift). Ces services sont de loin les plus utilisés. N’oublions pas qu’OpenStack, en tant que frawework de cloud-computing de niveau IAAS, est là avant tout pour fournir rapidement des centaines, des milliers de machines virtuelles à partir d’images prédéfinies, là où il fallait parfois des semaines ou des mois pour obtenir une simple VM.
- Les services additionnels
Les services additionnels ne sont pas vitaux dans une architecture OpenStack mais ils enrichissent considérablement le niveau des fonctionnalités du framework. Par exemple, dès lors qu’on manipule des bases de données à longueur du temps, on a bien envie d’automatiser le provisioning des VMs comportant des services de bases de données ; c’est tout à fait le rôle du service Trove. Parmi les services additionnels les plus connus et les plus utilisés, on retrouve :
-
- Le service Bare Metal avec Ironic pour provisionner des machines physiques
- Le service de base de données avec Trove
- Le service de gestion DNS avec Designate
- Le service de gestion des clés de sécurité avec Barbican
- Le service de messagerie avec Zaquar
- Le service d’orchestration avec Heat pour le provisioning automatisé de stacks complètes
- Le service de gestion big data avec Sahara
- Le service de système de fichiers partagés avec Manila
- Le service de monitoring Telemetry avec les alarmes d’Aodh et le data collection de Ceilometer
- Le service de gestion des containers avec Magnum pour créer un cluster de containers (type Swarm, Kubernetes, …) et les containers
- Le service Murano pour le provisionning automatique d’applications
- … (cette liste n’est pas exhaustive)
On le voit bien, les services de base sont le cœur d’OpenStack mais cela ne suffit pas pour couvrir l’étendue des workloads applicatifs potentiels d’entreprise. Les modules complémentaires sont non seulement nécessaires mais vitaux et stratégiques pour l’avenir du framework. L’innovation et la course permanente aux nouvelles fonctions sont le prix à payer pour rester leader sur ce marché du cloud privé Open Source.
Premièrement, dans la mesure où les modules se multiplient, il faut une véritable cartographie applicative afin de savoir à quoi ils servent, comment les installer, comment les utiliser et les intégrer dans la plateforme. En ce sens, un service de cartographie comme Project Navigator permet de disposer d’une liste détaillée de modules OpenStack, liste d’ailleurs maintenue par la Fondation Openstack.
Deuxièmement, il est essentiel de définir le périmètre du projet de déploiement d’OpenStack afin de limiter l’installation des modules : en effet, si aucun besoin en gestion de cluster Big Data n’est répertorié, il ne faut pas installer le module Sahara au risque de complexifier l’architecture, sa maintenance et d’alourdir la facture du projet. L’installation et l’activation des modules doivent être pilotées.
A contrario d’un client final, un cloud provider aura tout intérêt à installer une architecture OpenStack avec un maximum de modules « as a service » afin de commercialiser un catalogue de services le plus riche possible : par exemple, un éditeur de logiciel développant des applications à base de containers a besoin de disposer d’un cluster Swarm, il se connecte à son cloud provider et va, sans le savoir, consommer le module Magnum.
Une évolution nécessaire : choisir ou subir
OpenStack est à la croisée des chemins dans son orientation qui va structurer son prochain développement. On dit souvent que l’âge de raison pour un enfant se situe à 7 ans. Pour le framework cloud Open Source modulaire OpenStack créé en 2010 et qui gère pas loin de 5 millions de cœurs en production à travers le monde (selon la dernière étude utilisateur de la Fondation OpenStack), c’est sans conteste le moment de rentrer dans une nouvelle phase de sa croissance.
En effet, OpenStack est disponible dans des versions dites STABLES,qui peuvent être utilisées en entreprise de toute taille dans des environnements de production - cela signifie que des machines virtuelles, des containers et des machines bare metal sont en service pour délivrer de la valeur métier. OpenStack est en cela un véritable système de CloudComputing de niveau IaaS.
Mais comment va-t-il grandir ? Doit-il faire cavalier seul et et se cantonner à un rôle de fournisseur de ressources de compute, réseau, stockage et autres services additionnels d’infrastructures ? Doit-il se transformer et proposer des services métiers technologiques évolués permettant de simplifier le travail des DevOps ? Doit-il muer en services de PIaaS (mariage du PaaS et du IaaS) et proposer ses propres services métiers fonctionnels ?
Le « PIaaS », le mariage entre le IaaS et le PaaS pour fabriquer encore plus de la valeur métier
Dans les années qui viennent, les IaaS finiront probablement par se banaliser et disparaître en tant que tels; ils seront avalés par les PaaS qui fourniront l’unique couche de création des services métiers, tout en faisant abstraction du IaaS. Les PaaS consommeront des IaaS.
Il est fort à parier qu’il faudra envisager le provisionning rapide et complet de véritables « workloads » de cloud métier avec des règles de gestion précises comme par exemple :
- Un environnement de gestion de Big Data de données de santé
- Un environnement cloisonné de gestion de messagerie (mail, antispam, dns, relais SMTP, …)
- Un environnement isolé en DMZ pour une usine de développement logicielle (GIT, Jenkins, Ansible, …)
- Un environnement de gestion des données issues de l’IoT.
Le futur déploiement d’OpenStack passera donc par l’enrichissement de briques fonctionnelles apportant un ou plusieurs incréments de valeur métier.
Enfin, il faut tenir compte de l’évolution positive et négative de la perception des entreprises au sujet du Cloud public ; positive parce que le Cloud public apporte des gains importants et rapides avec son système d’OPEX par rapport à l’investissement lourd proposé par le CAPEX; négative parce que les entreprises veulent garder la main sur leur patrimoine IT. OpenStack, en tant que spécialiste du Cloud privé, a alors toute sa place dans le monde de l’hybridation de Cloud sous la forme de Private Cloud As A Service (PCaaS) managé à distance. C’est peut-être là son avenir.
Sébastien Déon (@sebastien_deon sur Twitter) est directeur technique adjoint chez Pharmagest Interactive. Il est à la tête du service Architectures Techniques, Outils et Méthodes au sein de la Direction R&D de la société. Il est également l’auteur de plusieurs ouvrages dédiés notamment aux technologies Open Source, comme OpenStack, dont nous nous faisions l’écho dans LeMagIT, à Zimbra (messagerie collaborative) ou encore à Asterisk (VoIP et ToIP pour entreprise).
Pour approfondir sur Administration et supervision du Cloud
-
![]()
Commvault : « Personne n’a notre niveau d’expertise dans la sauvegarde en cloud »
Par: Yann Serra
-
![]()
Infrastructures cloud : le Français Thierry Carrez prend les rênes d’OpenStack
Par: Yann Serra
-
![]()
Les prochains satellites d’Airbus entièrement exploités par l’Open source
Par: Yann Serra
-
![]()
OpenStack s’attaque à l’accélération hardware à grande échelle
Par: Pierre Berlemont



