Comment Tina a assuré le sauvetage des données RH de l’État
Le système de sauvegarde des données RH de l’État a pu démontrer son efficacité en grandeur nature. Après un incident de production, il a permis de récupérer près de 145 000 fichiers malencontreusement effacés suite à une mise à jour. Cette infrastructure de sauvegarde assure aussi le PRA de ces données ultra-sensibles.
Rattaché à la Direction générale de l’Administration et de la Fonction publique, à la Direction générale des Finances publiques et à la Direction du Budget, le CISIRH (Centre Interministériel de Services Informatiques relatifs aux Ressources Humaines) a pour mission de proposer aux services de l’État des systèmes RH dits « convergents ». Parmi ceux-ci, on peut citer RenoiRH, basé sur HR Access Suite 9, Ingres ou encore le CTDSN.
Au total, ces systèmes hébergent les dossiers de 358 000 agents et ils génèrent la déclaration mensuelle DSN (Déclaration Sociale Nominative) de 2,3 millions de fonctionnaires. La production et le PRA de ces applications sont assurés dans les datacenters du MINEFI, interconnectés par le Réseau Interministériel de l’État (RIE). La sauvegarde de ces données hautement critiques est assurée par le logiciel de sauvegarde Tina, de l’éditeur français Atempo.
Des données hautement critiques à protéger absolument
Créé en 2015, le CISIRH compte aujourd’hui 150 agents, dont une trentaine en charge de l’IT. Par la nature de ce service, ces agents gèrent des données extrêmement critiques pour le bon fonctionnement de l’État, d’où la mise en place, dès le départ, d’une solution de sauvegarde.
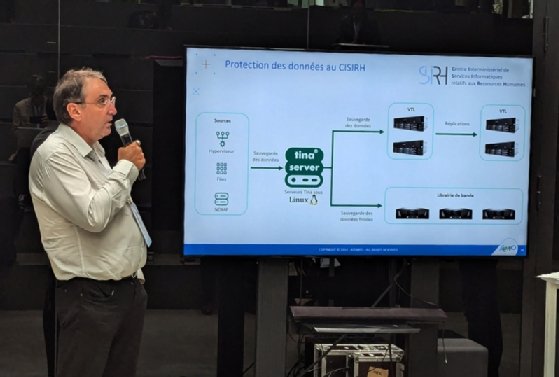
Cette architecture repose sur Tina de l’éditeur Atempo. Les serveurs Tina, sous Linux, assurent la sauvegarde des données des serveurs de fichiers (filers), des machines virtuelles, et des bases de données Oracle Hexadata.
Les données de production des filers Hitachi HNAS sont sauvegardées au travers du module NDMP de Tina. Un couple de VTL (Virtual Tape Librairies) Quantum DXi, réparti sur deux sites, permet la mise en œuvre d’une réplication externalisée pour accroître la résilience de l’ensemble.
Les données froides sont pour leur part sauvegardées sur des librairies de bandes LTO7 robotisées de marque Quantum.
Aujourd’hui, l’ensemble de ces données représente de l’ordre de 1 Po de données sauvegardées. L’architecture complète met en œuvre 3 VTL Quantum DXi 9000, disposant de 250 To d’espace dédupliqué. Un premier est exploité en production, un deuxième est dédié aux équipes projets et le troisième est mis en œuvre dans le cadre du PRA (trois robots Quantum I6 avec 6 lecteurs LTO7 pour la production et les projets et trois lecteurs LTO7 en PRA). En outre, deux serveurs de sauvegarde Dell sont en place sur chaque site.
Droit de réponse
Le Centre Interministériel de Services Informatiques relatifs aux Ressources Humaines a souhaité apporter les compléments suivants à cet article :
« Les propos du collaborateur du CISIRH, sans être factuellement erronés, doivent être tempérés. En effet, le CISIRH gère une partie des données RH de ses partenaires ministériels via les systèmes d’information qu’il opère ; il ne gère pas l’ensemble des données RH de l’État, contrairement à ce que la phrase d’accroche de l’article laisse entendre. En outre, les fichiers purgés par erreur étaient des comptes-rendus techniques de traitements batch. À aucun moment, les données personnelles des agents n’ont été manquantes ou altérées. Outre les outils techniques évoqués dans l’article, le CISIRH a mis en place une stratégie de gestion de la sécurité des données à caractère personnel qui lui a permis d’obtenir la certification ISO27001, gage de confiance vis-à-vis de ses partenaires ministériels ».
Les volumes de données sauvegardées n’ont cessé de croître d’année en année. Et cette infrastructure a récemment été sollicitée de manière intensive suite à un incident de production.
Jérôme Marie, ingénieur stockage et sauvegarde à la CISIRH, raconte : « Nous avons eu un souci : au bout de huit jours, nous nous sommes rendu compte qu’une mise à jour logicielle avait malheureusement modifié un script de purge. Celui-ci effaçait beaucoup plus de fichiers qu’à l’ordinaire. »
Pendant une grosse semaine, ce script a méticuleusement effacé des dizaines de milliers de fichiers. (En analysant les logs, l’équipe de production en a décompté pas moins de 145 000 !) Une particularité de cet effacement accidentel est qu’il était réparti sur toute une semaine et qu’il ne touchait pas tous les fichiers sur une période donnée, mais seulement certains d’entre eux.
L'Architecture de sauvegarde du CISIRH présentée par Jérôme Marie, ingénieur stockage, lors des Universités d’été d’Hexatrust 2024.
37 heures de traitement pour restaurer 144 700 fichiers
Pour restaurer ces fichiers, Jérôme Marie va mettre en œuvre la fonction de navigation temporelle du logiciel Tina.
« Nous avons pu générer une liste de fichiers à restaurer en nous appuyant sur la fonction de profondeur de champ qui est l’une des fonctionnalités de la solution, afin de faire une navigation temporelle dans les données de Tina. Cela nous a permis de réaliser la restauration en une seule commande. »
L’atout des sauvegardes réalisées par l’outil, c’est que seules les dernières versions de chaque fichier sont sauvegardées. L’équipe de production avait donc la certitude de ne remonter que la version la plus récente de chaque fichier.
« Nous utilisons un jeu de cartouche dont la durée de rétention est de 2 mois. Comme nous avons pris conscience de l’incident au bout de 8 jours, nous avons pu utiliser la fonction de profondeur de champ du logiciel sur 8 jours », ajoute l’ingénieur. « Nous avons demandé au logiciel de fouiller les sauvegardes de ces huit derniers jours. Tina va chercher des objets et, pour chacun d’eux, des instances lui sont associées sur les cartouches. »
Le logiciel a dû calculer les 144 700 occurrences en parcourant sa base de métadonnées et construire le mécanisme de lecture des différentes bandes étagées sur une semaine complète. Le processus de restauration lui-même a demandé 37 heures de traitement, mais la restauration a été complète et sans aucune erreur.
Si Jérôme Marie était plutôt serein quant à la restauration d’autant de fichiers depuis les cartouches virtuelles, la longueur du traitement et les énormes volumes de mémoire nécessaires au mécanisme DAR (Direct Access Recovery) ont mis à l’épreuve la fiabilité du logiciel Tina.
Jérôme Marie précise le fonctionnement de cette fonction disponible sur certains systèmes NDMP (Network Data Management Protocol) : « La fonction DAR permet un accès direct à l’emplacement du fichier sur le fichier-bande (partition logique de la bande), plutôt que d’imposer une lecture complète de celui-ci pour en extraire plus rapidement la donnée. Ce mécanisme impose de stocker en mémoire l’ensemble des données/métadonnées utiles pour construire le scénario de la restauration, à savoir la position de chaque fichier sur la bande, l’ordre des lectures des bandes, l’ordre de lecture pour chaque fichier sans retour arrière sur la bande. »
Enfin, il faut effectuer le calcul des sauts de blocs entre chaque fichier. Tous ces éléments expliquent pourquoi il a fallu 37 heures pour mener à bien la restauration de ces 145 000 fichiers.
Le catalogue des données du PRA mis à jour quotidiennement
Cet épisode a en tout cas renforcé la confiance dans Tina.
« Les données elles-mêmes sont répliquées au travers de la réplication des VTL, ce qui permet un accès direct aux cartouches de la production en lecture seule. »
Jérôme MarieIngénieur stockage et sauvegarde, CISIRH
L’outil réalise aujourd’hui les sauvegardes sur ses différents sites d’exploitation, mais il est aussi mis en œuvre dans le cadre d’un PRA automatisé. Toutes les données sauvegardées peuvent être restaurées sur un site de PRA distant ; toutes les métadonnées peuvent être restaurées, ainsi que certaines données de manière automatique.
« Tous les matins, les catalogues de sauvegarde Time Navigator [N.D.R. : métadonnées et configuration] sont exportés en production, puis répliqués sur le site de PRA. Les catalogues sont réimportés sur les serveurs de sauvegarde du site PRA avec une adaptation des noms de serveurs effectuée automatiquement via le mode commande et des scripts utilisant l’API de Tina », explique Jérôme Marie. « Les données elles-mêmes sont répliquées au travers de la réplication des VTL, ce qui permet un accès direct aux cartouches de la production en lecture seule. »
Les données de production sont ainsi disponibles tous les matins à la fin de l’opération et certaines sont restaurées automatiquement tous les jours pour approvisionner des environnements de tests. Le tout permet de valider la cohérence des données répliquées en plus de l’exercice complet réalisé chaque année. Le CISIRH a reçu sa certification ISO 27001 il y a un an.