Avec les LLM, place à l’ère des systèmes multiagents (Octo Technology)
Dans une présentation lors de la Gross Conf' organisée par Octo Technology, son responsable de l’IA générative a évoqué l’avènement en cours des systèmes multiagents propulsés par de grands modèles de langage. Un concept qui devrait provoquer un bouleversement du développement logiciel, selon l’intéressé.
Depuis la fin de l’année 2023, un concept anime en arrière-plan certaines personnalités de l’IT et de l’IA générative. Le marché se concentre actuellement sur le développement d’assistants d’IA générative et d’architecture RAG (Retreival Augmented Generation) pour les ancrer dans la réalité de terrain. Or il y a une étape supérieure : le concept de systèmes multiagents IA.
Habituellement, le terme « agent » sert à désigner un assistant conversationnel. Lors de la Grosse Conf’ le 27 mars à Paris, Nicolas Cavallo, le responsable de l’IA générative chez Octo Technology, une filiale d’Accenture, a présenté ses agents comme de grands modèles de langage spécialisés capables d’échanger entre eux pour résoudre des problèmes ou accomplir des tâches avancées en réponse à la demande d’un humain. Ce serait le début de l’ère des systèmes multiagents (SMA).
Cela est rendu possible par le fait que le domaine de la recherche en traitement du langage naturel est « entrée dans l’ère de l’alignement », d’après Nicolas Cavallo. Les modèles sont dits « alignés » après avoir subi une phase de fine-tuning (d’affinage) pour respecter les préférences humaines. La première phase de fine-tuning consiste à rendre les grands modèles de langage plus performant au moment d’échanger avec un utilisateur et de suivre des instructions. La deuxième vise, généralement, à supprimer les erreurs de prédictions, les fausses informations, les biais ou encore les contenus nocifs qui n’auraient pas été éliminés lors de la phase de préentraînement. Une troisième phase peut intervenir après coup pour spécialiser un modèle dans l’accomplissement d’une tâche spécifique.
Les LLM redonnent du souffle à un « vieux » concept
Un LLM ne suffit pas pour définir un agent. « Un agent a la capacité de percevoir son environnement », décrit Nicolas Cavallo. « Vous pouvez lui donner du texte, de l’audio, des images, etc. Il peut prendre des décisions, planifier des tâches, répertorier une liste d’actions à accomplir ».
Cette intégration de modèles d’IA dans un environnement, cette « connexion des agents au monde » n’est pas une nouvelle pratique. « Vous le faites déjà quand vous exposez vos données ou vos services à des assistants », signale le responsable.
Dans le cadre de cette architecture multiagent, les LLM sont interconnectés et se transmettent leurs résultats afin de faire avancer la tâche pour laquelle ils sont appelés. « Ces systèmes multiagents ne sont pas nouveaux, cela fait des décennies que l’on tente d’intégrer des modèles d’IA entre eux », avance Nicolas Cavallo. Plus particulièrement, la première définition des SMA a vu le jour dans les années 1980, en même temps que le développement des systèmes experts. « Ce qui change, c’est que les LLM fournissent un moyen d’échanges universel : le langage humain, principalement en anglais ».
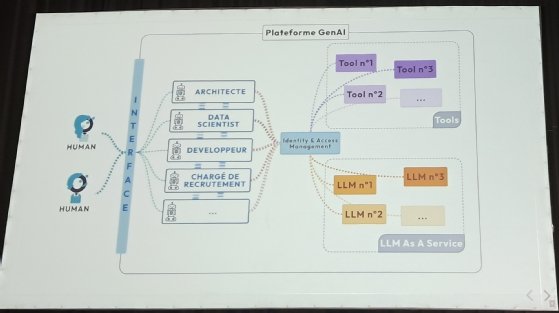
Ces agents autonomes ou semi-autonomes ne s’appuient pas seulement sur leurs capacités. Ils sont dotés de capacités de lecture, comme les assistants le sont aujourd’hui une fois qu’ils sont intégrés à une architecture RAG. Ils peuvent aussi être dotés de capacités d’écriture : inscrire une ligne dans une base de données, envoyer un pull request, exécuter du code dans un environnement sandbox…, voilà quelques-uns des moyens qui peuvent être donnés aux agents à qui l’on envisage de confier des accès via un IAM.
Un système multiagent dans lequel les agents ont des accès en écriture dans les applications à travers un IAM.
Le cas d’usage évident selon Nicolas Cavallo ? Le développement d’applications. Un agent architecte superviserait le travail d’agents ingénieurs et d’agents développeurs afin – a minima – de produire des POCs applicatifs à partir de l’expression de besoins métier.
Ce n’est pas un doux rêve, signale le responsable de l’IA générative. Au moins deux frameworks rendent déjà faisable cette architecture multiagent : MetaGPT et AutoGen. MetaGPT est consacré aux développements d’agents permettant de développer des applications, tandis qu’AutoGen est un projet de Microsoft permettant, entre autres, de concevoir des flux d’échanges entre des LLM.
« En novembre 2023, Bill Gates affirme ceci : “les agents IA ne vont pas seulement changer la façon dont chacun interagit avec les ordinateurs, ils vont également bouleverser l’industrie du logiciel, provoquant la plus grande révolution informatique”. Rien que ça », déclare le responsable en préambule de son propos. « Bill Gates n’est peut-être plus objectif aujourd’hui, vu que Microsoft a en quelque sorte la mainmise sur OpenAI, mais ses analyses conservent un certain poids ».
Vers des systèmes d’information semi-autonomes
Une partie du marché serait en train d’imaginer l’intégration de cette architecture multiagent dans les SI des entreprises.
« Ce qui va se produire, c’est que des agents seront intégrés à votre système d’information ».
Nicolas CavalloHead of Generative AI, Octo Technology
« Ce qui va se produire, c’est que des agents seront intégrés à votre système d’information. Ces agents, dont les profils peuvent varier, peuvent être des architectes, des data scientists, des développeurs, ou encore des chargés de recrutement pour recruter des développeurs humains, mais aussi spécialisés dans le recrutement d’autres agents », envisage Nicolas Cavallo auprès d’un parterre d’architectes, de développeurs et de différents responsables IT. « Chacun aura des droits spécifiques et accès à certains outils et modèles de langage. Par exemple, l’architecte aura la capacité de gérer les Identity Access Management pour les agents eux-mêmes, tandis que le data scientist collaborera avec d’autres agents pour répondre aux demandes et former une équipe ».
En ce sens, de nouvelles interfaces sont amenées à voir le jour. « Ces interfaces permettront de diriger les interactions entre les machines, les applications et les humains », décrit le responsable.
« L’aspect crucial ici réside dans les autorisations que vous accordez à ces agents. Il est possible que, compte tenu de leur potentiel, vous leur attribuiez des droits importants, ce qui nécessitera la mise en place d’une nouvelle architecture. Ainsi, vous devez envisager comment exposer vos services et applications à ces agents, tout en facilitant leur interaction avec les humains ».
Et de prouver ses propos à coup de démonstrations, notamment en présentant le travail de Cognition.ai, une startup qui développe Devin, un système multiagent capable de développer des applications étape par étape. De son côté, OpenAI a fait la démonstration de FigureOne, le fruit d’une collaboration entre Figure.ai et OpenAI. L’objectif ? Doter un robot humanoïde d’un système propulsé en partie par GPT-4.
Le résultat ? Un silence soutenu dans la salle du pavillon Chesnaie du Roy qui accueillait la conférence.
« Ce monde a déjà commencé. Il est inévitable que les agents deviennent une partie intégrante de notre paysage technologique dans les années à venir », prévient Nicolas Cavallo. « Il y a du travail pour organiser et sécuriser [ces systèmes multiagents] ».
« Ce monde a déjà commencé. Il est inévitable que les agents deviennent une partie intégrante de notre paysage technologique dans les années à venir ».
Nicolas CavalloHead of Generative AI, Octo Technology
Deux barrières majeures sont en train de céder
Pour l’heure, le non-déterminisme des LLMs peut conduire à la production de réponses légèrement différentes. La qualité des données d’entraînement (ou lors du fine tuning) et l’encadrement des résultats à l’aide de divers outils sont cruciaux dans l’émergence de ces systèmes multiagents.
Il faut surtout prévoir des systèmes d’observabilité qui prennent en compte la détection d’anomalies, de comportements suspects, l’identification de bugs en temps réel, conçoit le responsable. Il est important de reconnaître que les agents peuvent également être déployés en production, et dans ce cas, des mesures doivent être prises pour garantir leur sécurité et leur fiabilité. Cela peut inclure des mécanismes de débogage en temps réel et des contrôles de qualité stricts pour s’assurer que les agents fonctionnent correctement, résume Nicolas Cavallo.
Il y a encore deux limites au déploiement de tels systèmes, même en tests : les coûts financiers et environnementaux. Ce ne sont que des freins que les acteurs de l’écosystème cherchent à dégripper.
« Ces coûts sont en train de baisser. Le coût d’inférence de GPT-4 a été divisé par 60. Il y a beaucoup d’optimisations technologiques : les mixture of experts, la quantization, etc. », liste Nicolas Cavallo. « De plus, les progrès dans la conception des puces et des architectures informatiques contribuent à cette tendance à la baisse des coûts. Dans moins de trois ans, il est probable que les coûts d’inférence soient divisés par 1000 ».
Les milliers d’appels peuvent aussi générer de la latence afin de résoudre le problème ou accomplir la tâche demandée. Un temps de réponse plus lent qui, selon le cas d’usage, peut être considéré comme acceptable, considère le responsable. Il est même probable que le taux d’échec, sans doute élevé dans une première implémentation, ne soit pas un véritable problème, tant que le système multiagent produit au moins quelques résultats cohérents. « Supposons que le système produise deux bons résultats sur 100 requêtes. L’humain étant ainsi fait, l’on va l’exécuter 100 fois et l’on conservera les deux bons résultats », estime-t-il.
Pour approfondir sur Intelligence Artificielle et Data Science