Edge computing
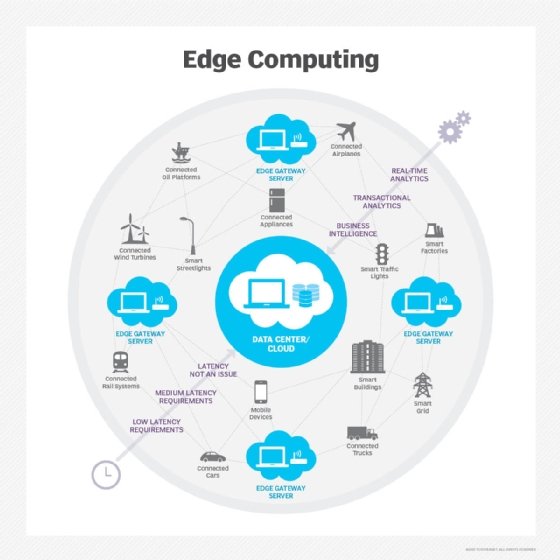
L'« Edge computing » (informatique de périphérie/de bord), est une architecture informatique (IT) dans laquelle les données d'un client sont traitées en périphérie du réseau, aussi près que possible de la source.
La transition vers l'Edge computing est motivée par l'essor du mobile, la baisse du coût des composants informatiques et l'augmentation du nombre d'appareils en réseau au sein de l'Internet des objets (IoT, Internet of Things). Selon la mise en oeuvre de l'architecture Edge computing, les données « périssables » (sensibles au facteur temps) seront traitées au point d'origine par un dispositif intelligent, ou envoyées à un serveur intermédiaire, installé à proximité du client. Les données moins périssables sont envoyées vers le cloud à des fins d'analyse historique, d'analytique du Big Data et de stockage à long terme.
Transmettre des quantités massives de données brutes sur un réseau impose une charge considérable aux ressources de ce dernier. Dans certains cas, il est bien plus efficace de traiter les données à proximité de la source, et de n'envoyer, via le réseau, que la partie qui présente une valeur à un datacenter distant. Par exemple, plutôt que de diffuser en continu des données relatives au niveau d'huile d'un véhicule, un capteur automobile enverra simplement des données de synthèse périodiquement à un serveur distant. Autre exemple, un thermostat intelligent transmettra uniquement ses données en cas de hausse ou de baisse de température en dehors d'une plage acceptable. Ou encore, une caméra de sécurité connectée en Wi-Fi et braquée sur une porte d'ascenseur utilisera une fonction d'analytique de périphérie (locale) et ne transmettra de données que si un certain pourcentage de pixels change entre deux images consécutives, indiquant ainsi un mouvement.
L'Edge computing peut, en outre, profiter aux environnements de succursales/bureau distant – les ROBO (Remote Office/Branch Office) – ainsi qu'aux entreprises dont la base d'employés est géographiquement dispersée. Dans de tels scénarios, des microdatacenters intermédiaires ou des serveurs hautes performances sont installés sur des sites distants. Leur rôle consiste à répliquer, en local, des services en cloud, améliorant ainsi les performances et la capacité d'un dispositif à agir sur des données périssables en une fraction de seconde. Selon le fournisseur et la mise en oeuvre technique, l'installation intermédiaire peut recevoir plusieurs appellations, notamment passerelle de périphérie (edge gateway), station de base, pivot (hub), cloudlet ou agrégateur.
Avantage non négligeable, l'Edge computing améliore le délai avant action et réduit le temps de réponse à quelques millisecondes, le tout en préservant les ressources réseau. Toutefois, le concept d'Edge computing n'est pas destiné à remplacer celui de cloud computing. Malgré sa capacité à réduire la latence et les goulets d'étranglement réseau, l'Edge computing peut poser d'énormes défis en matière de sécurité, de gestion des licences et de configuration.
Défis de sécurité : L'architecture distribuée de l'Edge computing accroît le nombre de vecteurs d'attaque. Plus le client de périphérie est « intelligent », plus il devient vulnérable aux infections par des logiciels malveillants et aux failles de sécurité.
Défis de gestion des licences : Les clients intelligents sont susceptibles d'induire des frais de licence cachés. En effet, si la version de base d'un client de périphérie paraît, au départ, présenter un tarif d'entrée de gamme, les fonctions supplémentaires peuvent impliquer une licence séparée... et faire grimper la facture.
Défis de configuration : A moins d'une gestion centralisée et robuste des dispositifs, les administrateurs peuvent accidentellement compromettre la sécurité, par exemple en oubliant de changer le mot de passe par défaut sur les différents dispositifs de périphérie, ou en négligeant de mettre à jour régulièrement les microprogrammes, provoquant ainsi une dérive des configurations.
Dans l'Edge computing – l'informatique de périphérie – la notion de « périphérie » est issue des représentations schématiques des réseaux : en général, leur périphérie désigne le point par lequel le trafic pénètre dans le réseau ou en sort. La périphérie est également le point où le protocole qui sous-tend le transport de données est susceptible de changer. Par exemple, un capteur intelligent utilisera un protocole à faible latence (comme MQTT) pour transmettre des données à un courtier de messages installé en périphérie du réseau ; et ce courtier utilisera, quant à lui, le protocole HTTP pour transmettre les données qui présentent un intérêt à un serveur distant par Internet.
Le consortium OpenFog emploie le terme de Fog computing – l'informatique brumeuse – pour décrire l'Edge computing. L'idée ici consiste à faire appel à la notion de « brume » (fog) pour véhiculer l'idée que les avantages du cloud computing doivent être rapprochés de la source des données. (En météorologie, la brume désigne simplement un nuage proche du sol.) Les membres du consortium sont notamment Cisco, ARM, Microsoft, Dell, Intel et l'Université de Princeton.





