Le Crédit Agricole s’engage dans un projet Big Data pour gérer des transactions à grande échelle
Face aux nouveaux enjeux des paiements électroniques et de l’Open Banking, le crédit agricole CIB a lancé un vaste projet pour disposer d’un système de messagerie hautes performances basé sur de multiples briques Open Source, le projet CMT, en s’appuyant sur les technologies d’Hortonworks.
Créé le 1er janvier 2019, CA-GIP (Crédit Agricole Group Infrastructure Platform) est l’entité qui gère aujourd’hui environ 80 % des infrastructures informatiques du groupe Crédit Agricole. Celle-ci compte environ 1 500 personnes réparties sur 17 sites en France et regroupe la production informatique de Crédit Agricole Assurances, Crédit Agricole CIB, Crédit Agricole Technologies et Services ainsi que les datacenters de SILCA.
La force de frappe de CA-GIP (pôle CA-CIB) dans le Big Data consiste en une cellule d’une quinzaine de personnes réparties entre Singapour et Paris. En termes d’infrastructure technique, celle-ci dispose de 8 Po de capacités de stockage et peut s’appuyer sur une puissance de traitement de 4 000 cœurs de calcul et 36 To de RAM.
La cellule intervient sur divers projets du groupe dont la gestion du risque avec une plateforme Big Data purement analytique et décisionnelle, des projets liés aux réglementations MIFID II et FRTB, des projets dont l’approche est purement décisionnelle avec des cubes OLAP.
CMT, un système de messagerie haute performances pour le Crédit Agricole
Néanmoins, beaucoup de ressources de CA-GIP sont aujourd’hui engagées dans un des plus grands chantiers IT lancés par la banque ces dernières années, le programme CMT (pour Cash Management Transformation). S’il s’agit d’un projet Big Data, il ne s’agit pas ici de stocker et d’analyser des données, mais bien d’assurer des transferts de données de paiement à grande échelle puisque l’objectif à terme est de traiter 800 millions de transactions par jour, soit un volume de données de 8 To/jour. Initié en 2016, ce projet a été déployé à l’échelle internationale et près d’une centaine de développeurs/product managers/projet managers et architectes sont impliqués dans ce projet. La plateforme dédiée à CMT mobilise actuellement 1 Po de stockage, 6 To de RAM et 336 cœurs de calcul.
« Le projet CMT est un projet purement transactionnel dont l’architecture repose sur du streaming de données. »
Mehdi Ben AissaResponsable infrastructure Big Data, CA-CIB
Mehdi Ben Aissa, responsable de l’infrastructure Big Data pour CA-CIB livre quelques détails sur la plateforme mise en place : « le projet CMT est un projet purement transactionnel dont l’architecture repose sur du streaming de données. Pour constituer l’architecture, nous avons pris toutes les technologies de la stack Hortonworks Data Platform (HDP) et Hortonworks DataFlow (HDF) à terme afin de constituer notre offre de services. Ce portefeuille inclut des briques d’intégration de données, le volet messagerie, le stockage, les traitements en batch ou micro-batch, des bases NoSQL ou encore de l’OLAP, de l’indexing avec Elastic Search qui est une offre que nous avons décidé de proposer dans notre catalogue de services. S’ajoutent enfin à cette liste des technologies d’administration et de monitoring et de sécurité de type Kerberos, Ranger, etc. »
CMT étant une application transactionnelle par nature, son fonctionnement repose sur le bus de message qui va intégrer l’ensemble des transactions qui arrivent en tant qu’événements dans une pure logique Event Processing. Lorsque les événements arrivent via le bus, des moteurs de streaming de micro-batch ou d’Event Processing vont traiter ces transactions. Deux moteurs de traitement sont mis en œuvre dans cette architecture : Spark Streaming pour ce qui est des micro-batchs et Storm pour faire du vrai Event Processing, lorsqu’il s’agit d’obtenir les plus faibles temps de latence. « Pour ce projet, nous n’utilisons pas encore Nifi mais des jobs maison développés sur Spark ou Storm. Le temps de latence sous Storm est inférieur à la seconde » précise l’expert.
Objectif numéro 1 : s’assurer du bon traitement de l’ensemble des transactions
Plusieurs autres composants entrent en jeu dans le traitement des événements : la couche de stockage de l’historique s’appuie sur HDFS, Hive et différentes solutions de stockage comme Parquet afin de stocker l’historique des événements traités. La brique State backend exploite Apache Ignite pour sauvegarder l’état des événements tandis que la partie Serving Layer s’appuie sur Apache HBase.
Le rôle de cette couche est capital dans l’infrastructure de CMT : « le point le plus critique de l’architecture est l’aspect “Exactly Once Semantics”. Comme il s’agit d’un système transactionnel, il était nécessaire de se soucier du volet “Exactly Once”, c’est à dire s’assurer que chaque transaction doit être traitée exactement une fois. En effet, nous avons découvert qu’il était pratiquement impossible d’éviter d’avoir des duplicats sur le bus de message, soit à cause de la source, soit à cause des injecteurs et des problématiques de multiphase commit. »
Mehdi Ben Aissa rajoute : « Pour parvenir à régler ce problème, nous avions le choix entre deux architectures. La première, ’Exactly Once Semantic sur l’ensemble de la chaine. "C’est ce qui nous a poussés à faire de la déduplication via un moteur de Processing en stateful accompagné d’une Serving layer transactionnelle."
« C’est une architecture assez complexe car il nous fallait un moteur d’exécution de type “stateful”, or la technologie actuellement la plus robuste, Apache Flink, n’était pas dans la stack Hortonworks. De même, il a été compliqué de trouver une couche de service transactionnelle car Apache Phoenix ou Apache Tephra ne sont pas aujourd’hui des solutions validées en production par rapport à nos SLAs. »
La deuxième solution qui s’offrait était plus simple : "il s’agissait d’assurer le “At Least Once Semantic” au niveau du bus de messages et de la couche Processing en s’appuyant sur un une Serving layer idempotente effectuant une déduplication des données by design. Cette couche logicielle s’appuie sur HBase et elle permet d’obtenir la garantie qu’une seule occurrence de chaque transaction est bien traitée par l’architecture."
L’expert reconnaît que cette couche HBase vient un peu dégrader les performances de l’ensemble car HBase est plus lourd que Kafka et vient ajouter des traitements supplémentaires, mais il estime que ce surcoût reste acceptable et que cette couche pourra monter en charge sans difficulté, HBase étant réputé pour sa « scalabilité ».
En termes de sécurité, l’équipe est restée dans les standards prônés par Hortonworks à savoir une authentification Kerberos et une gestion des autorisations et de l'audit avec Ranger.
CA-GIP a industrialisé le déploiement d’une plateforme très complexe
Autre écueil inhérent à des projets Big Data de cette ampleur, le déploiement d’une architecture aussi complexe sur les différents environnements comme le souligne Serge Alexandre, Architecte et Expert technique Big Data DevOps chez Finaxys : « l’application CMT est composée d’une dizaine d’applications qui interagissent entre-elles. Nous avons dû faire face au problème de déployer cette architecture sur les clusters de développement, d’intégration, de pré-production. C’est un problème, car on est face à de multiples composants qui sont configurés d’une façon qui leur est propre et disposent de sa propre gestion d’authentification et des autorisations. »
Si Apache Ranger apporte une solution centralisée de la sécurité des l’accès aux multiples briques d’un stack Hadoop, de multiples disparités perdurent dans la manière de gérer les autorisations de chacune de ces briques. Mettre à jour manuellement tous les composants d’une application Big Data peut rapidement tourner au cauchemar.
Autre problématique à gérer dans un projet de cette taille, la bonne communication entre Dev et Ops. « Les gens qui développent ne sont pas ceux qui exploitent, ou même ceux qui déploient en pre-prod » explique Serge Alexandre. « Il faut définir un langage commun, une description d’application sur laquelle les Dev et les Ops s’accordent entres eux. Les Ops ont besoin de connaitre les différentes composantes de l’application. De plus, il faut être capable d’automatiser le déploiement car dans le cadre de DevOps les déploiements sont très fréquents. »
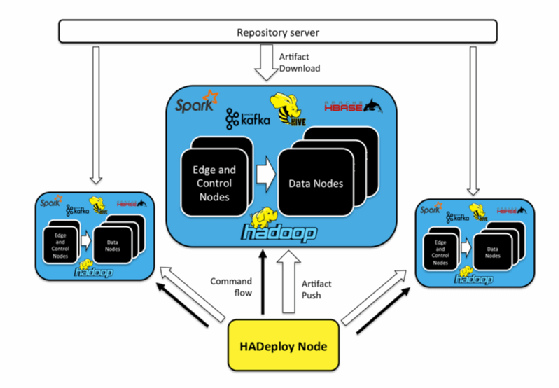
Architecture HADeploy, Crédit Agricole
Avec HADeploy, CA-GIP a développé une solution qui vient industrialiser le déploiement de telles architectures logicielles complexes en d’appuyant sur un formalisme de définition des clusters relativement simple. La solution analyse un fichier texte décrivant dans le détail l’infrastructure cible et génère les clusters de manière automatisée.
« Passer d’un mode procédural à un mode déclaratif est une grande simplification dans la manière dont on va définir l’application et ce mode déclaratif est bâti sur un principe de réconciliation avec, d’un côté l’état des clusters tels qu’ils sont, et de l’autre la cible à atteindre. Le système va faire en sorte de réconcilier les 2. » Disponible sur GitHub, HADeploy a été publié sous licence GPL mais n’est actuellement disponible que pour la distribution Hortonworks HDP.