
photobank.kiev.ua - Fotolia
Machine Learning : comment choisir le bon framework ?
Ce ne sont pas les outils open source qui manquent pour le Machine Learning et le Deep Learning. A tel point que choisir les bons peut vite devenir une gageure. Pour faire un choix avisé, voici quelques conseils de spécialistes à bien garder à l'esprit.

Les frameworks de Machine Learning aident à s'affranchir des tâches fastidieuses lors de l'expérimentation, de l'optimisation ou de la mise en production d'une Intelligence Artificielle (IA).
Mais différents frameworks ont, logiquement, des atouts et des défauts différents. Les développeurs peuvent donc être confrontés à des choix cornéliens lorsqu'il s'agit de choisir le bon outil. Certains peuvent en effet vouloir donner la priorité à la facilité d'utilisation lors de l'apprentissage d'un nouvel algorithme, d'autres peuvent préférer l'optimisation du paramétrage et du déploiement pour la mise en production.
Parmi les frameworks les plus populaires aujourd'hui, citons TensorFlow, MXNet, scikit-learn, Keras et PyTorch. Ils sont couramment utilisés par les Data Scientists pour divers cas d'utilisation - dont le prédictif, la reconnaissance d'images ou les moteurs de recommandation.
Avant d'aller plus loin dans le choix technique, rappelons en préambule que construire des algorithmes n'est qu'une toute petite partie de l'ensemble d'un projet d'IA. Les entreprises consacrent souvent plus de temps aux tâches connexes, comme la préparation des données, la mise en production sur une infrastructure adaptée, ou encore la correction du modèle suite aux écarts entre la phase de test et celle du passage à l'échelle en production.
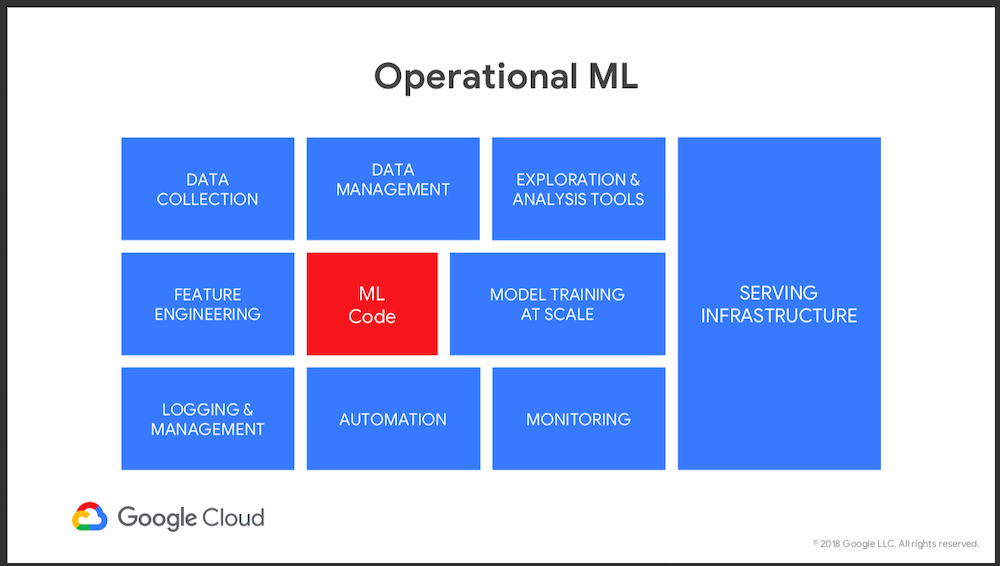 Toutes les composantes d'un bon projet de Machine Learning selon Google France
Toutes les composantes d'un bon projet de Machine Learning selon Google France
Commencez par les bonnes questions
Selon Mike Gualtieri, vice-président et analyste principal en charge de l'intelligence artificielle chez Forrester Research, trois considérations stratégiques doivent guider les développeurs et les équipes IT dans le choix du meilleur framework en fonction de leurs besoins.
- Le framework sera-t-il utilisé pour l'apprentissage profond (avec des réseaux neuronaux profonds) ou pour l'apprentissage statistique classique ?
- Quel sera le langage de programmation préféré pour développer les modèles ?
- Quels types de matériel, de logiciels et de services cloud seront utilisés pour scaler ?
Sur la deuxième question, Python et R sont aujourd'hui les plus populaires dans le monde du Machine Learning, même si d'autres langages comme C, Java ou Scala peuvent parfaitement être envisagés. Il n'en reste pas moins que la plupart des cas d'usages réels du Machine Learning ont été faits en Python - et que celui-ci tend à prendre l'ascendant sur son challenger, R, qui « a été conçu par des statisticiens et qui n'est pas le langage le plus élégant », dixit Mike Gualtieri. « Python devient de plus en plus le premier choix », constate-t-il.
Les frameworks Caffe et TensorFlow sont parmi les plus populaires parmi les codeurs Python... ce qui en fait, de facto, les plus populaires aujourd'hui dans le domaine du Machine Learning
Apprentissage profond (Deep Learning) ou Machine Learning « classique » ?
Bien que le Deep Learning ait récemment suscité beaucoup d'attention, le Machine Learning classique peut le surpasser pour de nombreuses applications (lire sur LeMagIT : Machine Learning vs Deep Learning ? La même différence qu'entre un ULM et un Airbus A380). Il peut également être plus simple.
Lorsque vous choisissez un framework, il est donc très important de connaître le type de données dont vous disposez et le type d'applications que vous souhaitez créer. Car si les outils d'apprentissage profonds - bien adaptés aux données non structurées - peuvent être entrainés pour interpréter des données structurées, le Machine Learning classique, lui, ne fonctionnera pas - ou mal - avec des données non structurées.
Par ailleurs, les frameworks de Deep Learning supportent spécifiquement la création de réseaux neuronaux. Parmi ces outils, TensorFlow est certainement le plus connu. MXNet et Caffe sont deux autres très bons choix. Ces frameworks aident à écrire des algorithmes pour le tagging des images ou le traitement avancé du langage naturel, entre autres.
« La raison pour laquelle les gens parlent beaucoup de Deep Learning pour les données non structurées, c'est que c'est la seule forme de Machine Learning qui peut faire cela aujourd'hui », analyse Mike Gualtieri.
Le Machine Learning classique reste très adapté pour différents types d'optimisation et d'analyse statistique.
Le framework le plus populaire est scikit-learn. Il est suivi par une variété de packages de Machine Learning pour R, accessibles via le Comprehensive R Archive Network (CRAN). Si vous êtes plus Python, vous irez certaine vers Scikit-learn, et si vous êtes plus R vers CRAN.
Apache Spark MLlib et H2O.ai sont deux autres trousses à outils très populaires, qui proposent un ensemble d'algorithmes open source et opérationnels.
Expérimentation vs Production
Dans les premiers stades de développement, les ingénieurs et développeurs vont expérimenter les algorithmes sur de petits jeux de données (qui peuvent être des extractions d'une base plus large). Le but est de trouver ceux qui fonctionnent - ou peuvent fonctionner - et ceux qui ne fonctionnent pas.
Mais lorsque l'on souhaite exécuter un modèle en production, il doit être capable de gérer sur l'ensemble des données. Il est judicieux d'utiliser un framework qui supporte une architecture distribuée, comme MLlib ou H20 d'Apache Spark.
« Quand on passe au "lourd", la scalabilité est une problématique important », avertit Mike Gualtieri.
Par exemple, dans un projet de tagging d'images, la première étape peut consister à télécharger un outil comme TensorFlow et l'exécuter sur un bureau pour entrainer des algorithmes et expérimenter différents modèles. Mais une fois qu'ils auront choisi une approche algorithmique, il faudra certainement appliquer l'algorithme choisi à un ensemble de données beaucoup plus vaste.
On le voit, le choix du framework doit aussi être fait en ayant cette étape en tête. L'outil doit bien fonctionner avec l'infrastructure « cible » - que ce soit des Nvidia GeForce GTX, ou un cloud - comme des services de GPU - sur AWS ou un TensorFlow managé par Google.
Différents types de scalabilité à considérer
Pendant la phase d'apprentissage des algorithmes, la scalabilité concerne la quantité de données pouvant être ingérées pour cet apprentissage et la vitesse à laquelle elles peuvent l'être. Cette performance peut évidemment être améliorée avec des algorithmes et un traitement distribués.
Dans la phase de déploiement, la scalabilité a plus à voir avec le nombre d'utilisateurs ou d'applications simultanés qui peuvent appeler le modèle en même temps.
Asaf Somekh, fondateur et PDG d'Iguazio, une société de services d'IA, rappelle que « le problème avec de nombreux projets est que l'environnement de l'apprentissage est très différent de celui de la production. Souvent, les Data Scientists travaillent avec leurs propres outils... qui sont complètement différents de ceux qui sont utilisés dans la phase de production ».
Lors du choix d'un framework, il est important de se demander s'il satisfera ces deux types de scalabilité et ces deux types d'environnement.
N'oubliez pas la phase d'optimisation des paramètres
Une autre considération clé dans le choix est sa faculté à optimiser les paramètres des algorithmes. Chaque algorithme a une approche différente pour analyser les données d'apprentissage et appliquer ce qu'il a appris à de nouveaux exemples.
Une image courante consiste à dire qu'un algorithme est un ensemble de boutons à pousser et de potentiomètres à tourner pour trouver une bonne combinaison (une image popularisée par le chercheur français Yann Le Cun, aujourd'hui chez Facebook). Chaque bouton ajuste la pondération (le coefficient ou "poids") de chaque variable et, dans le cas d'un neurone artificiel, le seuil de sortie - entre autres paramétrages possibles.
Lors du choix d'un framework, il est important de savoir si vous voulez que ce réglage soit entièrement automatisé ou manuel. « Plus il y a de boutons et de cadrans à tourner, plus il est difficile de trouver la bonne combinaison », explique Mike Gualtieri de Forrester
Trois types de projets et d'outils
Mike Gualtieri divise les outils de Machine Learning en trois catégories : de type calepins (notebook) - en résumé : à la main, de type multimodal et de type automatisé.
Le développement sur des outils de types notebooks - qui mélange texte et code comme Jupyter basé sur Python - permettent un contrôle poussé et minutieux sur tous les aspects de la personnalisation des modèles.
L'approche multimodale est essentiellement un moyen low-code de combiner la Data Sciences avec l'IA « infusée » dans solutions - comme Einstein de Salesforce - pour que les développeurs puissent compléter ou « étendre » ces modèles intégrés pour des cas d'utilisation particulier.
Une approche automatisée s'appuie sur un outil qui, comme son nom l'indique, essaye automatiquement une variété d'algorithmes pour un ensemble pré-établi de données d'entrée, jusqu'à ce qu'il identifie le(s) meilleurs candidats pour le cas d'utilisation voulu. Parmi ces outils, on trouve DataRobot et H20.ai. Voire AutoML de Google Cloud.
A lire aussi sur les projets de Machine Learning :
Trois conseils pour rendre votre Machine Learning plus efficace
L’expérience utilisateur, une clé du déploiement du Deep Learning en production
Notre Guide Spécial : Comprendre le Machine Learning
Machine Learning, Deep Learning, AI, Informatique cognitive : quelles différences ?
Notre Guide Spécial : Intelligence Artificielle : ses vrais bénéfices en 15 projets
« Une approche automatisée est attrayante parce que le niveau de compétence exigé est moins élevé que pour un Data Scientist qui fait tout "à la main" », résumé Mike Gualtieri. Dans certains cas, en effet, c'est un statisticien qui aura la responsabilité de diriger un projet de Machine Learning (plutôt qu'un spécialiste des données).
Ceci étant, l'analyste de Forrester Research ne s'attend pas à ce que ces outils automatisés remplacent les frameworks dédiés aux Data Scientists, tout comme les outils low code n'ont pas remplacé les experts Java et leurs outils de prédilection.
Le Machine Learning Open Source bénéficie d'une forte communauté
Bien que les éditeurs développent de nombreuses technologies propriétaires d'intelligence artificielle très bien pensées, les frameworks open source devraient continuer à dominer grâce la contribution intellectuelle massive d'experts du monde entier, prédit Chad Meley, vice-président du marketing chez Teradata.
Parmi ces frameworks de Deep Learning, ceux qui sont soutenus par des géants du numérique représentent certainement les meilleures options pour les entreprises, ajoute-t-il. Ils ont l'avantage d'être scalable, et bénéficient de parrains qui ont tout intérêt à investir pour les améliorer et à les supporter.
Les principaux fournisseurs de cloud ont tous un ou des frameworks de préférence. Selon la stratégie d'une entreprise, un DSI pourra vouloir s'aligner sur telle ou telle plateforme cloud en particulier ou, au contraire, mettre l'accent sur la portabilité entre différents clouds et le sur site, continue Chad Meley.
Un point négatif à prendre en considération si vous vous dirigez vers le choix d'un framework entièrement open source (non pré-packagé et/ou non managé dans un cloud par exemple) est l'absence de support. Les acteurs du cloud, même s'ils soutiennent l'open source, se livrent une bataille économique qui les poussent à ne proposer un support qu'au sein de leur offre (IaaS et PaaS) .
« TensorFlow est le plus populaire. Derrière, il y a différents avis sur l'élan et la vitalité des communautés de Caffe, de Keras, de MXNet, de CNTK, et de PyTorch », analyse Chad Meley qui a un avis plus tranché sur Theano « qui est en déclin ».
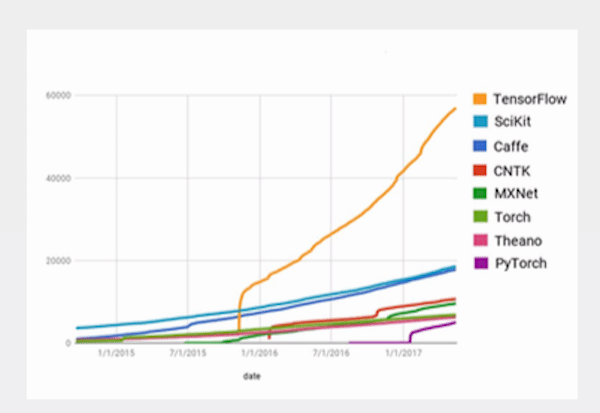 Popularité des des Frameworks selon Google France
Popularité des des Frameworks selon Google France
« Nous recommandons aussi à nos clients d'utiliser une API comme Keras qui s'exécute au-dessus des principaux framework de Machine Learning pour fournir un niveau d'abstraction supplémentaire et plus intuitif », conclut le porte-parole de Teradata.
De son côté, la société Iguazio a fait le choix d'utiliser différents frameworks - dont Spark, TensorFlow et H20.
Spark, par exemple, est très complet et s'appuie sur un écosystème très fort. En plus de SparkML, le framework comprend des fonctions de traitements de requêtes SQL, de gestion des flux de données en temps réel (streaming) et du traitement des données en graphe. Ce qui le rend exploitable dans plusieurs cas d'usage pour différents types d'équipes chez Iguazio.
Autre avantage de Spark pour Asaf Somekh, fondateur de la société : sa facilité et sa large base d'utilisateurs qui, selon lui, garantit que la technologie s'améliorera régulièrement et sera toujours disponible dans le futur.





