Tiering de données
Ce que l’on appelle tiering de données ou de stockage est l'activité qui consiste à positionner des données sur la classe de stockage qui répond le mieux à leurs besoins tout au long de leur cycle de vie, dans le but de réduire les coûts et d’améliorer les performances. Les critères de classements peuvent se faire selon des paramètres de niveau de protection, de performance, de fréquence d’utilisation, d’âge des données…
Historiquement le « storage Tiering » était lié aux concepts de HSM (Hierarchical Storage Management) et d’ILM (Information Lifecycle Management) et permettait de déplacer des données entre des systèmes de stockage présentant des caractéristiques de performance et de coût au Gigaoctet différentes. Par exemple, on assignait à un système de stockage Fibre Channel hautes performances équipés de disques SAS rapides, une classe 1, tandis qu’un système à base de disques SAS nearline ou de disques SATA était considéré comme un système de classe 2 et une librairie de bande comme un système de classe 3. Et Cela avait par exemple du sens de déplacer des données vieillissantes et peu utilisées d’un système performant vers un autre système moins performant et surtout moins coûteux, afin de maximiser l’espace disponible sur les systèmes de stockage performant pour les données les plus critiques. Éventuellement, il était aussi possible de rebasculer des données dormantes d’un système à bas coût vers un système performant en cas de besoin ponctuel de traitement sur ces données.
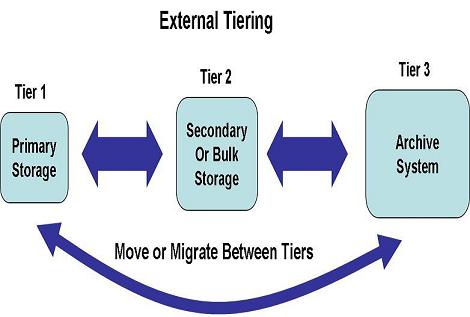 Principe de fonctionnement du tiering de données externe
Principe de fonctionnement du tiering de données externe
Depuis, le sens du tiering de stockage a évolué et désigne plutôt la capacité d’une baie de stockage à gérer dynamiquement le positionnement des données sur des classes de disques différentes en fonction de politiques définies par l’administrateur. Dans une baie de disque, l’étage de disque Flash est ainsi vu comme un étage de classe 0, tandis que les disques SAS rapide sont une classe 1, les disques SAS NL une classe 2 et les disques SATA une classe 3. Et les baies modernes sont capables de déplacer automatiquement les données d’une classe à l’autre en fonction de la fréquence et des typologies d’accès (aléatoires ou séquentiels), de l’âge des données…
Ce mécanisme de tiering automatisé a plusieurs avantages. Il permet tout d’abord de maximiser le rapport performances/prix de la baie, mais aussi d’alléger la charge de travail des administrateurs, qui n’ont plus à gérer à la main les mouvements de données. Notons que les mécanismes de tiering ont des noms différents selon les constructeurs, Fast chez EMC, Easy Tiering chez IBM, Data Progression chez Dell, Adaptive Optimization chez HP ou Dynamic Tiering chez Hitachi Data Systems…
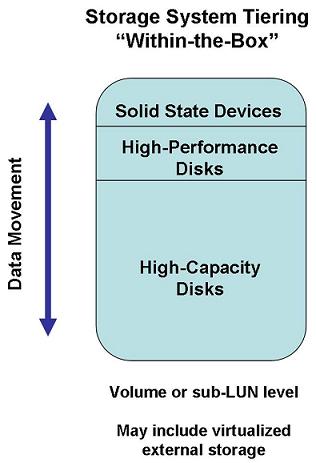 Principe du tiering de données interne
Principe du tiering de données interne
En savoir plus Tiering de données
Pour approfondir sur SAN et NAS
-
![]()
Comment les Maîtres Laitiers du Cotentin affinent leur stockage avec l’auto-tiering de DataCore
Par: Alain Clapaud
-
![]()
Hedvig ajoute le tiering Flash et le chiffrement à la version 3.0 de son logiciel de stockage
Par: Christophe Bardy
-
![]()
DDN dope son offre de stockage Exascaler
Par: Christophe Bardy
-
![]()
Scale Computing dope son offre hyperconvergée PME à la Flash
Par: Christophe Bardy



