
Hoda Bogdan - stock.adobe.com
Comment exécuter des LLM sur site : matériels, outils et bonnes pratiques
Les déploiements locaux de grands modèles de langage offrent des avantages, notamment en matière de confidentialité, de rapidité et de personnalisation, mais les entreprises ont besoin des outils et de l’infrastructure adéquats pour réussir.
Bien que de beaucoup d’entreprises s’appuient sur des services de cloud public pour héberger de grands modèles de langage, il existe des raisons impérieuses d’exécuter ces modèles en interne, depuis un centre de données en propre.
Cependant, les organisations doivent tenir compte d’un certain nombre de facteurs lorsqu’elles décident d’exécuter des LLM sur site. Tout d’abord, elles doivent évaluer les exigences en matière d’infrastructure, telles que le nombre de GPU nécessaires pour répondre aux impératifs du cas d’usage envisagé. En outre, il existe un écosystème croissant d’outils et de modèles pour soutenir l’autohébergement des LLM. Qu’il s’agisse de permettre aux utilisateurs d’exécuter des modèles sur des ordinateurs, des mobiles ou des tablettes sans exploiter de GPU dédié, ou de propulser les applications multi-utilisateurs à grande échelle.
Les avantages de l’exécution de LLM sur site
Il y a plusieurs raisons pour lesquelles une organisation peut choisir d’exécuter un LLM sur une infrastructure privée, plutôt que d’utiliser un cloud public – en particulier, au regard des questions de sécurité et de performance.
Les LLM hébergés dans un environnement public peuvent exposer les données sensibles à un risque accru de vulnérabilités en matière de sécurité. Les LLM hébergés dans le cloud nécessitent également une connectivité Internet constante, ce qui peut entraîner des problèmes de latence et de performance. L’exécution locale d’un LLM offre aux utilisateurs un meilleur contrôle, renforce la protection de la vie privée et peut optimiser les performances du modèle.
Certains secteurs, tels que les soins de santé, l’armée et d’autres environnements très réglementés, pourraient bénéficier tout particulièrement des LLM hébergés sur site. Imaginez, par exemple, qu’un établissement hospitalier utilise localement des LLM entraînés sur mesure pour aider au diagnostic des patients ou gérer les interactions avec eux tout en protégeant la confidentialité des informations médicales sensibles.
Les déploiements Edge sont par ailleurs souhaitables dans un certain nombre d’usages industriels. Dans les endroits éloignés ou isolés, tels que les plates-formes pétrolières, les usines de fabrication, ou encore pour les véhicules autonomes, les LLM hébergés localement peuvent offrir une aide à la décision en temps réel sans dépendre d’un système distant.
Exigences en matière d’infrastructure
Lors de l’hébergement sur site d’un LLM, l’une des premières exigences à prendre en compte est la capacité du GPU. Les LLM sont gourmands en calculs et nécessitent une quantité de mémoire GPU importante pour stocker les paramètres du modèle et les données intermédiaires pour l’inférence. (mémoire GPU appelée Video Random Access Memory, VRAM, du fait du rôle primaire des cartes graphiques qui est de produire une image affichable sur un écran.)
Les GPU sont optimisés pour des performances élevées et fournissent la vitesse et la bande passante nécessaires à l’exécution efficace des LLM. Ce matériel peut gérer les calculs complexes des LLM sans être gêné par des goulets d’étranglement dans les transferts de données entre la mémoire et le processeur.
Une règle générale pour dimensionner le déploiement d’un LLM est de multiplier la taille du modèle – en milliards de paramètres – par 2, puis d’ajouter 20 % afin de prendre en compte une éventuelle surcharge. Ce calcul fournit la quantité de mémoire GPU nécessaire pour charger complètement le modèle en mémoire.
Par exemple, le modèle VLM Llama-3.2-11B de Meta, avec 11 milliards de paramètres, nécessite au moins 26,4 Go de VRAM – 11 x 2 + 20 %. Il est donc recommandé d’utiliser une carte GPU comme la Nvidia A100, plus particulièrement dotée de 40 Go de VRAM HBM2e, afin de disposer de ressources suffisantes pour le stockage des modèles et le traitement de l’inférence (les fournisseurs de LLM exploitent habituellement une variante de l’A100 dotée de 80 Go de VRAM HBM2e, plus adaptés à l’entraînement des modèles).
Si l’A100 n’est pas en fin de vie, il est plus facile de trouver (quand elles sont en stock) des cartes Nvidia L40S, dotées de 48 Go de VRAM GDDR6 (une VRAM un peu moins rapide).
Pour les déploiements Edge, une station de travail peut suffire. Dans ce cas-là, c’est vers la RTX 6000 ou A6000 qu’il convient de se tourner. Si elles disposent de moins de cœurs adaptés aux traitements IA, ces cartes embarquent 48 Go de VRAM GDDR6, ce qui est amplement suffisant pour l’inférence de modèles de taille moyenne.
Pour les déploiements avec un grand nombre d’utilisateurs, les besoins en GPU sont encore plus élevés.
Selon Fujitsu, un GPU Nvidia L40S supporte jusqu’à 500 requêtes par seconde. Dans les serveurs des assembleurs (Fujistu, Dell, HPE, Lenovo, etc.), les GPU sont généralement installés par deux, quatre ou huit. Un seul serveur doté de L40S suffirait donc à couvrir les besoins de « centaines, voire de milliers d’utilisateurs ».
Précisons que les capacités du GPU n’agissent pas seulement sur le nombre de requêtes par seconde, mais également (et surtout) sur la fenêtre de contexte, c’est-à-dire la quantité de tokens en entrée et en sortie (la taille du fichier texte, audio, vidéo, PDF ingéré ou produit) et la « mémoire » du LLM (sa capacité à se souvenir des précédentes interactions), ainsi que sur la vitesse de génération du résultat, exprimée en tokens par seconde (ou en image par seconde pour un modèle de diffusion).
Malheureusement, il n’existe pas de formule exacte qui permette de calculer les besoins en GPU pour une charge de travail de production, car ils dépendent largement du cas d’usage. Une approche pratique consiste à commencer par des tests à petite échelle, à mesurer l’utilisation moyenne de la mémoire du GPU et à utiliser ces données pour prévoir la capacité nécessaire à un déploiement complet.
Comment exécuter des LLM localement
Les entreprises peuvent également déployer des LLM directement sur les appareils des utilisateurs finaux à l’aide d’outils et de services spécialisés qui les prennent en charge. Ces outils permettent non seulement aux utilisateurs individuels d’exécuter des modèles, mais fournissent également un ensemble d’API normalisées que les développeurs peuvent utiliser pour créer des logiciels tels que des applications de génération augmentée par extraction (RAG).
Voici quelques outils populaires pour le déploiement local :
- Ollama.
- GPT4All.
- LM Studio.
Par exemple, Ollama (disponible sur macOS, Linux et Windows) fournit une interface de ligne de commande simple pour télécharger et exécuter des modèles optimisés à partir du référentiel d’Ollama. Avec les commandes ollama pull llama3.2 et ollama run llama3.2, les utilisateurs peuvent télécharger le modèle Llama 3.2 de Meta, créer un point de terminaison API et lancer une session interactive avec le modèle.

En outre, l’API d’Ollama s’intègre à d’autres outils, tels que AnythingLLM et Continue, une extension de Visual Studio Code qui peut servir d’alternative à GitHub Copilot.
AnythingLLM permet d’intégrer du contenu. Cela permet aux utilisateurs d’ajouter leurs propres données – telles que des PDF, des fichiers Microsoft Word ou des images – et d’engager ensuite des discussions interactives avec leurs données sur leur appareil.
LM Studio sur macOS : petit retour d’expérience du MagIT
LM Studio fonctionne également sur macOS. Les tests du MagIT ont permis de déterminer que l’outil peut exécuter Mixtral 8x7B avec une fenêtre de contexte de 32 000 tokens sur un MacBook Pro 13 pouces Apple M1 Max, CPU 10 cœurs et GPU 32 cœurs, doté de 64 Go de RAM. Ici, point de VRAM : la mémoire vive est partagée entre le CPU et le GPU. Dans ce contexte, le CPU est très peu sollicité (1 %), tandis que le processeur graphique est pleinement utilisé, ce qui enclenche rapidement les ventilateurs de la machine.
Les outils pour les déploiements multi-utilisateurs sur site
Les outils comme Ollama fonctionnent bien pour les sessions à utilisateur unique, mais une approche différente est nécessaire afin d’aborder l’échelle des modèles centralisés desservant plusieurs utilisateurs. De nombreux outils sont disponibles pour gérer les déploiements LLM multi-utilisateurs, notamment vLLM, Text Generation Inference (TGI) et Nvidia Triton Inference Server.
VLLM peut fonctionner sur un seul serveur avec ou sans GPU. Il peut également évoluer vers des configurations multinœuds et multi-GPU en utilisant le parallélisme tensoriel, une technique qui répartit un modèle volumineux sur plusieurs GPU. Par exemple, un modèle aussi grand que Llama-3.2-90B nécessiterait au moins 216 Go de VRAM – 90 x 2 + 20 % d’espace libre pour les pics de charge.
Même la carte GPU la plus puissante de Nvidia, la H200 de 141 Go, ne disposerait pas d’une mémoire suffisante pour contenir ce modèle, ce qui obligerait tout déploiement à utiliser plusieurs cartes et le parallélisme tensoriel. La configuration de déploiements plus importants sur plusieurs nœuds physiques nécessite également une connectivité à haut débit. Si Nvidia pousse ses switchs et cartes Infiniband, Meta a prouvé qu’un système RoCE suffit, même à très large échelle. En revanche, il sera sans doute plus complexe à déployer.
Un marché des GPU en expansion
Bien que cet article se concentre principalement sur les GPU Nvidia, la prise en charge d’autres fournisseurs de GPU, tels qu’AMD et Intel, est de plus en plus importante. Les coûts de déploiement pouvant varier selon le fournisseur de matériel, les entreprises doivent s’assurer de la compatibilité avec leur fournisseur de GPU préféré lorsqu’elles choisissent un outil afin d’éviter des dépenses non souhaitées.
VLLM peut également fonctionner au-dessus de Kubernetes, ce qui permet aux utilisateurs de mettre en œuvre un modèle de service d’inférence prêt à la production, qui peut tirer parti des avantages de l’orchestrateur de conteneurs tels que l’évolutivité et une plus grande disponibilité. Ray, un framework unifié pour la mise à l’échelle des applications IA et Python porté par Anyscale, peut être utilisé pour faciliter le calcul distribué lors de l’utilisation de vLLM avec l’inférence multinœud.
Lors de l’hébergement de vLLM dans un environnement Kubernetes, l’équilibrage de la charge des API est essentiel, car chaque instance de vLLM s’exécute avec son propre point de terminaison. Les équipes peuvent utiliser les capacités intégrées d’équilibrage de charge HTTP de Kubernetes ou un service proxy externe, tel que LiteLLM. Étant donné que vLLM sur Kubernetes nécessite un accès direct aux GPU, qu’il ne voit pas de manière native, les plug-ins de périphériques Nvidia doivent être installés pour rendre les GPU accessibles aux instances vLLM conteneurisées.
Avec vLLM en place, les équipes peuvent créer des applications et des services personnalisés en utilisant des frameworks d’intégration comme LangChain. La même configuration peut également prendre en charge des tâches d’entraînement telles que le fine-tuning, comme le montre l’illustration ci-dessous.
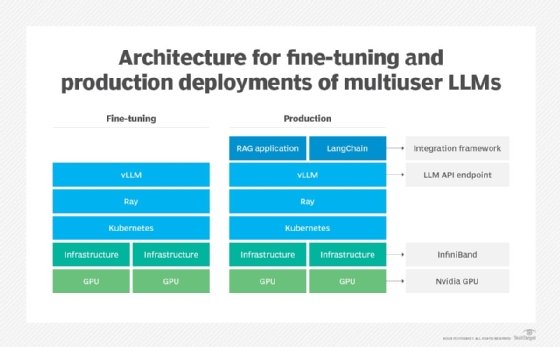
Une autre option pour les LLM multi-utilisateurs est Nvidia AI Enterprise, qui fournit une pile similaire à celle de vLLM, y compris Ray. Ce service commercial est toutefois plus onéreux.
Optimiser la consommation de VRAM
Peu importe l’équipement cible du déploiement, il existe également des techniques d’optimisation logicielle, par exemple la quantization ou (quantification en français), consistant à réduire la précision des nombres flottants utilisés par les paramètres des LLM afin qu’il consomme moins de puissance de calcul au détriment de la pertinence des réponses (souvent en passant de bfloat 16 à bfloat 8). La technique est toutefois de plus en plus maîtrisée par les fournisseurs de LLM qui apportent d’ailleurs des conseils sur son utilisation.
Aussi, les chercheurs s’appuient sur l’algorithme/librairie FlashAttention pour l’entraînement et l’inférence. Celui-ci accélère le mécanisme d’attention des transformers (l’architecture sous-jacente des LLM) en minimisant les lectures et écritures en mémoire et donc la VRAM sollicitée. VLLM, TGI et TensorRT (la librairie s’exécutant par-dessus le backend Triton) prennent nativement en charge FlashAttention 2. FlashAttention 3, bien plus performant, est également disponible en bêta via PyTorch, mais est pour l’instant optimisé pour les GPU H100 et prend en charge de manière limitée les AMD MI200 et MI300.
Marius Sandbu est un évangéliste cloud pour Sopra Steria en Norvège, qui se concentre principalement sur l’informatique pour l’utilisateur et les technologies cloud-native.
Pour approfondir sur Hardware IA (GPU, FPGA, etc.)
-
![]()
Mistral 3 : Mistral AI veut faire jeu égal avec ses compétiteurs chinois
Par: Gaétan Raoul
-
![]()
Granite 4.0 : IBM veut écraser la concurrence sur le terrain de l’inférence
Par: Gaétan Raoul
-
![]()
VMware Explore 2025 : VCF 9 devient une infrastructure pour l’IA
Par: Yann Serra
-
![]()
Gpt-oss : six ans après GPT-2, OpenAI dégaine ses modèles « open weight »
Par: Gaétan Raoul



