Comment construire un modèle de Machine Learning en 7 étapes
Il faut de la patience, de la préparation et de la persévérance pour construire un modèle de machine learning viable, fiable et agile qui rationalise les opérations et renforce les métiers.

Les applications concrètes du Machine Learning sont de plus en plus nombreuses. Parmi les plus populaires, on trouve par exemple l’analyse prédictive, la reconnaissance de formes (au sens large), les systèmes autonomes, les systèmes conversationnels (dont les chatbots) ou encore l’hyperpersonnalisation. La liste est évidemment non exhaustive. Ces usages diffèrent selon les types d’organisations (ETI, grand groupe, PME, startup, service public, etc.), les domaines (finance, marketing, RH, etc.), les secteurs et les objectifs.
Mais ils ont tous un point commun : ils partent de la bonne compréhension d’un problème opérationnel – les données et les algorithmes seront sélectionnés en fonction. C’est de cette manière, peu importe le domaine, qu’un modèle de machine learning (ML) connaîtra le succès.
Le déploiement et le suivi de ces projets suivent aussi généralement un schéma commun. Ceci étant, les méthodes de développement d’applications « traditionnelles » ne s’appliquent pas, ou très mal, à ces projets. Pour une raison simple : le cœur de l’Intelligence Artificielle se trouve dans les données (ils sont « data driven ») et pas dans l’écriture du code. Car l’apprentissage – bon ou mauvais – découle en très grande partie de ces données.
Les bonnes approches se concentrent donc d’abord sur les besoins (métiers) et sur les données (disponibles). Il en résulte des projets qui ne négligent pas – au contraire – les étapes de découverte des données (data discovery), de nettoyage (cleansing), d’apprentissage, de construction du modèle. Sans oublier l’itération. Encore et toujours.
Si pour de nombreuses organisations, faire du machine learning est nouveau, la méthodologie et les grandes lignes des projets sont néanmoins déjà bien établies.
Il y a 25 ans déjà, un consortium de cinq acteurs a développé le Cross-Industry Standard Process for Data Mining (CRISP-DM), qui s’appuie sur une itération continue des différentes étapes d’un projet de Data Mining. Cette méthode débute par une boucle entre la « compréhension du métier » et la « compréhension des données ». Elle passe à une autre boucle entre la « préparation des données » et « la modélisation ». Puis vient une phase d’évaluation, dont les résultats sont, d’une part, appliqués dans le déploiement et, d’autre part, partagés pour améliorer la compréhension métiers (retour à l’étape 1). Cette boucle, cyclique et itérative, conduit à une modélisation des données, à une préparation et à une évaluation, toutes trois continues.
Mais CRISP-DM s’est arrêté à sa version 1.0, il y a vingt ans. Des rumeurs sur une v2 ont débuté il y a près de 15 ans. Depuis, rien. IBM et Microsoft s’en sont néanmoins inspirés pour faire leurs propres variantes – des versions qui ajoutent par exemple des précisions aux boucles itératives entre le traitement des données (data processing) et la modélisation, ou plus de détails sur les livrables à produire au cours du processus.
Ceci étant, malgré ses qualités, cette méthode a été critiquée sur deux points. Primo, elle n’est pas particulièrement agile. Et deusio, elle n’est pas spécifique aux projets d’IA.
D’autres méthodes, comme la Cognitive Project Management for AI, ont été améliorées pour répondre aux spécificités du machine learning et peuvent être mises en œuvre par des organisations qui ont déjà des équipes de développement agile.
Ces méthodes types, ainsi que les enseignements que l’on a tirés des chantiers de data science des grandes entreprises, aboutissent aujourd’hui à une approche plus robuste, plus flexible, et plus progressive (étape par étape).
Voici les sept étapes clés qui résultent de ces expériences pour construire un bon modèle de Machine Learning.
Étape 1. Comprendre et identifier le problème du métier (et définir ce que sera « la réussite »)
La première phase de tout projet de machine learning consiste à comprendre les besoins des métiers. C’est une évidence, mais répétons-la : vous devez savoir quel problème vous essayez de résoudre avant de tenter de le résoudre.
Pour commencer, travaillez avec le référent du projet (le « project owner ») et assurez-vous bien que vous comprenez parfaitement ses objectifs et ses besoins. Le but est de traduire cette connaissance en une définition mathématique appropriée du problème pour faire du machine learning, et de concevoir un plan préliminaire pour atteindre ces objectifs.
Les questions clés auxquelles il faut répondre sont :
- Quel est l’objectif métier qui aurait besoin d’une solution cognitive ?
- Un moteur de règles ne peut-il pas répondre à cet objectif ?
- Quelles parties de la solution sont cognitives et lesquelles ne le sont pas ?
- Toutes les questions techniques, opérationnelles et de déploiement ont-elles été abordées ?
- Quels seront les critères d’un projet « réussi » ?
- Comment le projet peut-il être mis en place dans le cadre de sprints itératifs ?
- Y a-t-il des exigences particulières en matière de transparence, d’explicabilité ou de réduction des biais ?
- Quelles sont les considérations éthiques ?
- Quels sont les paramètres et valeurs « acceptables » en termes de précision, d’exactitude, et pour la matrice de confusion ?
- Quelles données d’entrée (les « inputs ») pourront être injectées dans le modèle ? Et quelles sont les valeurs de sortie (les « outputs ») attendues ?
- De quel type est le problème à résoudre ? S’agit-il d’un problème de classification, de régression ou de regroupement/segmentation ?
- Qu’est-ce que la solution « tout venant » (« l’heuristique »), c’est-à-dire l’approche rapide, mais peu efficace pour résoudre le problème, qui ne nécessiterait pas de ML ? Dans quelle proportion le modèle doit-il être meilleur que l’heuristique ?
- Comment les retombées et les bénéfices du modèle seront-ils mesurés et chiffrés ?
Bien que les questions soient nombreuses lors de cette première étape, y répondre (ou même tenter d’y répondre) augmentera considérablement les chances de réussite du projet.
La définition d’objectifs précis, et quantifiables, permettra d’avoir un ROI mesurable du projet – c’est ce qui fait aussi la différence entre la mise en production du machine learning et la mise en œuvre d’un simple PoC qui sera abandonné par la suite.
Ces objectifs doivent toujours être intimement liés aux objectifs des métiers. Ils ne peuvent pas être purement « statistiques ». Des indicateurs naturels du machine learning – comme la précision, l’exactitude, le rappel et l’erreur quadratique moyenne – peuvent être inclus dans les métriques du projet. Mais des KPI (indicateurs clés de performance) plus « métiers » sont largement préférables.
Étape 2. Comprendre et identifier les données
Une fois que vous avez bien compris les demandes des métiers et que votre projet a été approuvé, vous vous dites que vous allez pouvoir commencer à construire un modèle de machine learning. Pas vrai ?
Et bien non. Déterminer un cas d’usage ne veut pas dire que vous disposez des bonnes données pour le traiter.
Un modèle de machine learning se construit typiquement en apprenant et en généralisant à partir d’un jeu de données d’entraînement, puis en appliquant ces enseignements à de nouvelles données pour faire des prévisions. Une pénurie de données au départ empêchera de construire le moindre modèle.
Et l’accès aux données ne suffit pas. Ces données doivent être nettoyées et de bonne qualité pour être utiles.
Ne sautez pas cette étape clé. Identifiez vos besoins en termes de données. Et voyez si les jeux sont complets et de qualité, en tout cas suffisamment pour être la base d’un projet de machine learning.
Il faut vraiment se pencher de manière méticuleuse sur la collecte initiale des données. Voici quelques questions clés à ne pas laisser de côté :
- Où sont les sources des données nécessaires à l’entraînement du modèle ?
- Quel volume de données est nécessaire pour ce projet de machine learning ?
- Quelles sont la quantité et la qualité actuelles des jeux de données destinés à l’entraînement ?
- Comment seront réparties les données entre l’ensemble de test et l’ensemble pour l’entraînement ?
- Pour les tâches d’apprentissage supervisées, quels moyens sont accessibles (financiers, techniques ou humains) pour étiqueter ces données ?
- Des modèles préentraînés peuvent-ils être utilisés ?
- Où se trouvent les données opérationnelles ?
- Existe-t-il des moyens d’accéder aux données en temps réel, aux données issues du « edge » (capteur ou autres), ou à des données importantes qui seraient « isolées » ?
Répondre à ces questions vous aidera à maîtriser le volume et la qualité des données ainsi qu’à comprendre le type d’informations nécessaires pour faire fonctionner votre modèle.
En outre, vous devez savoir comment le modèle fonctionnera dans la vraie vie. Par exemple, le modèle sera-t-il utilisé hors ligne, fonctionnera-t-il en mode batch sur des données qui sont injectées et traitées de manière asynchrone, ou sera-t-il utilisé en temps réel, avec des exigences de haute performance pour fournir des résultats instantanés ? Ces informations permettront également de déterminer le type de données nécessaires et les exigences en matière d’accès (et de réseau).
Déterminez également si le modèle sera entraîné une seule fois, ou s’il sera itéré ; avec des versions déployées périodiquement, ou en temps réel. L’entraînement en temps réel impose de nombreuses contraintes en matière de données, qui peuvent ne pas être résolues dans certains contextes.
Durant cette phase de votre projet d’Intelligence Artificielle, il est également important de savoir s’il existe des différences entre les données réelles – sur lesquelles le modèle sera appliqué – et les données d’entraînement. La même question se pose pour les données de test.
Il faudra aussi que vous déterminiez en amont quelle approche vous adopterez pour valider et évaluer les performances du modèle.
Étape 3. Collecter et préparer les données
Une fois que vous avez correctement identifié et localisé vos données, vous devrez les mettre en forme pour qu’elles puissent être utilisées pour entraîner votre modèle.
Les tâches de préparation des données comprennent la collecte, le nettoyage (« cleansing »), l’agrégation, l’augmentation, l’étiquetage (labels), la normalisation et la transformation ainsi que toutes les activités autour des données structurées, non structurées et semi-structurées.
Les opérations à suivre lors de cette étape sont les suivantes :
- Recueillir les données auprès des différentes sources.
- Normaliser les formats des différentes données.
- Remplacer les données incorrectes.
- Améliorer et augmenter les données.
- Ajouter d’autres dimensions avec des valeurs précalculées et des informations agrégées si nécessaire.
- Améliorer les données avec des sources tierces.
- « Multiplier » les bases d’images si elles ne sont pas suffisantes pour un entraînement.
- Supprimer les informations superflues et les doublons.
- Supprimer les données non pertinentes pour l’entraînement pour améliorer les résultats.
- Réduire autant que possible le bruit et lever les ambiguïtés
- Contrôler s’il faut anonymiser certaines données.
- Normaliser ou standardiser les données pour qu’elles entrent dans les intervalles attendus (feature scaling)
- Faites des échantillons de données à partir des grands jeux de données.
- Sélectionnez des attributs (feature engineering) qui identifient les dimensions les plus importantes et, si nécessaire, réduisez les dimensions en utilisant diverses techniques.
- Séparer les données en trois ensembles pour l’entraînement, le test et la validation.
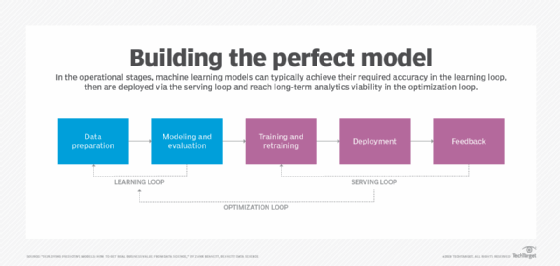
La préparation des données prend beaucoup de temps. Des études menées auprès des Data Scientists estiment que cette étape peut prendre jusqu’à 80 % du temps d’un projet de machine learning. Mais comme dit l’expression : « Garbage in, garbage out ». Dit autrement, la qualité des modèles dépendra de celle des données. Le temps consacré à ces tâches de préparation et de nettoyage des jeux de données en vaut toujours la peine.
Étape 4. Déterminer les attributs du modèle et entraîner le modèle
Une fois que les données sont utilisables et que vous connaissez bien le problème métier, il est enfin temps de passer à l’étape que vous attendiez tant : entraîner le modèle.
Cette phase nécessite de choisir le bon modèle, de l’entraîner, de régler ses hyperparamètres, de le valider, puis de passer à la phase de test et d’optimisation. Pour cela, les actions suivantes sont nécessaires :
- Choisissez le bon algorithme en fonction de l’objectif de l’apprentissage et de ses besoins en données.
- Configurer et régler les hyperparamètres pour optimiser les performances, et choisir une méthode d’itération pour arriver aux meilleurs hyperparamètres.
- Identifier les attributs qui fourniront les meilleurs résultats.
- Déterminer si l’explicabilité ou l’interprétabilité du modèle est nécessaire.
- Utiliser plusieurs algorithmes (apprentissage ensembliste) pour améliorer les performances.
- Tester différentes versions de votre modèle pour en vérifier les performances.
- Identifier les exigences qu’il faudra respecter pour la mise en production et le déploiement du modèle.
Le modèle peut ensuite être évalué pour déterminer s’il répond bien aux besoins métiers et aux exigences opérationnelles.
Étape 5. Évaluer les performances du modèle et faire des benchmarks
Dans un contexte d’IA, l’évaluation comprend l’évaluation des métriques du modèle, la matrice de confusion, les KPI, les métriques de performance, la mesure de la qualité du modèle, et une validation finale de sa capacité à atteindre les objectifs métiers qui ont été fixés.
Au cours du processus d’évaluation du modèle, vous devez procéder comme suit :
- Évaluer les modèles en utilisant une approche et un jeu de données de validation.
- Déterminer les valeurs de la matrice de confusion dans le cadre des problèmes de classification.
- Identifier des méthodes de validation croisée si cette approche k-fold est utilisée.
- Affiner les hyperparamètres pour optimiser la performance.
- Comparer le modèle de machine learning au modèle de base (ou heuristique).
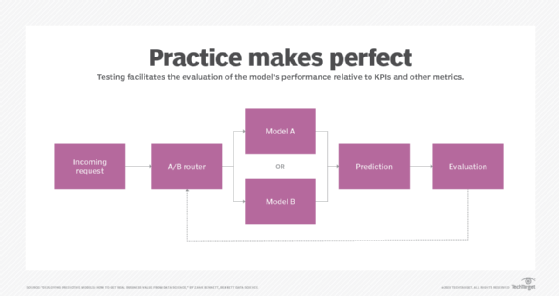
La phase d’évaluation d’un modèle peut être considérée comme l’assurance qualité du Machine Learning. Une évaluation adéquate des performances du modèle par rapport aux métriques et aux besoins déterminera en effet comment il fonctionnera en production.
Étape 6. Expérimenter en production et ajuster le modèle
Lorsque vous estimez que votre modèle est « opérationnel » et peut être déployé « pour de vrai », il est temps de se pencher sur la manière dont il fonctionne dans ce « monde réel » – ce qu’on appelle aussi « la mise en production ». Pour cela, il faut :
- Déployer le modèle avec un moyen de mesurer et de contrôler en permanence ses performances.
- Développer une base de référence ou des points de repère (faire un benchmark) par rapport auxquels les futures itérations pourront être mesurées.
- Itérer continuellement les différents aspects du modèle pour en améliorer les performances globales.
La mise en production opérationnelle du modèle peut passer par des déploiements dans un environnement cloud, en edge (dans des appareils ou des capteurs), dans un environnement sur site, ou au sein d’un groupe fermé et contrôlé. Après le déploiement, il faut considérer le versioning et l’itération des modèles, la supervision et la mise à jour des modèles dans les environnements de développement, puis de production.
Selon les besoins, ces points peuvent aller de la simple émission d’un rapport à un déploiement plus complexe et multipoint.
Étape 7. Ajuster le modèle
Même si votre modèle est opérationnel et que vous surveillez continuellement ses performances, vous n’en avez pas fini pour autant. Lorsqu’il s’agit d’implémenter des technologies, on dit souvent que la recette du succès consiste « à commencer petit, à penser grand et à itérer souvent ».
Et c’est vrai pour le Machine Learning. Il faudra à présent répéter le processus entier et apporter des améliorations à temps pour la prochaine itération. Les besoins des métiers changent. Les capacités de la technologie évoluent. Les données elles-mêmes changent, souvent de manière inattendue.
Tout cela peut créer de nouvelles contraintes et de nouvelles attentes qui auront une influence sur le déploiement du modèle, par exemple sur de nouveaux appareils ou dans de nouveaux systèmes.
La mise en production n’est, en résumé, que « la fin du début » de votre projet. Il est donc préférable d’anticiper :
- les prochains besoins pour améliorer les fonctionnalités du modèle
- l’élargissement de l’entraînement pour ajouter de nouvelles fonctionnalités
- la manière d’améliorer les performances et la précision du modèle
- l’amélioration des performances opérationnelles du modèle
- les exigences opérationnelles pour différents types de déploiements
- les solutions au problème de la « déviance des modèles » (« model drift ») et de « déviance des données » (« data drift »), qui peuvent causer des dégradations de la performance après des modifications des données opérationnelles
Réfléchissez, enfin, à ce qui fonctionne dans votre modèle, à ce qui doit être amélioré et à ce qui est en cours de réalisation. La meilleure façon de réussir dans l’élaboration d’un modèle de machine learning est de rechercher en permanence des améliorations et de meilleurs moyens de répondre à l’évolution des besoins métiers.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que la chaîne de pensée (CoT) ? Exemples et avantages
Par: Lev Craig
-
![]()
Qu'est-ce que l'apprentissage par questions-réponses (Q-Learning) ?
Par: Sean Kerner
-
![]()
GenAI et ML : les secrets de Renault pour sécuriser sa supply chain
Par: Christophe Auffray



