S3 : une option de stockage de plus en plus utilisée pour Hadoop
Au cours des dernières années, le support du protocole S3 par Hadoop s’est considérablement enrichi. Au point que de nombreux utilisateurs effectuent aujourd’hui directement des requêtes sur des données stockées dans des systèmes de stockage objet, là où auparavant, ils les auraient importées dans HDFS.

Depuis sa création, Hadoop s’est imposé comme le framework de référence pour l’analyse de données en volume. Le problème est qu’avant d’analyser des données, il a longtemps été nécessaire de les charger dans le cluster Hadoop sur le système de fichiers HDFS. Or, ce dernier n’est ni le moyen le plus efficace, ni le plus simple, ni le plus économique pour stocker de grands volumes de données.
Le problème est que pour alimenter les algorithmes de plus en plus sophistiqués élaborés par les datascientists, il faut de plus en plus de données. Et ces données résident de plus en plus dans des systèmes de stockage objet : ils ont en effet le double mérite d’offrir une performance satisfaisante tout en ayant un très faible coût au gigaoctet. Ils sont aussi le support de stockage de choix d’une large partie des applications web de nouvelle génération.
Très vite, l’idée est donc apparue d’ajouter le support du protocole S3 à Hadoop afin de permettre au framework d’accéder nativement à des données stockées dans un stockage compatible S3. Ce support a le net avantage de permettre à Hadoop d’analyser ces données sans avoir à les précharger préalablement sur les nœuds HDFS du cluster.
Un support natif de S3 dans Hadoop
Le support de S3 dans Hadoop s’est régulièrement enrichi au cours des dix dernières années. Le premier support natif du protocole de stockage objet dans le framework est apparu en 2008 avec l’inclusion du client natif S3 (ou s3n, pour S3 Native Filesystem). L’intégration de s3n a permis à Hadoop de lire et d’écrire nativement des données dans un magasin S3 existant et donc de manipuler directement des données stockées dans un ou plusieurs « buckets », sans avoir nécessairement à les importer préalablement dans HDFS. Cette première implémentation souffrait toutefois de problèmes de performances et ne supportait pas certaines fonctions essentielles du protocole S3.
En 2014, la version 2.7 d’Hadoop a donc officiellement remplacé le client s3n par un client de nouvelle génération baptisé s3a. Ce nouveau client a apporté de multiples améliorations, dont celle portant sur des mécanismes de gestion des identités et des accès de S3. Il a également singulièrement amélioré les performances (notamment avec des outils comme Hive ou Spark).
L’arrivée de s3a n’a toutefois pas éliminé tous les problèmes que pose l’utilisation du protocole S3 avec Hadoop. En particulier, l’un des problèmes majeurs à traiter est le fait que contrairement à la plupart des stockages objet locaux, le service AWS S3 n’est qu’éventuellement cohérent. On entend par là qu’après une opération d’écriture, de mise à jour ou d’effacement, il est parfois nécessaire qu’un certain délai s’écoule avant que les modifications soient répercutées dans le système. Ainsi, en listant le contenu d’un répertoire, il est possible que S3 retourne un état qui ne soit pas cohérent avec les dernières opérations effectuées. Cela peut s’avérer catastrophique si l’on effectue une requête MapReduce, Hive ou Spark.
S3Guard : un mécanisme pour garantir la cohérence des données avec AWS S3
Les développeurs ont donc travaillé au développement de S3Guard dont l’objectif est de se protéger contre les éventuelles incohérences d’AWS S3 en maintenant un journal des opérations d’écritures effectuées sur le service. Ce journal est conservé sous forme de métadonnées dans une base DynamoDB et permet lors d’une lecture de s’assurer de la cohérence des informations retournées.
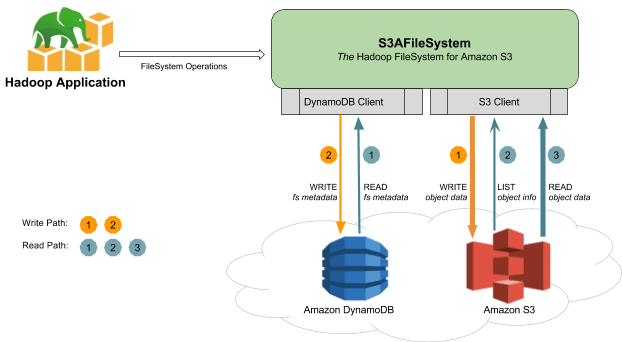 Principe de fonctionnement de S3Guard
Principe de fonctionnement de S3Guard
Les métadonnées stockées dans DynamoDB pouvant être utilisées comme un cache, la mise en œuvre de S3Guard contribue également à accélérer certaines opérations de lecture et à doper les performances des requêtes exécutées directement sur un magasin de stockage S3. Il est à noter qu’à ce jour S3Guard reste une fonction expérimentale du client s3a.
Hadoop : un support qui ne se limite pas à S3
AWS S3 n’est pas le seul service de stockage objet supporté par Hadoop. Au fil des années, le framework de traitement Big Data a hérité du support d’OpenStack Swift et d’Azure Blob.
En 2013, Rackspace et Mirantis ont contribué le code initial permettant le support du protocole OpenStack Swift. Deux ans plus tard, la collaboration entre Microsoft et Hortonworks a accouché de WASB, qui permet le support du stockage Azure Blob. Le support de WASB est activé par défaut dans HDInsights, l’implémentation Hadoop de Microsoft, mais aussi dans les distributions Hadoop d’HortonWorks et Cloudera - lorsqu’elles sont déployées dans des VM Azure.
En 2016, Microsoft a aussi ajouté le support d’Azure Data Lake comme cible de stockage pour Hadoop. La même année, Alibaba a également contribué le code nécessaire au support de son service de stockage objet Aliyun OSS de son service Alibaba Cloud (Aliyun).
Pour approfondir sur Stockage objet
-
![]()
S3 Express One Zone : AWS adapte son stockage objet à l’ère de l’IA
Par: Tim McCarthy
-
![]()
Mort d’Hadoop : le marché se trompe selon le TOSIT
Par: Gaétan Raoul
-
![]()
Les principales distributions Hadoop sur le marché
Par: Linda Rosencrance
-
![]()
Stockage objet : comment OpenIO est parvenu à atteindre 171 Go/s
Par: Yann Serra



