Gestion de flux de données : une introduction à Apache Airflow
Cette introduction à Apache Airflow passe en revue certaines des bases de l’outil de gestion de flux de travail – des étapes d’installation aux différentes options de l’interface graphique en passant par quelques conseils pour l’utiliser au quotidien.
Apache Airflow est un outil de gestion de flux de travail open source imaginé par Airbnb. Les équipes IT peuvent l’utiliser pour rationaliser le traitement des données, les flux ETL, mais également les pipelines DevOps.
Basé sur Python et reposant sur une base de données SQLite, Airflow permet aux administrateurs de gérer les workflows de manière programmatique et de surveiller les tâches planifiées. Dans cette présentation, nous couvrons l’installation de l’outil, les intégrations, les concepts de base et les commandes clés. Ensuite, nous créerons un exemple de tâche avec Python et nous présenterons les interfaces graphiques d’Airflow avant de fournir quelques conseils pour l’utiliser au quotidien.
Apache Airflow : qu’est-ce que c’est ?
Apache Airflow définit ses workflows sous forme de code. Les travailleurs d’Airflow exécutent des tâches dans le flux de travail, et une série de tâches est appelée un pipeline. Pour ce faire, Airflow utilise des graphes acycliques dirigés (DAG). Une exécution DAG est une instance individuelle d’une tâche codée active. Les pools contrôlent le nombre de tâches simultanées afin d’éviter une surcharge du système.
Les workflows sont créés dans le fichier DAG, qui permet de déclarer les flux en Python. Les étapes et leur ordre sont définis dans cet objet. Il faut veiller à ce que les tâches d’un workflow soient définies au bon endroit, car elles surviennent normalement pendant l’exécution.
Comment installer Apache Airflow ?
Concernant l’installation d’Apache Airflow, il n’y a pas de fichier tar ou de paquet .deb à télécharger et à installer, comme c’est le cas avec d’autres outils tels que Salt, par exemple.
Au lieu de cela, les utilisateurs installent toutes les dépendances du système d’exploitation via l’installateur de paquets Python pip, comme les paquets build-essential, qui comprennent les fichiers du noyau, les compilateurs, les fichiers .so et les fichiers d’en-tête. Ensuite, ils installent un seul paquet Python. Consultez la documentation d’Airflow pour obtenir la liste complète des dépendances.
Les dépendances d’Airflow varient, mais l’ensemble comprend :
- sudo apt-get install -y --no-install-recommends \
- freetds-bin \
- krb5-user \
- ldap-utils \
- libffi6 \
- libsasl2-2 \
- libsasl2-modules \
- 1 \
- locales \
- lsb-release \
- sasl2-bin \
- sqlite3 \
- unixodbc
Commencez la procédure d'installation avec la commande suivante :
pip install apache-airflow
Ensuite, initialisez la base de données SQLite, qui contient les métadonnées des flux de travail :
airflow initdb
Puis, démarrez Airflow :
airflow webserver -p 8080
Enfin, ouvrez le serveur web via le localhost:8080.
Ne faites pas fonctionner le système via le serveur web, car il est destiné uniquement à la surveillance et au réglage. Au lieu de cela, utilisez les modèles Python et Jinja insérés dans le code Python de Airflow pour exécuter ces tâches à partir de la ligne de commande. Jinja existe dans le code Python, mais ce n’est pas une commande Python.
Les utilisateurs peuvent également ajouter des paquets supplémentaires, et Airflow offre une variété d’intégrations possibles. Par exemple, il est possible de connecter Hadoop via la commande pip install apache-airflowhdfs, pour travailler avec le système de fichiers distribués Hadoop.
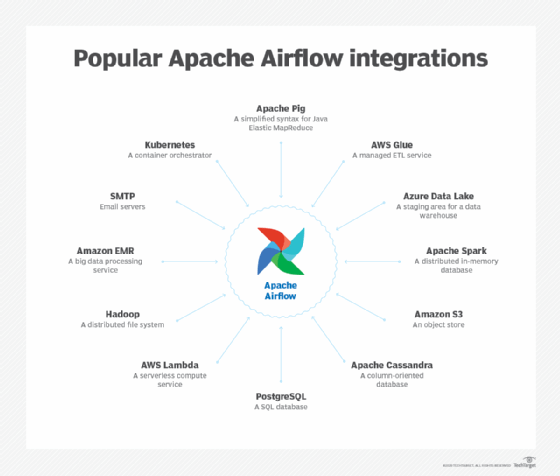
Les intégrations avec Apache Airflow
Airflow fonctionne avec des commandes bash, ainsi qu’avec un large éventail d’autres outils. Par exemple, certaines des intégrations d’Airflow incluent Kubernetes, AWS Lambda et PostgreSQL. D’autres intégrations sont notées dans l’image ci-dessous.
Les commandes Airflow
Airflow fonctionne à partir d’une interface en ligne de commande.
Les principales commandes que les utilisateurs potentiels doivent connaître sont les suivantes :
- airflow run pour exécuter une tâche ;
- airflow task pour réparer une tâche ;
- airflow backfill pour exécuter une partie d'un DAG suivant la date ;
- airflow webserver pour lancer l'interface graphique ;
- airflow show_dag pour visualiser les tâches et leurs dépendances.
Les utilisateurs définissent les tâches en Python. Bien qu’ils n’aient pas besoin de beaucoup de connaissances en programmation pour utiliser Airflow – parce qu’ils peuvent copier des templates – la connaissance de ce langage est un avantage certain. Par exemple, les utilisateurs doivent savoir comment utiliser les objets datetime et timedelta.
Les utilisateurs qui connaissent bien Python peuvent étendre les objets Airflow pour écrire leurs propres modules.
Quelques tâches simples dans Airflow
Vous trouverez ci-dessous une version simplifiée de l’exemple de tâche Python présenté dans la documentation Apache Airflow, avec des sections de code expliquées tout au long du document.
Cette tâche comporte trois opérations, la première dépendant des deux suivantes. Les dépendances sont intrinsèques à l’approche DevOps, car elles permettent à certaines tâches de s’exécuter – ou de ne pas s’exécuter – en fonction des résultats d’autres tâches.
Cela permet aux administrateurs informatiques d’exécuter plusieurs étapes DevOps avec une dépendance sur chacune d’entre elles. Les commandes Bash exécutent des tâches simples – et complexes – telles que la copie de fichiers, le démarrage d’un serveur ou le transfert de fichiers. Par exemple, ce script peut copier un fichier dans une zone de stockage Amazon Glue, mais seulement si l’étape précédente, par exemple la récupération de ce fichier sur un autre système, s’est déroulée avec succès.
Les arguments du constructeur DAG sont présentés dans la figure 2. Cet exemple utilise l’opérateur BashOperator, car il exécute une simple commande bash. Tous les opérateurs sont des extensions de la commande BaseOperator. En outre, les autres API majeures comprennent BaseSensorOperators, qui écoute les événements provenant d’une intégration – par exemple, Amazon Glue – et Transfers, qui transfère les données entre les systèmes.

Le code ci-dessus utilise Jinja, un langage de programmation de macros très répandu. Jinja transmet les macros et les paramètres à BashOperator et à d’autres objets Python par le biais d’une syntaxe compacte.
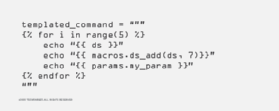
Par exemple, templated_command est une macro Jinja complète. Elle est introduite dans l’objet BashOperator. Comme le montre la figure 3, elle s’exécute 5 fois et répercute la valeur du paramètre params.my_param de l’objet BashOperator t3.

La dernière section de la figure 4, t1 >> [t2, t3], indique à Airflow de ne pas exécuter la tâche 1 tant que les tâches 2 et 3 n’ont pas été menées à bien.

La section de code de la figure 5 – tirée du segment de la figure 1 qui précède les commandes t3 – crée une démarcation markdown pour écrire la documentation qui s’affichera dans l’interface graphique.
Markdown est la syntaxe utilisée par GitHub et d’autres systèmes pour créer des liens, établir des listes à puces et afficher des caractères gras, par exemple, pour créer un affichage contenant de nombreuses informations pertinentes sur les tâches.
L'interface graphique d'Apache Airflow
Exécutez l’interface graphique à partir de la ligne de commande avec la commande Python airflow webserver et une interface REST. Utilisez l’interface graphique pour la surveillance et le réglage fin.
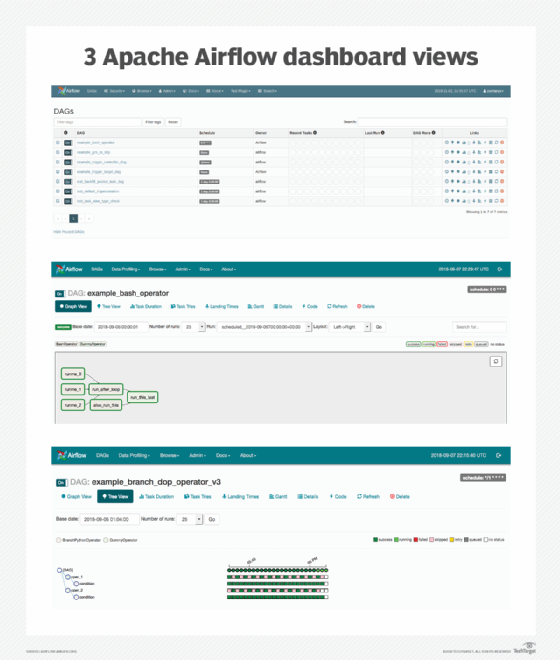
Chaque DAG, ou tâche, est disponible sous forme de liste sur l’écran DAGs de l’interface graphique. Mais les utilisateurs disposent également d’autres options d’affichage, telles que la vue arborescente, qui affiche les DAG dans le temps, par exemple, lorsqu’ils s’exécutent, s’arrêtent et attendent. Rappelez-vous que chaque DAG est associé à une heure de démarrage. Une autre option d’affichage est la vue Graph, car les DAG sont un concept informatique qui représente des éléments dans un objet arborescent. Le graphique de la figure 6 montre les tâches, leurs dépendances et leur état actuel.
D’autres écrans sont disponibles :
- Variable View, qui affiche certaines variables, comme les informations d’identification ;
- Gantt Chart, qui montre la durée et le chevauchement des tâches ;
- Task Duration, qui montre la durée de la tâche ;
- Code View, qui affiche le code python de chaque tâche du pipeline ;
- Task Instance Context Menu, qui affiche les métadonnées de la tâche.
Quelques conseils pour prendre en main Airflow
Le fichier DAG a pour fonction de définir le flux de travail et non de contrôler les tâches. Si le fichier devient trop volumineux parce que les tâches ne sont pas correctement définies, le système est freiné. Le fichier doit donc être allégé au maximum. Dans le cadre de la planification horaire, il faut en outre veiller à ce que les indications horaires de l’interface web et des workflows concordent. L’UTC est réglé par défaut, mais il est possible de définir un fuseau horaire personnalisé dans l’interface.
Il est également possible de faire démarrer des workflows à la même heure, même s’il s’agit de workflows qui se chevauchent, c’est-à-dire de workflows qui peuvent s’influencer mutuellement. Airflow offre ici l’option de définir un ordre de priorité avec le paramètre priority_weight. Ce paramètre peut être défini pour chaque tâche d’un workflow. Outre le temps, les workflows peuvent se baser sur des événements.
Si les workflows ne peuvent actuellement pas être exécutés, il est judicieux de les mettre en pause dans Airflow. Si le système ne peut pas exécuter certains workflows, il essaie automatiquement de redémarrer le workflow dès que cela est possible. Cela peut entraîner une surcharge des serveurs. Si la reprise des workflows n’est pas souhaitée, il est possible de travailler avec le paramètre catchup=False dans la configuration des workflows. Si seul le workflow actuel doit être exécuté, cela est également disponible dans la configuration.
Pour maintenir à jour les workflows et les scripts Python qui leur sont associés, il est judicieux de miser sur un dépôt Git pour les scripts. L’outil utilise le répertoire dags pour charger les fichiers. Dans ce répertoire, il convient de lier des sous-répertoires au dépôt Git. La synchronisation entre le répertoire et le référentiel peut à son tour être gérée par un workflow interne dans Airflow. D’autres fichiers nécessaires peuvent également être synchronisés par ce biais.
De nombreuses données dans un workflow peuvent être définies avec des variables plutôt qu’avec des valeurs fixes. Cela améliore la flexibilité, car un workflow peut être dupliqué ou recréé plus rapidement. Les variables sont disponibles via l’interface en ligne de commande (CLI), une API et dans l’interface web. Le stockage des variables se fait dans la méta-base de données. Ainsi, les informations sont rapidement disponibles lorsque le flux de travail en a besoin. Il est en outre possible de regrouper des variables via des objets JSON.
L’exploitation d’Airflow peut se faire de différentes manières. Chez de nombreux fournisseurs de cloud, l’outil est disponible sous forme de services. Pour l’exploitation locale, il est possible de procéder à une installation traditionnelle sur un serveur ou de l’exploiter en tant que conteneur Docker.
Pour approfondir sur Middleware et intégration de données
-
![]()
Data Platform en mode produit : mode d’emploi et bénéfices en industrialisation
Par: Christophe Auffray
-
![]()
« Nous ne prévoyons pas de bâtir notre propre moteur analytique » (Tristan Handy, dbt Labs)
Par: Gaétan Raoul
-
![]()
Ingestion, transformation, streaming : Snowflake accélère le rythme
Par: Gaétan Raoul
-
![]()
Fabric : face à Snowflake et Databricks, Microsoft met les bouchées doubles
Par: Gaétan Raoul



