Réseau de neurones artificiels (RNA)
Dans le domaine des technologies de l'information, un réseau de neurones est un système logiciel et / ou matériel qui imite le fonctionnement des neurones biologiques. Les réseaux neuronaux, aussi appelés réseaux de neurones artificiels (RNA ou ANN en anglais), font partie des technologies d'apprentissage profond (ou « deep learning »), couvertes également par l'intelligence artificielle (IA).
Les applications commerciales sont souvent axées sur la résolution de problèmes complexes de traitement de signaux ou de reconnaissance de modèles. Parmi les exemples les plus connus depuis 2000, on trouve la reconnaissance de l'écriture manuscrite pour le traitement des chèques, la conversion de parole en texte, l'analyse des données d'exploration pétrolière, les prévisions météorologiques et la reconnaissance faciale.
Fonctionnement des réseaux de neurones artificiels
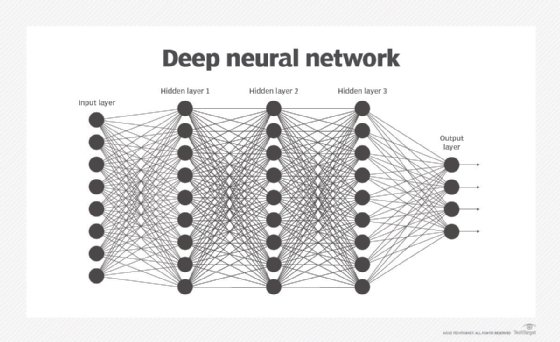
Un réseau neuronal sous-entend normalement qu'un grand nombre de processeurs fonctionne en parallèle et en couches successives. La première couche reçoit en entrée les informations brutes, à la manière du nerf optique qui traite les données visuelles humaines. Chaque couche successive reçoit les données de la couche précédente plutôt que les données brutes, tout comme les neurones éloignés du nerf optique reçoivent les signaux des neurones voisins. La dernière couche produit le résultat.
Chaque noeud de traitement a sa petite bulle de connaissances, composée notamment de ce qu'il a vu et des règles programmées à l'origine ou définies par lui-même. Les couches sont étroitement interconnectées : chaque nœud d'une couche n est connecté à de nombreux noeuds de la couche n-1 (ses entrées) et de la couche n+1 qui seront à leur tour les entrées de ces noeuds-là. Il peut y avoir un ou plusieurs noeuds dans la couche de sortie dont provient la réponse lisible.
Les réseaux neuronaux sont remarquables par leur capacité d'adaptation : ils se modifient eux-mêmes en fonction de l'entraînement initial et les exécutions suivantes leur apportent encore plus d'informations sur le monde qui les entourent. Le modèle d'apprentissage le plus élémentaire est axé sur la pondération des flux d'entrée, autrement dit sur l'évaluation par chaque noeud de l'importance des entrées provenant de chacun de ses prédécesseurs. Les entrées qui contribuent à mener aux bonnes réponses ont un coefficient plus fort.
Apprentissage des réseaux neuronaux
Normalement, un réseau neuronal passe d'abord par une phase d'apprentissage, ou bien est alimenté par des données en nombre. L'entraînement consiste à lui fournir des données en entrée et à lui donner le résultat attendu. Par exemple, pour bâtir un réseau qui reconnaisse les visages d'acteurs, l'entraînement initial peut consister en une série de photographies de comédiens, de non-comédiens, de masques, de statues, de gueules d'animaux, etc. Chaque entrée est accompagnée de l'identification correspondante : le nom de l'acteur, la mention « non-acteur » ou « non-humain ». Grâce aux réponses fournies, le modèle ajuste ses pondérations internes pour apprendre à mieux faire son travail.
Prenons un exemple. Les noeuds David, Dianne et Dakota indiquent au noeud Ernie que l'image actuelle est une photo de Brad Pitt, mais le noeud Durango affirme qu'il s'agit de Betty White. Le programme d'entraînement confirme qu'il s'agit de l'acteur. Ernie va alors réduire le coefficient affecté aux entrées de Durango et augmenter ceux de David, Dianne et Dakota.
Pour définir les règles et prendre des décisions, c'est-à-dire décider de ce qu'il faut envoyer à la couche suivante d'après les entrées reçues de la précédente, les réseaux neuronaux suivent plusieurs principes, notamment l'apprentissage à base d'algorithme du gradient, la logique floue (ou « fuzzy logic »), les algorithmes génétiques et les méthodes bayésiennes. On peut leur donner quelques règles élémentaires sur les relations des objets dans l'espace en cours de modélisation.
Par exemple, un système de reconnaissance faciale peut recevoir les instructions : « les sourcils se trouvent au-dessus des yeux » ou « les moustaches se trouvent au-dessous du nez. Les moustaches se trouvent au-dessus et / ou sur les côtés de la bouche ». Le préchargement des règles accélère l'entraînement et produit plus rapidement un modèle plus puissant. Mais ce faisant, on intègre des hypothèses sur la nature des limites du problème, qui peuvent être non pertinentes, inutiles voire contre-productives : la décision quant aux règles à inclure, voire à leur inclusion elle-même, en est d'autant plus importante.

peuvent amplifier les préjugés / la partialité.
De plus, les hypothèses avancées par ceux qui entraînent les algorithmes risquent de créer des réseaux neuronaux qui amplifient les préjugés culturels. Les ensembles de données subjectifs représentent un défi permanent lors de l'entraînement des systèmes qui trouvent eux-mêmes les réponses d'après les modèles extraits des données. Si les données en entrée de l'algorithme ne sont pas neutres, et presque aucune donnée ne l'est, la machine va propager des préjugés.
Types de réseaux neuronaux
On parle parfois de la profondeur des réseaux neuronaux, jusqu'à donner le nombre de couches séparant l'entrée de la sortie ou de couches dites cachées du modèle. C'est pourquoi le terme réseau neuronal ou de neurones s'emploie comme quasi-synonyme d'apprentissage profond. On s'y réfère aussi par le nombre de noeuds cachés du modèle ou d'entrées et de sorties de chaque noeud. Des variantes du réseau neuronal classique permettent diverses formes de propagation des informations entre les couches, vers l'amont et vers l'aval.
De plus, les hypothèses avancées par ceux qui entraînent les algorithmes risquent de créer des réseaux neuronaux qui amplifient les préjugés culturels. Les ensembles de données subjectifs représentent un défi permanent lors de l'entraînement des systèmes qui trouvent eux-mêmes les réponses d'après les modèles extraits des données. Si les données en entrée de l'algorithme ne sont pas neutres, et presque aucune donnée ne l'est, la machine va propager des préjugés. Types de réseaux neuronaux On parle parfois de la profondeur des réseaux neuronaux, jusqu'à donner le nombre de couches séparant l'entrée de la sortie ou de couches dites cachées du modèle. C'est pourquoi le terme réseau neuronal ou de neurones s'emploie comme quasi-synonyme d'apprentissage profond. On s'y réfère aussi par le nombre de noeuds cachés du modèle ou d'entrées et de sorties de chaque noeud. Des variantes du réseau neuronal classique permettent diverses formes de propagation des informations entre les couches, vers l'amont et vers l'aval.
Cette vidéo montre la façon dont les réseaux neuronaux
traitent les données et les prévisions qui en découlent.
La variante la plus simple est le réseau neuronal à propagation avant (ou acyclique). Ce type d'algorithme de réseau de neurones artificiels fait passer directement les informations en entrée des noeuds de traitement vers les sorties. Il peut y avoir ou non des couches de noeuds cachées qui facilitent encore l'interprétation de leur fonctionnement.
Les réseaux neuronaux récurrents sont plus complexes. Ces algorithmes d'apprentissage profond enregistrent la sortie des noeuds de traitement et la réinjectent dans le modèle. On dit que le modèle apprend.
Les réseaux neuronaux convolutifs ou à convolution sont courants aujourd'hui, surtout dans le domaine de la reconnaissance d'images. Ce type particulier d'algorithme est utilisé dans la plupart des applications d'IA les plus sophistiquées, entre autres la reconnaissance faciale, la numérisation de textes et le traitement automatique des langues.
Applications des réseaux de neurones artificiels
La reconnaissance d'images est l'un des premiers domaines d'application réussie des réseaux neuronaux, mais la technologie s'est étendue à bien d'autres, à savoir :
- les chatbots,
- le traitement automatique des langues, la traduction et la génération automatique de textes en langue naturelle,
- les prévisions boursières,
- la planification et l'optimisation des tournées de livraison,
- la découverte et l'élaboration de médicaments.
Il ne s'agit que de quelques domaines particuliers auxquels s'appliquent aujourd'hui les réseaux neuronaux. Les principaux usages concernent tout traitement qui suit des règles ou des modèles stricts, et dispose de volumes considérables de données. Si le volume de données est trop grand pour qu'une personne l'appréhende dans un laps de temps raisonnable, l'opération se prête parfaitement à l'automatisation par les réseaux de neurones artificiels.
Historique des réseaux neuronaux
Les réseaux de neurones artificiels remontent au tout début de l'informatique. En 1943, les mathématiciens Warren McCulloch et Walter Pitts construisent un système de circuits qui exécute des algorithmes simples pour imiter le fonctionnement du cerveau.
En 1957, le chercheur Frank Rosenblatt de l'université Cornell développe le perceptron, un algorithme de reconnaissance avancée de modèles qui ouvre la voie à la reconnaissance d'objets dans les images par les machines. Le perceptron n'ayant pas répondu aux attentes, les chercheurs ont délaissé les réseaux de neurones artificiels au cours des années 1960.
Marvin Minsky parle avec Seymour Papert
de ses travaux sur les réseaux neuronaux.
En 1969, les chercheurs Marvin Minsky et Seymour Papert du MIT publient le livre Perceptrons, qui aborde différentes problématiques des réseaux neuronaux, notamment le manque de puissance des ordinateurs de l'époque empêchant de traiter les données nécessaires au fonctionnement normal des réseaux neuronaux. Pour beaucoup, ce livre est responsable de l'hiver prolongé de l'IA, une ère qui se caractérise par l'arrêt des recherches dans le domaine des réseaux neuronaux.
Ce n'est qu'en 2010 que la recherche a repris. L'émergence des Big Data, ces volumes colossaux de données qu'amassent les entreprises, et le traitement informatique parallèle ont donné aux data-scientists les données d'entraînement et les ressources informatiques indispensables aux réseaux de neurones artificiels complexes. En 2012, un réseau de neurones a surpassé les performances humaines lors d'une tâche de reconnaissance d'images dans le cadre du concours ImageNet. Depuis lors, les réseaux de neurones artificiels suscitent l'engouement et la technologie ne cesse de s'améliorer.







