
vege - stock.adobe.com
L’essentiel sur les bases de données graphes
Les bases de données graphes se concentrent sur les relations entre les données, une propriété qui les distingue des autres SBGD NoSQL, mais aussi des bases relationnelles.
L’objectif principal des SGBD NoSQL est d’améliorer l’efficacité du stockage et de la gestion des données. Pour y parvenir, il faut utiliser de nouvelles technologies et sortir des sentiers battus.
Ces limites techniques étaient autrefois liées au stockage. Aujourd’hui, cette problématique s’est estompée en raison de la baisse significative du coût de cette ressource.
Reste qu’avec une base de données relationnelle, les limites du schéma SQL demeurent. Il y a pourtant des chemins de traverse qui peuvent nous permettre de connecter des données à large échelle, de les manipuler et de les exploiter avec le moins de friction possible.
Qu’est-ce qu’une base de données graphes ?
Une base de données orientée graphes est certainement un de ces chemins de traverse. Elle se concentre sur les relations entre les éléments de données autant que sur les données elles-mêmes, ce qui permet de les stocker de manière ciblée. L’utilisation d’un modèle de données orienté graphe permet de visualiser plus facilement les liens entre les données, ce qui facilite les analyses.
Basées sur la théorie des graphes, ces bases de données sont constituées de nœuds et d’arêtes. Les nœuds sont les entités d’une base de données graphes. En termes simples, ils sont les agents et les objets des relations et peuvent être présentés comme des réponses aux questions « qui » et « à qui ».
Chacune des entités possède un identifiant unique. Elles peuvent également avoir des propriétés constituées de paires clé-valeur et peuvent avoir des étiquettes avec ou sans métadonnées attribuant un rôle à un nœud particulier dans un domaine. Il existe également des arêtes entrantes et sortantes. Considérez-les comme les différentes extrémités d’une flèche vous indiquant qui est l’agent et qui est l’objet d’une relation.
Les arêtes sont tout aussi importantes que les nœuds, car elles contiennent un élément d’information essentiel. Elles représentent les relations entre les entités. Une base de données SQL aurait probablement une table désignée pour chaque classe de relations. Une base de données graphes ne nécessite pas une telle médiation puisqu’elle relie directement ses entités. Les arêtes ont aussi des identifiants uniques et, tout comme les nœuds, peuvent avoir d’autres propriétés que le type défini, la direction et le nœud de départ et d’arrivée.
Les deux modèles graphes les plus courants
Il existe deux modèles courants de bases de données graphes : les graphes du Resource Description Framework (RDF) et les graphes de propriété. Ils présentent des similitudes, mais sont conçus à des fins différentes.
Développés à l’origine par le W3C, les graphes RDF sont axés sur l’intégration des données. Ils sont constitués de triplets. Un triplet comprend une entité (sujet), un attribut (prédicat ou une propriété du sujet) et une valeur (un objet, une donnée ou une ressource). Le sujet et la valeur sont deux nœuds connectés par une arête, la propriété. Chacun de ces trois éléments est identifié par un identifiant de ressource unique. De la sorte, plusieurs prédicats peuvent connecter des sujets et des objets, tant que la notion de triplet est respectée. On les trouve dans les graphes de connaissances, et ils sont utilisés pour relier les données entre elles.
Les graphes de propriétés sont beaucoup plus descriptifs et chacun des éléments porte des propriétés, des attributs qui déterminent davantage ses entités. Ils se composent également de nœuds et d’arêtes reliant les nœuds, mais chaque nœud et chaque arête est considéré comme une structure. Cette structure de données est composée de paires clé-valeur, encodée au format JSON. Les arêtes incluent des clés spécifiques pour indiquer le ou les sens de la relation avec le ou les nœuds quand il faut prendre en compte une direction. Par conséquent, les graphes de propriété sont mieux adaptés à l’analyse des données.
De même, là où les identifiants uniques d’un triplet RDF sont des URL, dans un graphe de propriétés, ceux-ci correspondent à des chaînes de caractères.
Avantages
L’accent mis sur les arêtes d’un modèle orienté graphes signifie que ces bases de données représentent un moyen puissant de comprendre les relations les plus complexes entre les données. Cerise sur le gâteau, cette manière de stocker les relations permet également une exécution rapide des requêtes.
Avec une représentation claire des relations dans une base de données orientée graphes, il est plus facile de repérer les tendances et de reconnaître les éléments ayant le plus d’influence.
Inconvénients
Ces SGBD présentent le même inconvénient que les bases de données NoSQL : l’absence de langage de requête uniforme. Si cela peut constituer un obstacle à leur utilisation, cela n’affecte pas leur performance. Les langages de requêtes les plus courants sont PGQL, Gremlin, SPARQL, AQL, etc.
Un autre défaut est l’évolutivité de ces bases de données, car elles sont originellement conçues pour reposer sur une architecture à un seul niveau, ce qui signifie qu’il est difficile de les faire évoluer sur un certain nombre de serveurs.
Comme la plupart des bases de données NoSQL, elles sont conçues pour servir un objectif spécifique et y excellent. Elles ne constituent pas une solution universelle destinée à remplacer toutes les autres bases de données.
Cas d’usage et exemples
Comme les bases de données orientées graphes modélisent les relations entre les données, elles semblent parfaites pour le faire avec les gens. C’est un des cas d’usage les plus célèbres de cette technologie : le stockage des relations et l’analyse des engagements des usagers en provenance d’un réseau social. Vous pouvez déterminer le degré de « vivacité » ou d’activité d’un réseau social en fonction du volume d’activité de ses utilisateurs. En outre, vous pouvez identifier les « influenceurs », analyser le comportement des utilisateurs, isoler des groupes cibles à des fins de marketing, etc.
Il faut bien comprendre que cette technologie est relativement nouvelle, même dans l’univers NoSQL. Si une telle base de données semble idéale pour propulser un réseau social, ce ne fut pas le choix des créateurs de Facebook et Twitter, car elle ne répond pas à tous les besoins de ces acteurs : ceux-ci réutilisent des concepts de la théorie des graphes en s’appuyant sur des middlewares plus traditionnels.
En revanche, puisqu’elles sont capables de suivre et de cartographier les réseaux de relations les plus complexes, les bases de données orientées graphes sont de bons outils pour la détection des fraudes. Les connexions entre les éléments qui sont difficiles à détecter avec les bases de données traditionnelles deviennent soudainement proéminentes. De manière générale, elles permettent d’identifier ou de remonter les filières criminelles. Les banques, les forces de l’ordre ou encore les journalistes de l’ICIJ ont recours à cette technologie.
Prosaïquement, ces SGBD orientés graphes s’avèrent de précieux compléments aux moteurs de recommandations quand ils ne les propulsent pas directement, servent à la gestion d’un réseau IT, à l’administration des rôles et des accès dans des SI, à la création de BOM ou de SBOM, ou encore au suivi en temps réel de marchandises.
Plus récemment, les bases de données orientées graphes ont fait leur preuve pour créer des jumeaux numériques et des outils de simulation. Et comme la théorie des graphes est très étroitement liée à la conception de réseaux de neurones, ces SGBD peuvent permettre d’affiner leur conception, de déployer ces modèles de Deep Learning, voire de les rendre plus facilement explicables.
Parmi les bases de données graphes les plus populaires – ainsi que les bases de données multimodèles supportant cette technologie – figurent Neo4j ou TigerGraph qui conviennent à une variété d’objectifs liés aux entreprises, puis Amazon Neptune, Azure Cosmos DB, OrientDB, ArangoDB, etc.
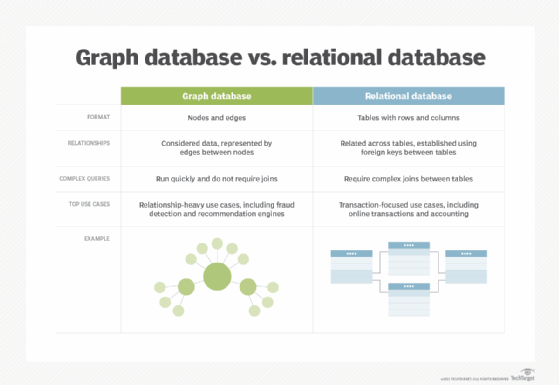
Bases de données graphes vs bases de données relationnelles
Comme nous l’évoquions plus haut, un SGBD orienté graphe bénéficie des attributs de sa famille NoSQL. Un tel système peut à la fois stocker des données non structurées et aider à créer de la cohérence entre des informations parfois très complexes.
Si vous envisagez d’introduire de nouveaux types de relations et de propriétés, pour les placer dans une base de données SQL, vous devrez ajouter de nouvelles tables. À l’inverse, avec une base de données orientée graphes, en traçant les arêtes entre les nœuds, vous pouvez atteindre la profondeur de la relation la plus complexe entre deux nœuds dans une seule base de données.
Toutefois, une base de données orientée graphes est moins pertinente quand les données stockées sont peu corrélées ou connectées entre elles. Dans le cas contraire, un tel SGBD est le terreau idéal pour des usages analytiques avancés et des projets de machine learning.





