Data lake (lac de données)
Qu'est-ce qu'un lac de données (datalake) ?
Un lac de données ou datalake est un référentiel de stockage qui conserve une grande quantité de données brutes dans leur format natif jusqu'à ce qu'elles soient nécessaires pour des applications analytiques. Alors qu'un entrepôt de données traditionnel (datawarehouse) stocke les données dans des dimensions et des tableaux hiérarchiques, un datalake utilise une architecture plate pour stocker les données, principalement dans des fichiers ou un stockage d'objets. Les utilisateurs bénéficient ainsi d'une plus grande flexibilité en matière de gestion, de stockage et d'utilisation des données.
Les lacs de données sont souvent associés aux systèmes Hadoop. Dans les déploiements basés sur le cadre de traitement distribué, les données sont chargées dans le système de fichiers distribué Hadoop (HDFS) et résident sur les différents nœuds informatiques d'un cluster Hadoop. Cependant, les lacs de données sont de plus en plus souvent construits sur des services de stockage d'objets dans le cloud plutôt que sur Hadoop. Certaines bases de données NoSQL sont également utilisées comme plateformes de datalake.
Pourquoi les organisations utilisent-elles des lacs de données ?
Les lacs de données stockent généralement des ensembles de données volumineuses qui peuvent inclure une combinaison de données structurées, non structurées et semi-structurées. Ces environnements ne sont pas adaptés aux bases de données relationnelles sur lesquelles sont construits la plupart des entrepôts de données. Les systèmes relationnels exigent un schéma rigide pour les données, ce qui les limite généralement au stockage de données transactionnelles structurées. Les lacs de données prennent en charge différents schémas et n'ont pas besoin d'être définis au préalable. Cela leur permet de traiter différents types de données dans des formats distincts.
Par conséquent, les lacs de données sont un élément clé de l'architecture des données dans de nombreuses organisations. Les entreprises les utilisent principalement comme plateforme pour l'analyse des big data et d'autres applications de science des données nécessitant de grands volumes de données et impliquant des techniques d'analyse avancées, telles que l'exploration de données, la modélisation prédictive et l'apprentissage automatique.
Un datalake fournit un emplacement central aux scientifiques et analystes de données pour trouver, préparer et analyser les données pertinentes. Sans datalake, ce processus est plus compliqué. Il est également plus difficile pour les entreprises de tirer pleinement parti de leurs données pour prendre des décisions et élaborer des stratégies plus éclairées.
Architecture du datalake
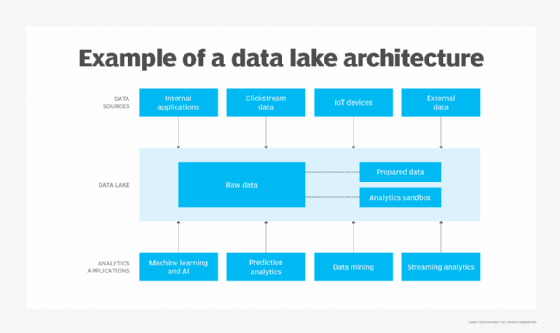
De nombreuses technologies peuvent être utilisées dans les lacs de données et les organisations peuvent les combiner de différentes manières. Cela signifie que l'architecture d'un datalake varie souvent d'une organisation à l'autre. Par exemple, une entreprise peut déployer Hadoop avec le moteur de traitement Spark et HBase, une base de données NoSQL qui s'exécute au-dessus de HDFS. Une autre peut exécuter Spark sur des données stockées dans Amazon Simple Storage Service (S3). Une troisième peut choisir d'autres technologies.
Par ailleurs, tous les lacs de données ne stockent pas uniquement des données brutes. Certains ensembles de données peuvent être filtrés et traités à des fins d'analyse lorsqu'ils sont ingérés. Dans ce cas, l'architecture du datalake doit le permettre et inclure une capacité de stockage suffisante pour les données préparées. De nombreux lacs de données comprennent également des bacs à sable analytiques, des espaces de stockage dédiés que les data scientist peuvent utiliser pour travailler avec les données.
Cependant, trois grands principes architecturaux distinguent les lacs de données des référentiels de données conventionnels :
- Aucune donnée ne doit être rejetée. Tout ce qui est collecté à partir des systèmes sources peut être chargé et conservé dans un datalake si on le souhaite.
- Les données peuvent être stockées dans un état non transformé ou presque, telles qu'elles ont été reçues du système source.
- Ces données sont ensuite transformées et intégrées dans un schéma en fonction des besoins d'analyse spécifiques, une approche connue sous le nom de "schéma en lecture".
Quelle que soit la technologie utilisée pour le déploiement d'un datalake, d'autres éléments doivent également être inclus pour garantir que le datalake est fonctionnel et que les données qu'il contient ne sont pas perdues. Il s'agit notamment des éléments suivants :
- Une structure de dossiers commune avec des conventions de dénomination.
- Un catalogue de données consultable pour aider les utilisateurs à trouver et à comprendre les données.
- Une taxonomie de classification des données pour identifier les données sensibles, avec des informations telles que le type de données, le contenu, les scénarios d'utilisation et les groupes d'utilisateurs possibles.
- Outils de profilage des données permettant de classer les données et d'identifier les problèmes de qualité des données.
- Un processus normalisé d'accès aux données pour aider à contrôler et à suivre les personnes qui accèdent aux données.
- Protections des données, telles que le masquage des données, le cryptage des données et le contrôle automatisé de l'utilisation.
La connaissance des données par les utilisateurs d'un datalake est également indispensable, en particulier s'il s'agit d'utilisateurs professionnels agissant en tant que scientifiques de données citoyens. En plus d'être formés à la navigation dans le datalake, les utilisateurs doivent comprendre les techniques de gestion et de qualité des données, ainsi que les politiques de gouvernance et d'utilisation des données de l'organisation.
Datalake ou entrepôt de données
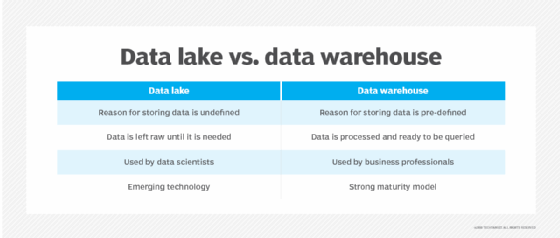
Les principales différences entre les datalake et les datawarehouse sont leur prise en charge des types de données et leur approche du schéma. Dans un entrepôt de données qui stocke principalement des données structurées, le schéma des ensembles de données est prédéterminé et il existe un plan de traitement, de transformation et d'utilisation des données lorsqu'elles sont chargées dans l'entrepôt. Ce n'est pas nécessairement le cas d'un datalake. Il peut héberger différents types de données et n'a pas besoin d'avoir un schéma défini pour eux ou un plan spécifique pour la façon dont les données seront utilisées.
Pour illustrer les différences entre les deux plates-formes, comparons un entrepôt à un lac. Un lac est liquide, mouvant, amorphe et alimenté par des rivières, des ruisseaux et d'autres sources d'eau non filtrée. À l'inverse, un entrepôt est une structure dotée d'étagères, d'allées et d'emplacements désignés pour stocker les articles qu'il contient et qui sont destinés à des usages spécifiques.
Cette différence conceptuelle se manifeste de plusieurs manières, dont les suivantes :
Plateformes technologiques. L'architecture d'un entrepôt de données comprend généralement une base de données relationnelle fonctionnant sur un serveur classique, tandis qu'un datalake est généralement déployé dans un cluster Hadoop ou un autre environnement big data.
Sources de données. Les données stockées dans un entrepôt sont principalement extraites d'applications internes de traitement des transactions pour prendre en charge les requêtes de base de business intelligence (BI) et de reporting, qui sont souvent exécutées dans des datasmarts associés créés pour des départements et des unités d'affaires spécifiques. Les lacs de données stockent généralement une combinaison de données provenant d'applications métier et d'autres sources internes et externes, telles que les sites web, les appareils IoT, les médias sociaux et les applications mobiles.
Utilisateurs. Les entrepôts de données sont utiles pour analyser des données curatives provenant de systèmes opérationnels au moyen de requêtes rédigées par une équipe de BI ou par des analystes commerciaux et d'autres utilisateurs de BI en libre-service. Les données d'un datalake n'étant souvent pas classées et pouvant provenir de diverses sources, elles ne conviennent généralement pas à l'utilisateur moyen de BI. Les lacs de données conviennent mieux aux data scientists qui ont les compétences nécessaires pour trier les données et en extraire le sens.
Qualité des données. Les données d'un entrepôt de données sont généralement considérées comme une source unique de vérité parce qu'elles ont été consolidées, prétraitées et nettoyées pour trouver et corriger les erreurs. Les données d'un datalake sont moins fiables car elles proviennent souvent de différentes sources et sont laissées à l'état brut sans vérification préalable de leur exactitude et de leur cohérence.
Agilité et évolutivité. Les lacs de données sont des plateformes très flexibles : Parce qu'ils utilisent du matériel de base, la plupart d'entre eux peuvent être reconfigurés et étendus selon les besoins pour répondre à l'évolution des exigences en matière de données et des besoins de l'entreprise. Les entrepôts de données sont moins flexibles en raison de leur schéma rigide et de leurs ensembles de données préparés.
Sécurité. Les entrepôts de données disposent de protections de sécurité plus matures parce qu'ils existent depuis plus longtemps et qu'ils sont généralement basés sur des technologies courantes qui existent elles aussi depuis des décennies. Mais les méthodes de sécurité des lacs de données s'améliorent, et divers cadres et outils de sécurité sont désormais disponibles pour les environnements big data.
En raison de leurs différences, de nombreuses organisations utilisent à la fois un entrepôt de données et un datalake, souvent dans le cadre d'un déploiement hybride qui intègre les deux plateformes. Souvent, les lacs de données viennent compléter l'architecture de données et la stratégie de gestion des données d'entreprise d'une organisation au lieu de remplacer un entrepôt de données.
Datalake en cloud ou sur site
Au départ, la plupart des lacs de données étaient déployés dans des cdatacenter sur site. Mais ils font désormais partie des architectures de données cloud dans de nombreuses organisations.
Ce changement a commencé avec l'introduction de plateformes de big data basées sur le cloud et de services gérés qui intègrent Hadoop et Spark, ainsi que diverses autres technologies. En particulier, les leaders du marché des plateformes cloud, AWS, Microsoft et Google, proposent des offres groupées de technologies big data : Amazon EMR, Azure HDInsight et Google Dataproc, respectivement.
La disponibilité de services de stockage d'objets dans le cloud, tels que S3, Azure Blob Storage et Google Cloud Storage, a permis aux entreprises de disposer d'alternatives de stockage de données moins coûteuses que HDFS, ce qui a rendu les déploiements de datalake dans le cloud plus attrayants d'un point de vue financier. Les fournisseurs de cloud computing ont également ajouté des services de développement de datalake, d'intégration de données et d'autres services de gestion de données afin d'automatiser les déploiements. Même Cloudera, un pionnier d'Hadoop qui tirait encore environ 90 % de son chiffre d'affaires des utilisateurs sur site en 2019, propose désormais une plateforme cloud native qui prend en charge à la fois le stockage d'objets et HDFS.
Quels sont les avantages d'un datalake ?
Les lacs de données constituent une base pour les applications de data science et d'analyse avancée. Ils permettent ainsi aux entreprises de gérer plus efficacement leurs activités et d'identifier les tendances et les opportunités commerciales. Par exemple, une entreprise peut utiliser des modèles prédictifs sur le comportement d'achat des clients pour améliorer ses campagnes de publicité et de marketing en ligne. L'analyse dans un datalake peut également contribuer à la gestion des risques, à la détection des fraudes, à la maintenance des équipements et à d'autres fonctions de l'entreprise.
Comme les entrepôts de données, les lacs de données contribuent également à éliminer les silos de données en combinant des ensembles de données provenant de différents systèmes dans un référentiel unique. Cela permet aux équipes de science des données d'avoir une vue d'ensemble des données disponibles et simplifie le processus de recherche des données pertinentes et leur préparation à des fins d'analyse. Les lacs de données peuvent également contribuer à réduire les coûts informatiques et de gestion des données en éliminant les plateformes de données en double dans une organisation.
Un datalake offre également d'autres avantages, notamment les suivants :
- Il permet aux data scientists et aux autres utilisateurs de créer des modèles de données, des applications analytiques et des requêtes à la volée.
- Les lacs de données sont relativement peu coûteux à mettre en œuvre car Hadoop, Spark et de nombreuses autres technologies utilisées pour les construire sont en open source et peuvent être installées sur du matériel peu coûteux.
- La conception de schémas, le nettoyage, la transformation et la préparation des données, qui demandent beaucoup de travail, peuvent être reportés jusqu'à ce qu'un besoin commercial clair soit identifié pour les données.
- Diverses méthodes d'analyse peuvent être utilisées dans les environnements de lacs de données, notamment la modélisation prédictive, l'apprentissage automatique, l'analyse statistique, l'exploration de texte, l'analyse en temps réel et les requêtes SQL.
Quels sont les défis posés par les lacs de données ?
Malgré les avantages que les lacs de données offrent aux entreprises, leur déploiement et leur gestion peuvent s'avérer difficiles. Voici quelques-uns des défis que les lacs de données posent aux organisations :
- Les marécages de données. L'un des plus grands défis consiste à empêcher un datalake de se transformer en marécage de données. S'il n'est pas mis en place et géré correctement, le datalake peut devenir une décharge désordonnée de données. Les utilisateurs risquent de ne pas trouver ce dont ils ont besoin et les gestionnaires de données risquent de perdre la trace des données stockées dans le datalake, alors même qu'elles affluent.
- La surcharge technologique. La grande variété de technologies pouvant être utilisées dans les lacs de données complique également les déploiements. Tout d'abord, les entreprises doivent trouver la bonne combinaison de technologies pour répondre à leurs besoins particuliers en matière de gestion et d'analyse des données. Ensuite, elles doivent les installer, bien que l'utilisation croissante de l'informatique dématérialisée ait facilité cette étape.
- Coûts inattendus. Si les coûts technologiques initiaux ne sont pas excessifs, la situation peut changer si les entreprises ne gèrent pas soigneusement les environnements de lacs de données. Par exemple, les entreprises peuvent recevoir des factures surprises pour les lacs de données basés sur le cloud s'ils sont utilisés plus que prévu. La nécessité de faire évoluer les lacs de données pour répondre aux demandes de charge de travail augmente également les coûts.
- Gouvernance des données. L'un des objectifs d'un datalake est de stocker des données brutes en l'état pour diverses utilisations analytiques. Mais sans une gouvernance efficace des lacs de données, les organisations peuvent être confrontées à des problèmes de qualité, de cohérence et de fiabilité des données. Ces problèmes peuvent entraver les applications analytiques et produire des résultats erronés qui conduisent à de mauvaises décisions commerciales.
Fournisseurs de lacs de données
L'Apache Software Foundation développe Hadoop, Spark et diverses autres technologies open source utilisées dans les lacs de données. La Fondation Linux et d'autres groupes open source supervisent également certaines technologies de lacs de données. Les logiciels open source peuvent être téléchargés et utilisés gratuitement. Toutefois, les éditeurs de logiciels proposent des versions commerciales de nombreuses technologies et fournissent une assistance technique à leurs clients. Certains vendeurs développent et vendent également des logiciels propriétaires pour les lacs de données.
Il existe de nombreux fournisseurs de technologies de lacs de données, certains proposant des plateformes complètes et d'autres des outils pour aider les utilisateurs à déployer et à gérer les lacs de données. Parmi les principaux fournisseurs, on peut citer
- AWS. Outre Amazon EMR et S3, il dispose d'outils de soutien tels que AWS Lake Formation pour la construction de lacs de données et AWS Glue pour l'intégration et la préparation des données.
- Cloudera. Sa plateforme de données Cloudera peut être déployée dans le cloud public ou dans des cloud hybrides comprenant des systèmes sur site, et elle est soutenue par un service de datalake.
- Databricks. Fondée par les créateurs de Spark, elle propose une plateforme de datalake basée sur le cloud qui combine des éléments des lacs de données et des entrepôts de données.
- Dremio. Elle vend une plateforme "SQL lakehouse" qui prend en charge la conception de tableaux de bord BI et les requêtes interactives sur les lacs de données, et qui est également disponible en tant que service en cloud entièrement géré.
- Google. Il complète Dataproc et Google Cloud Storage avec Google Cloud Data Fusion pour l'intégration des données et un ensemble de services pour déplacer les lacs de données sur site vers le cloud.
- HPE. La plateforme HPE GreenLake prend en charge les environnements Hadoop dans le cloud et sur site, avec un stockage de fichiers et d'objets et un service de data lakehouse basé sur Spark.
- Microsoft. Outre Azure HD Insight et Azure Blob Storage, il propose Azure Data Lake Storage Gen2, un référentiel qui ajoute un espace de noms hiérarchique à Blob Storage.
- Oracle. Ses technologies de datalake basées sur le cloud comprennent un service big data pour les clusters Hadoop et Spark, un service de stockage d'objets et un ensemble d'outils de gestion des données.
- Qubole. La plateforme de datalake Qubole, native dans le cloud, offre des capacités de gestion, d'ingénierie et de gouvernance des données et prend en charge diverses applications analytiques.
- Snowflake. Bien qu'elle soit surtout connue comme fournisseur d'entrepôts de données cloud, la plateforme Snowflake prend également en charge les lacs de données et peut travailler avec des données dans des magasins d'objets cloud.






