Data warehouse (entrepôt de données)
Un entrepôt de données (Datawarehouse) est un dépôt de données provenant des systèmes opérationnels d'une organisation et d'autres sources, qui soutient les applications analytiques pour aider à la prise de décision. L'entreposage de données est un élément clé d'une stratégie globale de gestion des données : Les données stockées dans les entrepôts de données sont traitées et organisées pour être analysées par des analystes commerciaux, des cadres, des scientifiques des données et d'autres utilisateurs.
En règle générale, un entrepôt de données est une base de données relationnelle ou une base de données en colonnes hébergée sur un système informatique dans un centre de données sur site ou, de plus en plus, dans le cloud. Les données provenant d'applications de traitement des transactions en ligne (OLTP) et d'autres sources internes ou externes sont extraites et consolidées dans l'entrepôt de données à des fins de veille stratégique (BI), notamment pour l'interrogation ad hoc, l'aide à la décision et l'établissement de rapports d'entreprise. Les utilisateurs accèdent aux données par le biais de logiciels de BI et d'autres types d'outils d'analyse.
Composants de base de l'architecture d'un entrepôt de données
À un niveau fondamental, l'architecture d'un datawarehouse contient un ensemble de trois niveaux qui comprennent les principaux composants suivants :
- Un serveur de base de données pour le traitement, le stockage et la gestion des données en tant que niveau inférieur.
- Un moteur d'analyse qui exécute des applications et des requêtes BI en tant que niveau intermédiaire.
- Les outils de BI et de reporting qui soutiennent l'analyse, la visualisation et la présentation des données constituent le niveau le plus élevé.
Une architecture contient généralement aussi une couche d'intégration des données avec des outils qui extraient et combinent les données des systèmes opérationnels et une zone de préparation où les données sont nettoyées, transformées et organisées avant d'être chargées dans l'entrepôt de données. Une combinaison de logiciels d'intégration et de qualité des données est utilisée pour effectuer les tâches au niveau de la zone de préparation.
Un entrepôt de données d'entreprise stocke des données analytiques pour toutes les opérations commerciales d'une organisation ; par ailleurs, les unités commerciales individuelles peuvent avoir leurs propres entrepôts de données, en particulier dans les grandes entreprises. Les entrepôts de données peuvent également être connectés à plusieurs marais de données, qui sont des systèmes plus petits contenant des sous-ensembles de données d'une organisation pour un département ou un groupe d'utilisateurs spécifique.
Les entrepôts de données prennent également en charge les technologies de traitement analytique en ligne (OLAP), qui organisent les données en cubes classés selon différentes dimensions afin d'accélérer le processus d'analyse. En outre, les enregistrements de données stockés dans un entrepôt de données contiennent des métadonnées détaillées et des données récapitulatives qui permettent d'effectuer des recherches et sont utiles aux utilisateurs professionnels.
Types d'entrepôts de données et options de déploiement
Il existe deux approches principales pour mettre en œuvre un entrepôt de données : la méthode descendante et la méthode ascendante.
La méthode descendante a été créée par William H. Inmon, pionnier des DAtawarehouse. Elle consiste à construire d'abord l'entrepôt de données de l'entreprise, puis à utiliser les données qui y sont stockées pour créer des "data marts" ( forme de mini Datawarehouse centrée sur un unique sujet ou fonction) pour les unités et les départements de l'entreprise. Selon l'approche d'Inmon, les données sont extraites des systèmes sources et validées dans une zone de transit avant d'être intégrées dans un modèle de données normalisé et transformées pour les utilisations prévues en matière de BI et d'analyse.
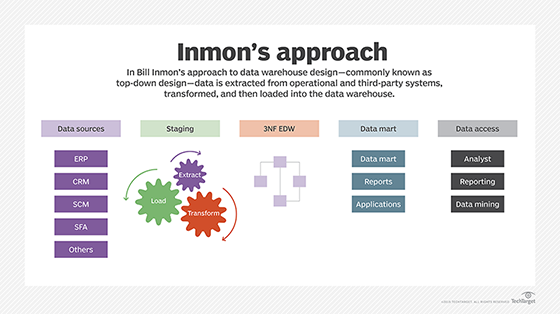
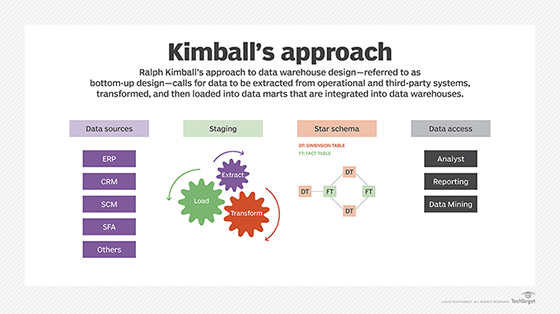
La méthode ascendante a été développée par le consultant Ralph Kimball en tant qu'approche alternative d'entreposage de données, qui nécessite la création préalable de "datamarts" dimensionnelles. Les données sont extraites des sources et modélisées dans un schéma en étoile, avec une ou plusieurs tables de faits connectées à une ou plusieurs tables dimensionnelles. Les données sont ensuite traitées et chargées dans des datamarts, qui peuvent être intégrés les uns aux autres ou utilisés pour alimenter un entrepôt de données d'entreprise.
Il existe également une approche hybride de la conception d'un entrepôt de données qui comprend des aspects des méthodes descendante et ascendante. Les organisations qui adoptent une stratégie hybride cherchent souvent à combiner la vitesse de développement de l'approche ascendante avec les capacités d'intégration des données qui peuvent être obtenues dans le cadre d'une conception descendante.
Enfin, certaines organisations ont adopté des entrepôts de données fédérés qui intègrent des systèmes analytiques distincts déjà mis en place indépendamment les uns des autres - une approche que les partisans décrivent comme un moyen pratique de tirer parti des déploiements existants.
Avantages de l'entrepôt de données
Les entrepôts de données peuvent être bénéfiques pour les organisations, tant du point de vue de l'entreprise que de celui de l'informatique. Par exemple, les avantages potentiels sont les suivants
- En consolidant des données provenant de différentes sources, les entrepôts de données donnent aux dirigeants d'entreprise et aux autres décideurs une vision plus complète des opérations, des performances et des tendances de l'entreprise que celle qu'ils pourraient obtenir autrement.
- Les entrepôts de données permettent également d'améliorer la qualité et la cohérence des données à des fins d'analyse, améliorant ainsi la précision des applications de veille stratégique.
- Gérés et utilisés efficacement, les entrepôts de données permettent de prendre des décisions plus éclairées qui peuvent aider les entreprises à améliorer leur productivité et leur efficacité opérationnelle, à augmenter leur chiffre d'affaires et à acquérir des avantages concurrentiels par rapport à leurs rivales.
- Les informations générées par les entrepôts de données peuvent être utilisées pour répondre de manière plus proactive aux tendances du marché, aux problèmes des entreprises et à leurs nouveaux besoins.
- Les entrepôts de données permettent de mieux comprendre le comportement et les préférences des clients afin d'aider les entreprises à améliorer le marketing, les ventes et le service à la clientèle - et, en fin de compte, la satisfaction des clients.
- Séparer les processus analytiques des processus opérationnels en les déplaçant vers un entrepôt de données peut améliorer les performances des systèmes opérationnels et permettre aux analystes de données et aux utilisateurs professionnels d'accéder aux données pertinentes et de les interroger plus rapidement.
- Pour répondre au mieux à leurs besoins commerciaux et informatiques, les entreprises peuvent choisir entre des systèmes sur site, des déploiements classiques dans le cloud et des offres d'entrepôt de données en tant que service (DWaaS) qui les libèrent de la nécessité de déployer, de configurer et d'administrer les entrepôts de données.
Cas d'utilisation et applications courantes des entrepôts de données
Parce qu'un entrepôt de données permet un accès plus rapide et plus efficace à divers ensembles de données et qu'il dispose généralement des ressources de calcul et de mémoire nécessaires pour exécuter des requêtes complexes, il peut aider les entreprises à tirer rapidement des enseignements de leurs données et, par conséquent, à en tirer de la valeur. Pour atteindre les objectifs de l'entreprise, les entrepôts de données sont généralement utilisés dans les buts suivants :
- Une seule source de vérité. De nombreuses organisations, en particulier les plus grandes, ont une structure opérationnelle complexe, avec diverses unités commerciales et départements qui produisent chacun des quantités importantes de données. Ces données peuvent être collectées, intégrées et fusionnées dans un entrepôt de données, ce qui permet aux utilisateurs de disposer d'ensembles de données plus complets pour obtenir des informations plus précises et prendre de meilleures décisions. Ce faisant, une organisation peut briser les silos de données qui limitent l'accès à certains ensembles de données et se traduisent souvent par des données incohérentes. L'entrepôt de données devient alors une source unique de vérité pour l'ensemble de l'organisation, ce qui permet aux utilisateurs des différentes unités de travailler avec les mêmes données.
- Rapports. De même, un entrepôt de données peut consolider différents types de données, y compris des données opérationnelles actuelles et des données historiques, dont certaines auraient pu être enfermées dans des systèmes existants. Par conséquent, il regroupe en un seul endroit toutes les données nécessaires à l'établissement de rapports internes à l'intention des cadres et des gestionnaires de l'entreprise. En outre, l'entrepôt de données permet de fournir rapidement ces informations : les rapports peuvent souvent être générés et distribués en quelques secondes ou minutes, contre des heures ou des jours s'ils sont élaborés à partir de données provenant de différents systèmes.
- Exploration de données. Le data mining est le processus qui consiste à trier de grands ensembles de données afin d'identifier des modèles et des relations qui peuvent fournir des indications sur les tendances futures et éclairer la prise de décision. Bien que les nouvelles plateformes de lacs de données qui contiennent des ensembles variés de données volumineuses soient maintenant souvent utilisées pour l'exploration de données dans les applications analytiques avancées, l'entrepôt de données continue à prendre en charge l'exploration de données dans le cadre des applications de BI dans de nombreuses organisations.
- BI et IA. Les bases de données opérationnelles ne peuvent généralement pas gérer le traitement requis pour les requêtes de BI et les initiatives d'intelligence artificielle (IA), mais les entrepôts de données le peuvent. Ils peuvent également fournir les grandes quantités de données dont les applications de BI et d'IA ont besoin pour une précision optimale et, dans le cas de l'apprentissage automatique et du traitement du langage naturel, en particulier, pour un apprentissage réussi.
- Audit et conformité réglementaire. L'entrepôt de données, qui contient des données historiques provenant de l'ensemble de l'entreprise, soutient également les processus d'audit et de conformité. Il peut fournir efficacement des enregistrements pertinents, ce qui permet à une organisation de gagner du temps et de l'argent dans le cadre de ses audits et de son travail de mise en conformité réglementaire, tout en éliminant les erreurs et en permettant une analyse plus précise des données.
Meilleures pratiques pour la conception et la gestion d'un entrepôt de données
Voici quelques bonnes pratiques à adopter dans le cadre du processus de conception et de gestion de l'entrepôt de données.
Comprendre les objectifs et les stratégies de l'entreprise qui justifient la nécessité d'un entrepôt de données. L'entrepôt de données contient des données structurées et traitées de manière à être prêtes pour les requêtes analytiques. C'est pourquoi il est important de commencer par comprendre les besoins de l'organisation en matière d'entreposage de données et les raisons commerciales qui les sous-tendent. Les responsables informatiques et les équipes de gestion des données doivent impliquer les parties prenantes de l'entreprise dans ces discussions, car les objectifs de l'entreprise qui motivent le besoin d'un entrepôt de données aideront à prendre des décisions sur les données à inclure, les sources de données requises et la manière de formater les ensembles de données.
Examiner le programme de gouvernance des données, le plan de gestion des données et les processus de soutien de l'organisation. La valeur d'un entrepôt de données découle des données qu'il contient, et non du matériel et des logiciels sous-jacents. Par conséquent, l'organisation doit revoir son programme de gouvernance des données et sa stratégie globale de gestion des données et les mettre à jour si nécessaire pour prendre en charge les cas d'utilisation prévus de l'entrepôt de données. Les processus de gestion des données de tous les systèmes sources désignés doivent également être revus afin de s'assurer que les données introduites dans l'entrepôt de données sont propres, exactes et cohérentes.
Cette planification doit également tenir compte de la fréquence à laquelle les données doivent être chargées et du choix entre le traitement des données par lots ou en temps réel, en fonction des cas d'utilisation de l'entreprise. En outre, les chefs de projet et leurs équipes doivent confirmer l'existence d'un processus permanent de réexamen de ces considérations et de mise à jour des plans et processus de gestion des données. Par exemple, cette étape peut inclure le déploiement de capacités de capture des données de changement, de sorte que toute modification apportée aux bases de données soit répliquée dans l'entrepôt de données. Les équipes doivent également définir les autorisations des utilisateurs et les contrôles d'accès, et répondre aux exigences plus larges en matière de sécurité des données et de conformité.
Sélectionner l'architecture, la plate-forme et les outils appropriés pour l'entrepôt de données. Les cas d'utilisation et les exigences de l'entreprise doivent également être pris en compte pour déterminer les bonnes technologies pour l'entrepôt de données. Il y a toute une série de questions à poser. Par exemple, les besoins de l'entreprise nécessitent-ils un entrepôt de données sur site ou un entrepôt basé sur le cloud répondrait-il mieux aux objectifs de l'organisation ? De même, faut-il utiliser des outils d'extraction, de transformation et de chargement (ETL) ou la méthode alternative d'extraction, de chargement et de transformation (ELT) pour alimenter l'entrepôt en données ? Faut-il prévoir une couche d'intégration indépendante de la source ? L'organisation doit-elle déployer elle-même une plateforme d'entrepôt de données ou faire appel à un service géré ?
Adopter de nouveaux processus pour optimiser l'entrepôt de données et maximiser sa valeur commerciale. Les pratiques établies et émergentes peuvent aider les organisations à optimiser la gestion d'un entrepôt de données et à maximiser sa valeur. Par exemple, les techniques d'observabilité des données peuvent aider à maintenir la santé des données dans les systèmes d'entreprise et les pipelines de données. L'application de méthodologies de développement agiles à la gestion des entrepôts de données peut permettre de fournir une valeur commerciale plus rapidement et avec moins de risques qu'en utilisant une approche traditionnelle en cascade. La mise en place de capacités de BI et d'analyse en libre-service peut également accélérer la création de valeur en facilitant l'analyse des données par les utilisateurs.
Entrepôts de données sur site ou dans le cloud
Comme d'autres types de systèmes informatiques, les entrepôts de données évoluent de plus en plus vers l'informatique dématérialisée. Tous les grands fournisseurs d'entrepôts de données proposent aujourd'hui des systèmes basés sur l'informatique dématérialisée, disponibles à la fois pour des déploiements classiques gérés par l'utilisateur et dans le cadre d'offres DWaaS entièrement gérées. Il s'agit de fournisseurs qui ont d'abord proposé des entrepôts de données sur site - notamment IBM, Microsoft, Oracle, SAP et Teradata - ainsi que de fournisseurs qui ont développé des entrepôts de données spécifiquement pour le cloud, comme Amazon Web Services (AWS), Google et Snowflake.
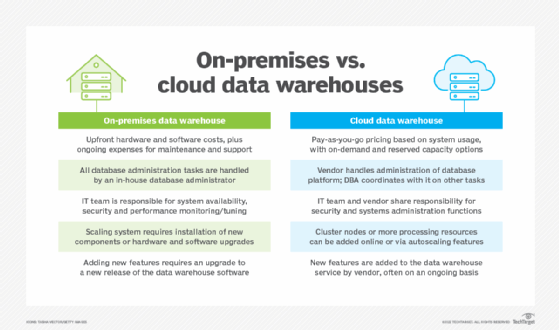
En général, l'architecture sous-jacente est la même pour les entrepôts de données sur site et dans le cloud. Mais ils présentent tous deux des avantages et des inconvénients potentiels les uns par rapport aux autres. Par exemple, un entrepôt de données fonctionnant sur un serveur sur site peut présenter les avantages suivants par rapport à un entrepôt en cloud :
- Temps de réponse plus rapide et moins de latence pour les utilisateurs.
- Un meilleur contrôle de l'administration des bases de données, de la maintenance du système et de la sécurité par les équipes informatiques et de gestion des données.
- Une surveillance plus stricte à des fins de conformité réglementaire, en particulier dans les secteurs très réglementés.
- Des coûts potentiellement inférieurs - ou au moins comparables - sur la durée de vie de l'entrepôt de données, même si les coûts initiaux sont plus élevés en raison de la nécessité d'acheter et d'installer une nouvelle technologie.
D'autre part, les entrepôts de données en cloud offrent les avantages suivants :
- La sécurité, la sauvegarde des données et les capacités de reprise après sinistre fournies par le fournisseur de services cloud, en particulier dans les environnements DWaaS.
- Évolutivité plus facile et plus rapide en fonction de l'augmentation des volumes de données et des besoins en ressources système.
- Des coûts de démarrage réduits, sans achat initial de matériel ou de logiciel.
- Installation et mise à disposition plus rapides d'un nouvel entrepôt de données.
- Une fiabilité potentiellement plus élevée, car les fournisseurs de services en cloud offrent généralement plus de redondance et disposent de compétences plus approfondies en matière de gestion des données que la plupart des organisations ne peuvent s'offrir par elles-mêmes.
- Des connexions plus faciles avec d'autres services basés sur le cloud qu'un entrepôt de données sur site ne peut généralement offrir.
Une autre option est un environnement d'entrepôt de données hybride qui combine des systèmes cloud et sur site. Par exemple, une organisation peut conserver des données sensibles dans un entrepôt de données sur site pour des raisons de confidentialité et de conformité réglementaire, tout en déplaçant d'autres ensembles de données vers un référentiel basé sur le cloud.
Entrepôts de données vs. lacs de données vs. bases de données
Les lacs de données et les entrepôts de données soutiennent tous deux les applications analytiques, mais il existe des différences notables entre ces deux référentiels de données. Les entrepôts de données stockent généralement des données traitées dans des schémas prédéfinis conçus pour des applications spécifiques de BI, d'analyse et de reporting. En général, ils contiennent des données structurées classiques provenant de systèmes de traitement des transactions et d'autres applications d'entreprise.
En revanche, un lac de données est un référentiel pour tous les types de données brutes, qu'elles soient structurées, non structurées ou semi-structurées. Les lacs de données sont le plus souvent construits sur Hadoop, Spark ou d'autres plateformes de big data, et non sur des bases de données. Un schéma n'a pas besoin d'être défini en amont dans un lac de données - au lieu de cela, les ensembles de données peuvent être analysés tels quels ou filtrés et préparés pour des applications analytiques individuelles. Les processus ELT sont courants dans les lacs de données, par opposition aux approches ETL le plus souvent utilisées dans les entrepôts de données.
Grâce à leur flexibilité et à leur prise en charge d'ensembles de données variés, les lacs de données peuvent gérer des types d'analyse plus avancés que les entrepôts de données. Par exemple, ils peuvent être utilisés pour l'apprentissage automatique, la modélisation prédictive, l'exploration de texte et d'autres applications de science des données.
Les entrepôts de données diffèrent également des bases de données opérationnelles. Alors qu'un entrepôt de données stocke des données provenant de sources multiples à des fins d'analyse, une base de données opérationnelle est généralement utilisée pour collecter, traiter et stocker des données provenant d'un seul système ou d'une seule application afin de soutenir les processus opérationnels en cours. Les données de ces bases sont ensuite consolidées, nettoyées et introduites dans les entrepôts de données.
Historique et innovations en matière d'entrepôts de données
Le concept d'entreposage de données remonte aux travaux menés au milieu des années 1980 par les chercheurs d'IBM Barry Devlin et Paul Murphy. Le duo a inventé le terme d'entrepôt de données d'entreprise dans son document de 1988 intitulé "An architecture for a business and information system", qui décrivait le cadre d'un système de recherche d'informations et de reporting conçu pour être utilisé au sein d'IBM. Le document stipulait ce qui suit :
"L'architecture est basée sur l'hypothèse qu'un tel service fonctionne à partir d'un référentiel de toutes les informations commerciales requises, connu sous le nom d'entrepôt de données commerciales (BDW). ... La mise en œuvre physique d'un service d'entrepôt de données d'entreprise est subordonnée à l'existence d'un processus d'entreprise et d'une architecture de l'information qui définissent (1) le flux de rapports entre les fonctions et (2) les données requises".
Bill Inmon, comme il est plus connu, a fait progresser le développement des entrepôts de données avec son livre Building the Data Warehouse (1992), ainsi qu'en écrivant quelques-unes des premières chroniques sur le sujet. Dans le cadre de sa méthodologie de conception descendante pour la création d'un entrepôt de données, Inmon a décrit la technologie comme une collection de données orientée vers le sujet, intégrée, variable dans le temps et non volatile, qui soutient le processus de prise de décision d'une organisation.
La croissance de la technologie s'est poursuivie avec la création en 1995 du Data Warehousing Institute, un organisme de formation et de recherche aujourd'hui connu sous le nom de TDWI, qui se concentre plus largement sur les technologies d'analyse et de gestion des données. En 1996, Ralph Kimball a publié son livre The Data Warehouse Toolkit, qui présentait sa modélisation dimensionnelle et son approche ascendante de la conception des entrepôts de données.
Les premiers utilisateurs ont commencé à déployer des entrepôts de données au milieu des années 1990, et l'utilisation générale par les organisations a commencé à croître plus tard dans la décennie et s'est généralisée dans les années 2000. En 2008, Inmon a mis à jour sa méthodologie en introduisant un concept d'entrepôt de données 2.0 qui se concentre sur l'inclusion de capacités de gestion du cycle de vie des données, de données non structurées, de métadonnées et d'environnements de traitement compartimentés.
L'évolution suivante de l'entrepôt de données a eu lieu en 2012, lorsque AWS a lancé le premier entrepôt de données basé sur le cloud, Amazon Redshift. D'autres fournisseurs ont rapidement emboîté le pas, et le nombre d'options d'entrepôts de données dans le cloud a proliféré au cours des années suivantes. Les fournisseurs ont également intégré davantage de fonctions d'automatisation et d'intelligence dans leurs logiciels d'entrepôt de données. Par exemple, Oracle a lancé en 2018 Oracle Autonomous Data Warehouse, une version de sa technologie Autonomous Database que l'entreprise qualifie d'"auto-conduite".
En outre, les systèmes de big data sont devenus une extension précieuse des entrepôts de données dans de nombreuses organisations. Dans certains cas, les clusters Hadoop ou d'autres plateformes de big data servent de zone de transit pour les entrepôts de données traditionnels. Dans d'autres cas, les entrepôts de données et les lacs de données sont déployés dans un environnement analytique unifié.
Cela a également conduit au développement du data lakehouse, qui combine la flexibilité et l'évolutivité d'un data lake avec les fonctionnalités d'interrogation et de gestion des données d'un entrepôt de données. Le concept a été présenté pour la première fois en 2017, et les technologies de data lakehouse ont été mises à disposition par différents fournisseurs depuis lors.




