U-SQL
Langage de requête de Microsoft, U-SQL se caractérise par la combinaison d'une syntaxe déclarative de type SQL et de la capacité de programmation de C#. Il est essentiellement conçu pour le traitement des données structurées et non structurées des environnements Big Data. Présenté en 2015, U-SQL est un composant du service Cloud Azure Data Lake Analytics de Microsoft, mais le langage permet aussi aux utilisateurs de lancer des requêtes sur plusieurs magasins de données du Cloud Azure.
SQL est le langage standard utilisé pour l'interrogation des bases de données, alors que C# (dit « C-sharp ») est un langage de programmation développé par Microsoft. Le géant de Redmond les a combinés pour créer U-SQL suite à l'émergence des systèmes Big Data qui, souvent, stockent des données non structurées susceptibles de poser des difficultés aux langages SQL et de programmation procédurale. U-SQL a été conçu pour unifier les deux approches en assurant en natif l'extensibilité du code C# écrit par l'utilisateur dans une implémentation SQL.
Capacités d'U-SQL
U-SQL trouve ses racines dans le langage de script déclaratif et extensif, nommé SCOPE, que Microsoft utilise en interne. Dans une étude de 2008, la société déclarait avoir développé SCOPE (Structured Computations Optimized for Parallel Execution - Calculs structurés optimisés pour l'exécution parallèle) pour permettre aux analystes de données connaissant SQL de lancer des requêtes sur des journaux de recherche, des parcours de navigation sur Internet et autres jeux de données volumineux stockés de plus en plus dans les plateformes distribuées comme Hadoop, plutôt que dans des bases de données relationnelles SQL.
L'intégration entre SQL et C# réalisée dans U-SQL s'appuie sur SCOPE, qui sert de framework d'exécution et d'optimisation des requêtes d'U-SQL. Le système de métadonnées, la syntaxe SQL et la sémantique du langage U-SQL sont modélisés d'après l'ANSI SQL standard et Transact-SQL, implémentation de Microsoft du langage de requête pour sa base de données SQL Server. Toutefois, U-SQL n'adhère pas totalement à l'ANSI SQL. Par exemple, des commandes comme SELECT doivent être écrites en lettres majuscules et la syntaxe C# est utilisée pour les expressions intégrées aux commandes.
Microsoft explique qu'U-SQL permet aux utilisateurs de traiter n'importe quel type de données, à n'importe quelle échelle. Le langage redimensionne automatiquement les requêtes de façon à utiliser les ressources système disponibles. Il permet aux utilisateurs de se concentrer sur les données, plutôt que de s'occuper des besoins d'infrastructure ou d'écrire ce que Microsoft appelle du « code générique ».
En tant que composant de la plateforme Azure Data Lake de Microsoft, U-SQL est le langage intégré d'analyse des jeux de données d'Azure Data Lake Store, qui est couplé au service analytique pour fournir un environnement de data lake dans le cloud. U-SQL peut également servir à exécuter des requêtes sur des magasins de données relationnels comme Azure SQL Database, la version cloud de SQL Server, ainsi qu'Azure SQL Data Warehouse, Azure Blob Storage et les instances SQL Server définies dans les machines virtuelles Azure.
Comment utiliser U-SQL ?
Le code U-SQL s'écrit sous forme de scripts composés d'une séquence d'instructions correspondant aux traitements à réaliser. Jusqu'à présent, le service Azure Data Lake Analytics ne prend en charge, via U-SQL, que les travaux en traitement par lots. Par conséquent, les requêtes ne peuvent pas renvoyer directement les résultats. D'après Microsoft, les scripts U-SQL prévoient généralement de récupérer les données de systèmes source sous forme d'ensembles de lignes, les transforment en fonction des besoins, puis génèrent un fichier de sortie ou une table U-SQL avec les données transformées en vue de leur analyse.
Pour traiter des ensembles de données non structurées dans un data lake, les utilisateurs d'U-SQL peuvent appliquer un schéma lors de la lecture, ce qui est une approche courante dans les systèmes Big Data et évite d'avoir à se conformer à un schéma rigide, comme le font les bases de données relationnelles. Il est également possible d'intégrer aux scripts une logique de traitement personnalisée et toute une série de fonctions, de types, d'agrégats et d'objets définis par l'utilisateur (extracteurs, processeurs et générateurs de sortie, par exemple).
L'image ci-dessous montre un exemple simple de script U-SQL de Microsoft. Dans ce cas, le script n'inclut aucune transformation des données. Il extrait les données d'un fichier source de journal de recherche, applique un schéma et écrit l'ensemble de lignes qui en résulte dans un fichier CSV :
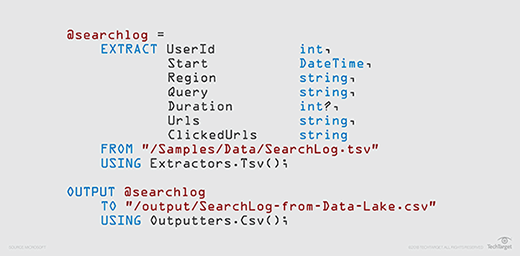
Il est possible d'écrire des scripts U-SQL et de les soumettre au service Azure Data Lake Analytics en vue de leur exécution dans Visual Studio 2017 à l'aide d'un module complémentaire nommé Azure Stream Analytics Tools. Il existe également une extension U-SQL pour Visual Studio Code, éditeur de code allégé développé par Microsoft, dont le nom est simplement Azure Data Lake Tools. En outre, les utilisateurs peuvent exécuter des travaux U-SQL dans Azure Data Lake Analytics via le portail Azure, l'interface de ligne de commande (CLI) Azure ou Azure Powershell
Les autres magasins de données interrogés par le biais d'U-SQL sont considérés comme des sources de données externes. Dans ce cas, les utilisateurs doivent exécuter des requêtes groupées, processus qui consiste à créer des objets de sources de données dans U-SQL pour s'affranchir du mode de connexion utilisé pour un magasin particulier et transposer et exécuter les requêtes vers son propre moteur de requête.
En donnant la possibilité d'intégrer du code C# dans des scripts U-SQL, Microsoft permet aux utilisateurs d'exprimer des algorithmes métier complexes au sein des requêtes. Aux dires de la société, les types C# étant utilisés comme style de codage par défaut, les utilisateurs visualisent facilement la façon de traiter les données lors de l'écriture des requêtes.
Pour approfondir sur Base de données
-
![]()
Snowflake veut lui aussi faire de PostgreSQL un lakehouse ouvert
Par: Gaétan Raoul
-
![]()
Fabric : face à Snowflake et Databricks, Microsoft met les bouchées doubles
Par: Gaétan Raoul
-
![]()
Fabric : Microsoft tient la dragée haute à Snowflake et Databricks
Par: Gaétan Raoul
-
![]()
Teradata décline VantageCloud Lake sur Azure
Par: Gaétan Raoul


