
kirill_makarov - stock.adobe.com
IA, machine learning, deep learning : quelles différences ?
Dans le domaine de l’intelligence artificielle, ces trois termes sont souvent utilisés de manière interchangeable, alors qu’ils recouvrent des notions distinctes.

Les termes « intelligence artificielle », « machine learning » (apprentissage automatique ou apprentissage statistique) et « deep learning » (apprentissage profond) se sont popularisés. Ils sont parfois utilisés de manière interchangeable, particulièrement lorsqu’un éditeur cherche à commercialiser ses produits. Pourtant, ils ne sont pas synonymes, et les distinctions sont importantes.
Voici donc une brève comparaison pour bien comprendre les nuances (importantes) entre intelligence artificielle, machine learning et deep learning.
Qu’est-ce que l’intelligence artificielle ?
Le terme d’intelligence artificielle – ou IA – existe depuis les années 50. Pour résumer, il désigne les tentatives pour construire des machines capables de défier l’humain sur ce qui fait sa spécificité : son intelligence.
Mais définir ce qu’est l’« intelligence » n’a jamais été facile. En effet, ce que nous percevons comme intelligent évolue au fil du temps.
Les premiers systèmes d’IA consistaient en des programmes informatiques qui s’appuyaient sur des règles (des moteurs de règles), capables de résoudre des problèmes assez complexes. Plutôt que d’intégrer au code chaque décision que le logiciel était censé prendre, le programme se divisait en une base de connaissances (knowledge base) et un moteur d’inférence. Les développeurs enrichissaient alors la base avec des informations factuelles, et le moteur interrogeait ces dernières pour parvenir à un résultat.
Mais ce type d’IA s’avérait limitée, notamment parce que son apprentissage reposait fortement sur la contribution humaine. Lorsqu’il s’agit d’apprendre et d’évoluer, ces systèmes manquent de flexibilité, et ils ne sont aujourd’hui plus guère considérés comme « intelligents ».
Les algorithmes modernes sont capables d’apprendre à partir de données historiques, ce qui les rend pertinents pour une plus vaste gamme d’applications : robotique, voitures autonomes, optimisation des réseaux électriques, compréhension du langage naturel (NLP), etc.
Si l’IA débouche parfois sur des performances surhumaines dans ces domaines, il nous reste cependant beaucoup de chemin à parcourir avant qu’une IA puisse réellement concurrencer l’intelligence humaine. Pour le moment, aucune IA n’est en mesure d’apprendre comme le font les humains, c’est-à-dire en s’inspirant simplement de quelques exemples. Pour comprendre un sujet, quel qu’il soit, une IA doit s’entraîner sur des montagnes de données (même si cette volumétrie tend à diminuer avec l’IA « frugale »).
Et nous ne disposons encore d’aucun algorithme capable de transférer sa compréhension d’un domaine vers un autre (le transfert learning permet de réutiliser un apprentissage, mais dans le même domaine). Par exemple, si nous apprenons à jouer à StarCraft, nous saurons tout aussi rapidement jouer à StarCraft II. Or, pour une IA, ce sont deux mondes complètement différents : elle devra tout réapprendre pour passer à la version II.
Enfin, l’intelligence humaine est capable de faire des « associations ». Prenons par exemple le mot « humain ». Nous pouvons identifier des humains sur des images ou dans des vidéos. L’IA sait aussi le faire. En revanche, nous savons ce qui se rattache à un humain et ce qui lui est totalement étranger. Jamais nous n’imaginerons qu’un humain puisse avoir quatre roues ou qu’il émette des gaz d’échappement. Ce n’est pas aussi évident pour les IA, aucune ne se rendra compte de ce qui cloche dans ce que je viens d’écrire.
La définition de l’IA est donc mouvante. Et si nous avons été estomaqués par ces algorithmes sophistiqués capables de surclasser des radiologues dans l’interprétation d’IRM, nous avons aussi vu par la suite leurs limites. C’est pour cette raison que, désormais, on distingue l’IA « restreinte », actuelle, d’une IA plus complète, plus « humaine », à savoir « l’intelligence artificielle générale ».
Qu’est-ce que le Machine Learning ?
Le Machine Learning (ML), ou apprentissage automatique, ou apprentissage statistique est un sous-ensemble de l’intelligence artificielle.
Il s’agit d’un ensemble d’algorithmes d’IA développés pour imiter l’intelligence humaine – l’autre type étant l’IA symbolique, dite « intelligence artificielle à l’ancienne », ou GOFAI (Good Old-Fashioned AI), qui désigne les moteurs de règles de type if-then (si… alors…).
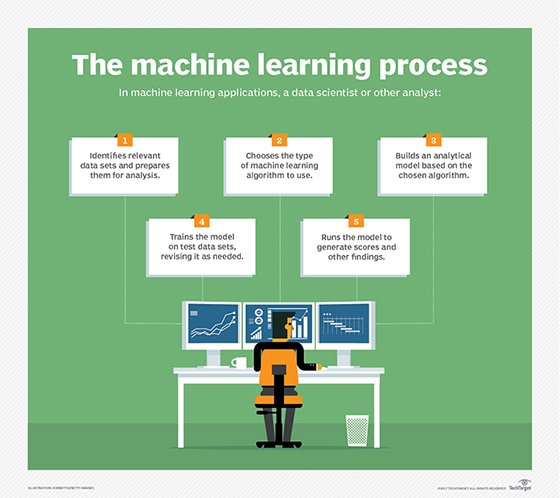
Le machine learning a marqué un tournant dans l’IA. Avant lui, nous tentions d’apprendre aux ordinateurs les moindres détails de chaque décision qu’ils devaient prendre.
Et aujourd’hui encore, un moteur de règles a de nombreux atouts. Le processus est totalement visible et auditable. L’algorithme peut gérer plusieurs scénarios complexes. Sous sa forme la plus évoluée, il examine un très grand nombre de branches dans un arbre décisionnel et trouve celle qui fournit les meilleurs résultats. C’est de cette manière qu’a été conçu le premier système Deep Blue d’IBM pour battre Garry Kasparov aux échecs.
Mais cette forme d’IA a des limites. Dans de nombreux cas, il est impossible de s’appuyer sur un moteur de règles. C’est le cas, par exemple, de la reconnaissance faciale. Ici, un système à l’ancienne devrait détecter différentes formes, telles que des cercles, puis déterminer leur position ainsi que leur imbrication dans d’autres objets, pour reconstituer, par exemple, un œil. Et ne demandez pas aux programmeurs comment ils coderaient pour détecter un nez !
Le machine learning adopte donc une approche radicalement différente : la machine apprend toute seule en ingérant d’énormes quantités de données et en détectant des schémas récurrents. Pour fonctionner, nombre d’algorithmes de ML font appel à des formules statistiques et au Big Data. D’ailleurs, c’est grâce aux avancées en matière de Big Data et à la quantité considérable de données collectées, que le machine learning est devenu opérationnel.
Régression linéaire, régression logique ; arbres décisionnels ; machines à vecteurs de support (SVM) ; classificateur bayésien naïf (Naive Bayes) ; méthode des k plus proches voisins (k-nearest neighbors) ; répartition en K-moyennes (k-means clustering) ; forêts d’arbres décisionnels (random forest) ou encore réduction dimensionnelle sont autant d’exemples d’algorithmes utilisés aujourd’hui dans le domaine du machine learning.
Lire aussi :
Machine Learning : les 9 types d’algorithmes les plus pertinents en entreprise
Le machine learning devient la priorité de bon nombre d’entreprises. Elles veulent modéliser d’importants volumes de données. Le choix du bon algorithme dépend des objectifs à atteindre et de la maturité de votre équipe de Data Science.
Comment construire un modèle de Machine Learning en 7 étapes
Il faut de la patience, de la préparation et de la persévérance pour construire un modèle de machine learning viable, fiable et agile qui rationalise les opérations et renforce les métiers.
Les 5 conseils d’une super star de l’IA pour déployer le machine learning en entreprise
Le pionnier – et superstar – de l’IA Andrew Ng a partagé les enseignements de ses expériences de responsables chez Google et Baidu. Il livre un mode d’emploi dont toute entreprise pourra s’inspirer avec bénéfices.
Qu’est-ce que le deep learning ?
Le deep learning (DL) est un sous-ensemble du machine learning. Si cette approche implique toujours que la machine apprenne à partir de données, elle constitue un nouveau jalon important dans l’évolution de l’IA.
Le deep learning a été développé à partir de notre connaissance des réseaux neuronaux.
L’idée d’élaborer une IA qui repose sur des réseaux neuronaux remonte aux années 80, mais ce n’est qu’à partir de 2012 que le deep learning a réellement percé. Tout comme le machine learning doit son essor au big data, le deep learning doit son adoption à la puissance de calcul devenue disponible à moindre coût (ainsi qu’aux avancées de ses algorithmes).
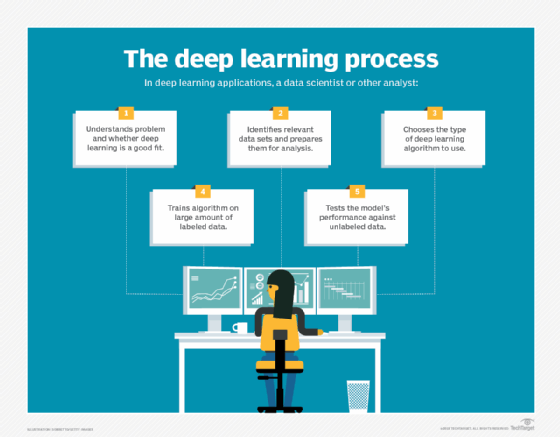
Le deep learning a permis des résultats bien plus intelligents que ceux rendus à l’origine par le machine learning. Reprenons notre exemple de reconnaissance faciale : pour détecter un visage, quel type de données devons-nous fournir à l’IA ? Et comment celle-ci doit-elle apprendre ce qu’il faut chercher, sachant que nous ne pouvons fournir, pour seule information, que des couleurs de pixels ?
Le deep learning fait appel à des couches de traitement, chacune intégrant progressivement des représentations de données de plus en plus complexes. Les premières couches peuvent apprendre les couleurs, les suivantes les formes, puis celles qui suivent des combinaisons de ces formes, pour aboutir enfin à des objets réels. Le deep learning s’est révélé révolutionnaire dans la reconnaissance des objets.
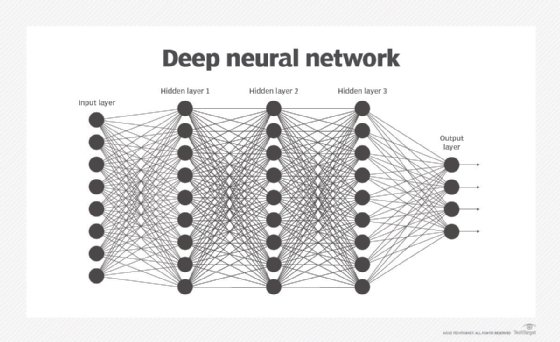
En outre, son invention a permis à l’IA de progresser rapidement sur plusieurs fronts, dont la compréhension du langage naturel.
Le deep learning représente actuellement l’architecture d’IA la plus sophistiquée. Réseaux neuronaux convolutifs, réseaux neuronaux récurrents, réseaux à mémoire court terme étendue (LSTM, Long Short-Term Memory), réseaux antagonistes génératifs et réseaux de croyance profonds sont autant d’exemples d’algorithmes de deep learning.
Conclusion
Contrairement au concept large d’IA, les deux termes que sont le machine learning et le deep learning ont des définitions claires.
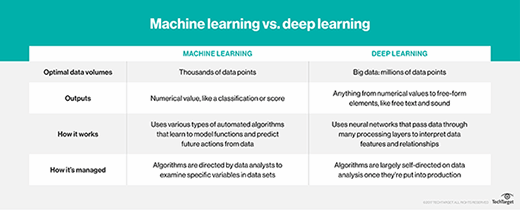
Ce que nous considérons comme de l’IA évolue au fil du temps. Par exemple, la reconnaissance optique des caractères (OCR, Optical Character Recognition) appliquée à la gestion des factures était considérée comme de l’IA, ce qui n’est plus toujours le cas. En revanche, un algorithme de deep learning entraîné sur des milliers de lignes d’écritures manuscrites et capable d’apprendre à les convertir en texte dactylographié sera, selon la définition actuelle, considéré comme une IA.
Machine learning et deep learning représentent deux étapes particulièrement importantes dans l’évolution de l’intelligence artificielle. Et il y en aura sans doute bien d’autres sur la voie qui nous mène vers ce que nous appelons aujourd’hui l’intelligence artificielle générale.
Lire aussi :
Machine Learning vs Deep Learning ? La même différence qu’entre un ULM et un Airbus A380
Le Deep Learning partage certaines caractéristiques avec l’apprentissage statistique traditionnel. Mais les utilisateurs expérimentés le considèrent comme une catégorie à part entière avec une conception de modèles prédictifs et des résultats bien différents.
Deep Learning et apprentissage par renforcement repoussent les limites de l’IA
L’association de ces deux types d’intelligence artificielle promet de donner naissance à des applications encore plus évoluées.
Machine Learning, Deep Learning, AI, Informatique cognitive : quelles différences ?
Ces termes sont de plus en plus employés par les éditeurs et leurs partenaires. Emmanuel Vignon, Watson Practice Leader chez IBM France revient sur ce que recouvre chacun de ces concepts, et comment ils s’articulent.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
Un ingénieur en IA peut gagner 120 000 euros par an
Par: Philippe Ducellier
-
![]()
Avec CortAIx, Thales veut industrialiser l’IA dans les systèmes critiques
Par: Gaétan Raoul
-
![]()
IA, machine learning, deep learning, IA générative : quelles différences ?
Par: Gaétan Raoul
-
![]()
L’IA générative débarque massivement dans les applications métiers
Par: Philippe Ducellier



