Machine Learning
L'apprentissage machine (ML) est un type d'intelligence artificielle (IA) axé sur la construction de systèmes informatiques qui apprennent à partir de données. Le large éventail de techniques qu'englobe l'apprentissage automatique permet aux applications logicielles d'améliorer leurs performances au fil du temps.
Les algorithmes d'apprentissage automatique sont formés pour trouver des relations et des modèles dans les données. Ils utilisent des données historiques pour faire des prédictions, classer des informations, regrouper des points de données, réduire la dimensionnalité et même aider à générer de nouveaux contenus, comme le démontrent les nouvelles applications alimentées par l'apprentissage automatique telles que ChatGPT, Dall-E 2 et GitHub Copilot.
L'apprentissage automatique est largement applicable dans de nombreux secteurs. Les moteurs de recommandation, par exemple, sont utilisés par le commerce électronique, les médias sociaux et les organismes d'information pour suggérer des contenus en fonction du comportement antérieur du client. Les algorithmes d'apprentissage automatique et la vision artificielle sont des éléments essentiels des voitures autonomes, qui les aident à sillonner les routes en toute sécurité. Dans le domaine de la santé, l'apprentissage automatique est utilisé pour diagnostiquer et suggérer des plans de traitement. D'autres cas d'utilisation courants de l'apprentissage automatique comprennent la détection des fraudes, le filtrage des spams, la détection des menaces de logiciels malveillants, la maintenance prédictive et l'automatisation des processus d'entreprise.
Si l'apprentissage automatique est un outil puissant pour résoudre les problèmes, améliorer les opérations des entreprises et automatiser les tâches, il s'agit également d'une technologie complexe et difficile, qui nécessite une expertise approfondie et des ressources importantes. Le choix de l'algorithme adéquat pour une tâche donnée nécessite de solides connaissances en mathématiques et en statistiques. La formation des algorithmes d'apprentissage automatique nécessite souvent de grandes quantités de données de bonne qualité pour produire des résultats précis. Les résultats eux-mêmes peuvent être difficiles à comprendre - en particulier les résultats produits par des algorithmes complexes, tels que les réseaux neuronaux d'apprentissage profond inspirés du cerveau humain. Enfin, les modèles d'apprentissage automatique peuvent être coûteux à exécuter et à mettre au point.
Pourtant, la plupart des organisations, soit directement, soit indirectement par le biais de produits infusés par la ML, adoptent l'apprentissage automatique. Selon le "2023 AI and Machine Learning Research Report" de Rackspace Technology, 72 % des entreprises interrogées ont déclaré que l'IA et l'apprentissage automatique faisaient partie de leurs stratégies informatiques et commerciales, et 69 % ont décrit l'IA/ML comme la technologie la plus importante. Les entreprises qui l'ont adoptée ont déclaré l'utiliser pour améliorer les processus existants (67 %), prédire les performances de l'entreprise et les tendances du secteur (60 %) et réduire les risques (53 %).
Le guide de l'apprentissage automatique de TechTarget est une introduction à ce domaine important de l'informatique, expliquant ce qu'est l'apprentissage automatique, comment le réaliser et comment il est appliqué dans les entreprises. Vous trouverez des informations sur les différents types d'algorithmes d'apprentissage automatique, les défis et les meilleures pratiques associés au développement et au déploiement de modèles d'apprentissage automatique, et ce que l'avenir réserve à l'apprentissage automatique. Tout au long du guide, des liens hypertextes renvoient à des articles connexes qui couvrent les sujets de manière plus approfondie.

Pourquoi l'apprentissage automatique est-il important ?
L'apprentissage automatique a joué un rôle de plus en plus central dans la société humaine depuis ses débuts au milieu du XXe siècle, lorsque des pionniers de l'IA comme Walter Pitts, Warren McCulloch, Alan Turing et John von Neumann ont jeté les bases de l'informatique. La formation de machines capables d'apprendre à partir de données et de s'améliorer au fil du temps a permis aux organisations d'automatiser des tâches routinières qui étaient auparavant effectuées par des humains, ce qui nous libère en principe pour un travail plus créatif et stratégique.
L'apprentissage automatique effectue également des tâches manuelles qui dépassent notre capacité d'exécution à grande échelle - par exemple, le traitement des énormes quantités de données générées aujourd'hui par les appareils numériques. La capacité de l'apprentissage automatique à extraire des modèles et des informations à partir de vastes ensembles de données est devenue un facteur de différenciation concurrentielle dans des domaines allant de la finance et du commerce de détail aux soins de santé et à la découverte scientifique. De nombreuses entreprises de premier plan, dont Facebook, Google et Uber, font de l'apprentissage automatique un élément central de leurs activités.
Alors que le volume de données générées par les sociétés modernes continue de proliférer, l'apprentissage automatique deviendra probablement encore plus vital pour les humains et essentiel pour l'intelligence artificielle elle-même. La technologie nous aide non seulement à donner un sens aux données que nous créons, mais en synergie, l'abondance des données que nous créons renforce encore les capacités d'apprentissage axé sur les données de l'apprentissage automatique.
Que va-t-il résulter de cette boucle d'apprentissage continu ? L'apprentissage automatique est une voie vers l'intelligence artificielle, qui à son tour alimente les progrès de l'apprentissage automatique qui améliorent également l'IA et brouillent progressivement les frontières entre l'intelligence de la machine et l'intelligence humaine.

Quels sont les différents types d'apprentissage automatique ?
L'apprentissage automatique classique est souvent classé en fonction de la manière dont un algorithme apprend à devenir plus précis dans ses prédictions. Il existe quatre types fondamentaux d'apprentissage automatique : l'apprentissage supervisé, l'apprentissage non supervisé, l'apprentissage semi-supervisé et l'apprentissage par renforcement.
Le type d'algorithme choisi par les scientifiques des données dépend de la nature des données. De nombreux algorithmes et techniques ne se limitent pas à un seul des principaux types de ML répertoriés ici. Ils sont souvent adaptés à plusieurs types, en fonction du problème à résoudre et de l'ensemble de données. Par exemple, les algorithmes d'apprentissage profond tels que les réseaux neuronaux convolutifs et les réseaux neuronaux récurrents sont utilisés dans des tâches d'apprentissage supervisé, non supervisé et de renforcement, en fonction du problème spécifique et de la disponibilité des données.
Apprentissage automatique et réseaux neuronaux d'apprentissage profond
L'apprentissage profond est un sous-domaine de l'intelligence artificielle qui traite spécifiquement des réseaux neuronaux contenant plusieurs niveaux, c'est-à-dire des réseaux neuronaux profonds. Les modèles d'apprentissage profond peuvent apprendre et extraire automatiquement des caractéristiques hiérarchiques des données, ce qui les rend efficaces dans des tâches telles que la reconnaissance d'images et de la parole.
Comment fonctionne l'apprentissage automatique supervisé ?
Dans l'apprentissage supervisé, les scientifiques fournissent aux algorithmes des données de formation étiquetées et définissent les variables qu'ils veulent que l'algorithme évalue pour les corrélations. L'entrée et la sortie de l'algorithme sont toutes deux spécifiées dans l'apprentissage supervisé. Au départ, la plupart des algorithmes d'apprentissage automatique fonctionnaient avec l'apprentissage supervisé, mais les approches non supervisées sont de plus en plus populaires.
Les algorithmes d'apprentissage supervisé sont utilisés pour plusieurs tâches, dont les suivantes :
- Classification binaire. Divise les données en deux catégories.
- Classification multi-classe. Permet de choisir entre plus de deux types de réponses.
- Assemblage. Combine les prédictions de plusieurs modèles ML pour produire une prédiction plus précise.
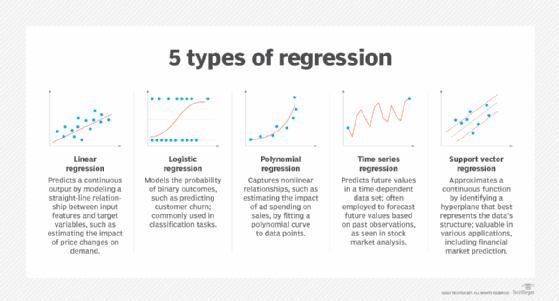
- Modélisation de la régression. Prévoit des valeurs continues sur la base de relations entre les données.
Comment fonctionne l'apprentissage automatique non supervisé ?
Les algorithmes d'apprentissage automatique non supervisés ne nécessitent pas que les données soient étiquetées. Ils passent au crible les données non étiquetées à la recherche de modèles qui peuvent être utilisés pour regrouper les points de données en sous-ensembles. La plupart des types d'apprentissage profond, y compris les réseaux neuronaux, sont des algorithmes non supervisés.
Les algorithmes d'apprentissage non supervisé conviennent aux tâches suivantes :
- Regroupement. Diviser l'ensemble des données en groupes sur la base de la similarité à l'aide d'algorithmes de regroupement.
- Détection d'anomalies. Identification de points de données inhabituels dans un ensemble de données à l'aide d'algorithmes de détection d'anomalies.
- Règle d'association. Découverte d'ensembles d'éléments dans un ensemble de données qui reviennent fréquemment ensemble à l'aide de l'extraction de règles d'association.
- Réduction de la dimensionnalité. Diminution du nombre de variables dans un ensemble de données à l'aide de techniques de réduction de la dimensionnalité.
Comment fonctionne l'apprentissage semi-supervisé ?
L'apprentissage semi-supervisé consiste à alimenter un algorithme avec une petite quantité de données de formation étiquetées. À partir de ces données, l'algorithme apprend les dimensions de l'ensemble de données, qu'il peut ensuite appliquer à de nouvelles données non étiquetées. Les performances des algorithmes s'améliorent généralement lorsqu'ils s'entraînent sur des ensembles de données étiquetées. Mais l'étiquetage des données peut être long et coûteux. Ce type d'apprentissage automatique trouve un équilibre entre les performances supérieures de l'apprentissage supervisé et l'efficacité de l'apprentissage non supervisé.
L'apprentissage semi-supervisé peut être utilisé dans les domaines suivants, entre autres :
- Traduction automatique. Apprend aux algorithmes à traduire une langue à partir d'un nombre de mots inférieur à celui d'un dictionnaire complet.
- Détection de la fraude. Identifie les cas de fraude lorsqu'il n'y a que quelques exemples positifs.
- Étiquetage des données. Les algorithmes formés sur de petits ensembles de données apprennent à appliquer automatiquement des étiquettes de données à des ensembles plus importants.
Comment fonctionne l'apprentissage par renforcement ?
L'apprentissage par renforcement consiste à programmer un algorithme avec un objectif distinct et un ensemble de règles prescrites pour atteindre cet objectif. Un scientifique des données programmera également l'algorithme pour qu'il recherche des récompenses positives lorsqu'il effectue une action bénéfique pour la réalisation de son objectif final et pour qu'il évite les punitions lorsqu'il effectue une action qui l'éloigne de son objectif.
L'apprentissage par renforcement est souvent utilisé dans les domaines suivants :
- Robotique. Les robots apprennent à effectuer des tâches dans le monde physique.
- Jeu vidéo. Apprend aux robots à jouer à des jeux vidéo.
- Gestion des ressources. Aide les entreprises à planifier l'affectation des ressources.
Comment choisir et construire le bon modèle d'apprentissage automatique ?
Développer le bon modèle d'apprentissage automatique pour résoudre un problème peut s'avérer complexe. Elle nécessite de la diligence, de l'expérimentation et de la créativité, comme le montre un plan en sept étapes sur la façon de construire un modèle d'apprentissage automatique, dont voici un résumé.
1. Comprendre le problème de l'entreprise et définir les critères de réussite. L'objectif est de convertir les connaissances du groupe sur le problème commercial et les objectifs du projet en une définition appropriée du problème pour l'apprentissage automatique. Les questions doivent porter sur les raisons pour lesquelles le projet nécessite un apprentissage automatique, sur le type d'algorithme le mieux adapté au problème, sur les exigences en matière de transparence et de réduction des biais, ainsi que sur les entrées et les sorties attendues.
2. Comprendre et identifier les besoins en données. Déterminer les données nécessaires à l'élaboration du modèle et si elles sont en état d'être ingérées. Les questions doivent porter sur la quantité de données nécessaires, sur la manière dont les données collectées seront divisées en ensembles de test et d'entraînement, et sur la possibilité d'utiliser un modèle de ML pré-entraîné.
3. Collecter et préparer les données pour l'entraînement du modèle. Les actions comprennent le nettoyage et l'étiquetage des données, le remplacement des données incorrectes ou manquantes, l'amélioration et l'augmentation des données, la réduction du bruit et la suppression des ambiguïtés, l'anonymisation des données personnelles et la division des données en ensembles de formation, de test et de validation.
4. Déterminer les caractéristiques du modèle et l'entraîner. Sélectionner les bons algorithmes et les bonnes techniques. Définir et ajuster les hyperparamètres, entraîner et valider le modèle, puis l'optimiser. En fonction de la nature du problème, les algorithmes d'apprentissage automatique peuvent intégrer des capacités de compréhension du langage naturel, comme les réseaux neuronaux récurrents ou les transformateurs conçus pour les tâches de traitement du langage naturel. En outre, les algorithmes de stimulation peuvent être utilisés pour optimiser les modèles d'arbres de décision.
Formation et optimisation des modèles de ML
Apprenez comment les algorithmes et techniques suivants sont utilisés dans la formation et l'optimisation des modèles d'apprentissage automatique :
- Régularisation.
- Algorithmes de rétropropagation.
- Apprentissage par transfert.
- Apprentissage automatique contradictoire.
5. Évaluer les performances du modèle et établir des critères de référence. Ce travail englobe les calculs de la matrice de confusion, les indicateurs clés de performance de l'entreprise, les mesures d'apprentissage automatique, les mesures de la qualité du modèle et la détermination de la capacité du modèle à atteindre les objectifs de l'entreprise.
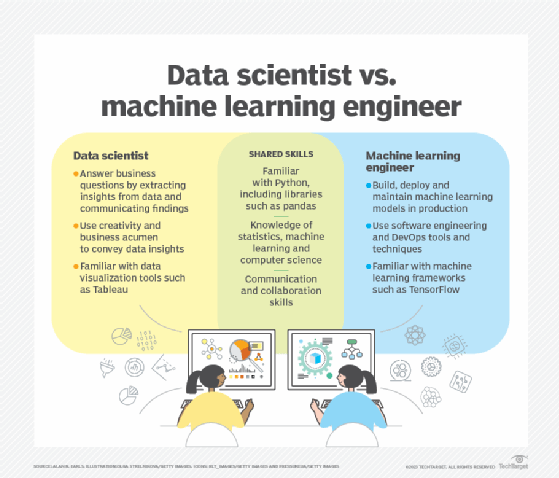
6. Déployer le modèle et surveiller ses performances en production. Cette partie du processus est connue sous le nom d'opérationnalisation du modèle et est généralement gérée en collaboration par les ingénieurs en science des données et en apprentissage automatique. Mesurer continuellement les performances du modèle, développer un point de référence pour mesurer les itérations futures du modèle et répéter pour améliorer les performances globales. Les environnements de déploiement peuvent être dans le cloud, à la périphérie ou dans les locaux.
7. Affiner et ajuster en permanence le modèle en production. Même lorsque le modèle de ML est en production et fait l'objet d'une surveillance continue, le travail continue. Les besoins de l'entreprise, les capacités technologiques et les données du monde réel évoluent de manière inattendue, ce qui peut donner lieu à de nouvelles demandes et exigences.
Applications d'apprentissage automatique pour les entreprises
L'apprentissage automatique fait désormais partie intégrante des logiciels d'entreprise qui gèrent les organisations. Voici quelques exemples de l'utilisation de l'apprentissage automatique dans diverses disciplines :
- Intelligence économique. Les logiciels de BI et d'analyse prédictive utilisent des algorithmes d'apprentissage automatique, notamment la régression linéaire et la régression logistique, pour identifier les points de données significatifs, les modèles et les anomalies dans de grands ensembles de données.
- Gestion de la relation client. Les principales applications de l'apprentissage automatique dans la gestion de la relation client comprennent l'analyse des données clients pour segmenter les clients, prédire des comportements tels que le désabonnement, faire des recommandations, ajuster les prix, optimiser les campagnes d'emailing, fournir une assistance par chatbot et détecter les fraudes.

- Sécurité et conformité. Des algorithmes avancés, tels que la détection d'anomalies et les techniques de machine à vecteur de support (SVM), identifient les comportements normaux et les écarts, ce qui est essentiel pour identifier les cybermenaces potentielles. Les SVM trouvent la meilleure ligne ou frontière qui divise les données en différents groupes séparés par le plus d'espace possible.
- Systèmes d'information sur les ressources humaines. Les modèles ML rationalisent le processus d'embauche en filtrant les candidatures et en identifiant les meilleurs candidats pour un poste ouvert.
- Gestion de la chaîne d'approvisionnement. Les techniques d'apprentissage automatique optimisent les niveaux de stock, rationalisent la logistique, améliorent la sélection des fournisseurs et traitent de manière proactive les perturbations de la chaîne d'approvisionnement.
- Traitement du langage naturel. Les modèles de traitement du langage naturel permettent aux assistants virtuels tels qu'Alexa, Google Assistant et Siri d'interpréter le langage humain et d'y répondre.
Quels sont les avantages et les inconvénients de l'apprentissage automatique ?
La capacité de l'apprentissage automatique à identifier les tendances et à prédire les résultats avec une plus grande précision que les méthodes qui s'appuient strictement sur les statistiques conventionnelles - ou sur l'intelligence humaine - confère un avantage concurrentiel aux entreprises qui déploient l'apprentissage automatique de manière efficace. L'apprentissage automatique peut profiter aux entreprises de plusieurs façons :
- Analyser les données historiques pour fidéliser les clients.
- Lancer des systèmes de recommandation pour augmenter le chiffre d'affaires.
- Améliorer la planification et les prévisions.
- Évaluer les schémas pour détecter les fraudes.
- Augmenter l'efficacité et réduire les coûts.
Mais l'apprentissage automatique présente aussi des inconvénients. Tout d'abord, il peut être coûteux. Les projets d'apprentissage automatique sont généralement menés par des scientifiques des données, qui perçoivent des salaires élevés. Ces projets nécessitent également une infrastructure logicielle qui peut être coûteuse. Et les entreprises peuvent être confrontées à de nombreux autres défis.
Il y a le problème de la partialité de l'apprentissage automatique. Les algorithmes formés sur des ensembles de données qui excluent certaines populations ou contiennent des erreurs peuvent conduire à des modèles inexacts du monde qui, au mieux, échouent et, au pire, sont discriminatoires. Lorsqu'une entreprise fonde ses processus métier fondamentaux sur des modèles biaisés, elle peut subir un préjudice sur le plan réglementaire et sur celui de sa réputation.

Importance de l'apprentissage automatique interprétable par l'homme
Expliquer le fonctionnement d'un modèle d'apprentissage automatique spécifique peut s'avérer difficile lorsque le modèle est complexe. Dans certains secteurs verticaux, les data scientists doivent utiliser des modèles d'apprentissage automatique simples car il est important pour l'entreprise d'expliquer comment chaque décision a été prise. C'est particulièrement vrai dans les secteurs où les obligations de conformité sont lourdes, comme la banque et l'assurance. Les scientifiques des données doivent souvent trouver un équilibre entre la transparence, d'une part, et la précision et l'efficacité d'un modèle, d'autre part. Les modèles complexes peuvent produire des prédictions précises, mais il peut être difficile d'expliquer à un profane - ou même à un expert - comment un résultat a été déterminé.
Carrières dans l'apprentissage automatique et l'IA
La valeur du marché mondial de l'IA devrait atteindre près de 2 000 milliards de dollars d'ici à 2030, et le besoin de professionnels qualifiés dans le domaine de l'IA ne cesse de croître. Consultez les articles suivants relatifs au développement professionnel dans le domaine de la ML et de l'IA.
Comment constituer et organiser une équipe d'apprentissage automatique
Se préparer avec 19 questions et réponses d'entretien sur l'apprentissage automatique
4 certificats d'apprentissage automatique populaires à obtenir en 2023
Exemples d'apprentissage automatique dans l'industrie
L'apprentissage automatique a été largement adopté dans tous les secteurs. Voici quelques-uns des secteurs qui utilisent l'apprentissage automatique pour répondre aux exigences de leur marché :
- Services financiers. L'évaluation des risques, le commerce algorithmique, le service à la clientèle et les services bancaires personnalisés sont des domaines dans lesquels les sociétés de services financiers appliquent l'apprentissage automatique. Capital One, par exemple, a déployé l'apprentissage automatique pour la défense des cartes de crédit, que l'entreprise place dans la catégorie plus large de la détection des anomalies.
- Produits pharmaceutiques. Les fabricants de médicaments utilisent la ML pour la découverte de médicaments, les essais cliniques et la fabrication de médicaments. Eli Lilly a construit des modèles d'IA et de ML, par exemple, pour trouver les meilleurs sites pour les essais cliniques et augmenter la diversité des participants. Selon l'entreprise, ces modèles ont permis de réduire considérablement les délais des essais cliniques.
- Industrie manufacturière. Les cas d'utilisation de la maintenance prédictive sont fréquents dans l'industrie manufacturière, où une panne d'équipement peut entraîner des retards de production coûteux. En outre, l'aspect vision par ordinateur de l'apprentissage automatique permet d'inspecter les articles sortant d'une chaîne de production afin d'assurer le contrôle de la qualité.
- L'assurance. Les moteurs de recommandation peuvent suggérer des options aux clients en fonction de leurs besoins et de la manière dont d'autres clients ont bénéficié de produits d'assurance spécifiques. L'apprentissage automatique est également utile pour la souscription et le traitement des demandes d'indemnisation.
- Commerce de détail. Outre les systèmes de recommandation, les détaillants utilisent la vision par ordinateur pour la personnalisation, la gestion des stocks et la planification des styles et des couleurs d'une ligne de mode donnée. La prévision de la demande est un autre cas d'utilisation clé.
Quel est l'avenir de l'apprentissage automatique ?
Alimenté par les recherches massives menées par les entreprises, les universités et les gouvernements du monde entier, l'apprentissage automatique est une cible qui évolue rapidement. Des percées dans les domaines de l'IA et de l'intelligence artificielle semblent se produire quotidiennement, rendant les pratiques acceptées obsolètes presque aussitôt qu'elles sont acceptées. Ce que l'on peut dire avec certitude sur l'avenir de l'apprentissage automatique, c'est qu'il continuera à jouer un rôle central au XXIe siècle, transformant la façon dont le travail est effectué et la façon dont nous vivons.
Dans le domaine du NLP, l'amélioration des algorithmes et de l'infrastructure donnera naissance à une IA conversationnelle plus fluide, à des modèles de ML plus polyvalents capables de s'adapter à de nouvelles tâches et à des modèles linguistiques personnalisés adaptés aux besoins des entreprises.
Le domaine de la vision par ordinateur, qui évolue rapidement, devrait avoir un effet profond sur de nombreux domaines, qu'il s'agisse des soins de santé, où elle jouera un rôle de plus en plus important dans le diagnostic et le suivi à mesure que la technologie s'améliorera, des sciences de l'environnement, où elle pourrait être utilisée pour analyser et surveiller les habitats, ou de l'ingénierie logicielle, où elle est un élément essentiel des technologies de réalité augmentée et virtuelle.
À court terme, les plateformes d'apprentissage automatique font partie des domaines les plus concurrentiels de la technologie d'entreprise. Les principaux fournisseurs tels qu'Amazon, Google, Microsoft, IBM et OpenAI font la course à l'inscription des clients aux services de plateformes d'apprentissage automatique qui couvrent le spectre des activités de ML, y compris la collecte et la préparation des données, la classification des données, l'élaboration de modèles, la formation et le déploiement d'applications.
Au milieu de cet enthousiasme, les entreprises seront confrontées à un grand nombre des mêmes défis que ceux présentés par les technologies de pointe précédentes, qui évoluent rapidement. Les nouveaux défis comprennent l'adaptation de l'infrastructure existante aux systèmes d'apprentissage automatique, l'atténuation des biais de l'apprentissage automatique et la détermination de la meilleure façon d'utiliser ces nouveaux pouvoirs impressionnants de l'IA pour générer des profits pour les entreprises, malgré les coûts.






