
Getty Images/
Comment choisir le LLM qui vous convient le mieux ?
La sélection du meilleur grand modèle de langage pour votre cas d’utilisation nécessite un équilibre entre les performances, le coût et les considérations d’infrastructure. Découvrez ce qu’il faut garder à l’esprit lorsque l’on compare les LLM.

Le lancement de ChatGPT en novembre 2022 a démontré le potentiel de l’IA générative pour les entreprises. En 2024, l’espace des grands modèles de langage s’est rapidement élargi, avec de nombreux modèles disponibles pour différents cas d’utilisation.
Avec autant de LLMs, choisir le bon peut s’avérer difficile. Il faut comparer des facteurs tels que la taille du modèle, la précision, la fonctionnalité de l’agent, la prise en charge des langues et les performances de référence, et prendre en compte des éléments pratiques tels que le coût, l’évolutivité, la vitesse d’inférence et la compatibilité avec l’infrastructure existante.
Facteurs à prendre en compte lors du choix d’un LLM
Lors du choix d’un LLM, il est essentiel d’évaluer à la fois les différents aspects du modèle et les cas d’utilisation auxquels il est destiné.
L’évaluation holistique des modèles permet d’obtenir une image plus claire de leur efficacité globale. Par exemple, certains modèles offrent des capacités avancées, telles que des entrées multimodales, l’appel de fonctions ou le réglage fin, mais ces caractéristiques peuvent s’accompagner de compromis en matière de disponibilité ou d’exigences en matière d’infrastructure.
Les aspects clés à prendre en compte lors du choix d’un LLM comprennent la performance du modèle sur différents points de référence, la taille de la fenêtre contextuelle, les caractéristiques uniques et les exigences en matière d’infrastructure.
Critères de performance
Lorsque GPT-4 a été lancé en mars 2023, OpenAI s’est vanté de la forte performance du modèle sur des benchmarks tels que MMLU, TruthfulQA et HellaSwag. D’autres fournisseurs de LLM font également référence aux performances de référence lorsqu’ils lancent de nouveaux modèles ou des mises à jour. Mais que signifient réellement ces critères ?
- MMLU. Acronyme de Massive Multitask Language Understanding, MMLU évalue un LLM dans 57 matières différentes, dont les mathématiques, l’histoire et le droit. Il teste non seulement la mémorisation, mais aussi l’application des connaissances, exigeant souvent une compréhension de niveau universitaire pour répondre correctement aux questions.
- HellaSwag. Acronyme de Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations, HellaSwag teste la capacité d’un LLM à appliquer un raisonnement de bon sens lorsqu’il répond à une question.
- TruthfulQA. Ce critère mesure la capacité d’un LLM à éviter de produire des informations fausses ou trompeuses, connues sous le nom d’hallucinations.
- NIHS. Acronyme de needle in a haystack (aiguille dans une botte de foin), cette mesure évalue la manière dont les modèles gèrent les tâches d’extraction de longs contextes. Elle évalue la capacité d’un LLM à extraire des informations spécifiques (l’aiguille) d’un long passage de texte (la botte de foin).
Parmi ces critères et d’autres similaires, MMLU est le plus largement utilisé pour mesurer la performance globale d’un LLM. Bien que MMLU soit un bon indicateur de la qualité d’un modèle, il ne couvre pas tous les aspects du raisonnement et de la connaissance. Pour obtenir une vision complète des performances d’un LLM, il est important d’évaluer les modèles sur plusieurs points de référence afin de voir comment ils se comportent dans différentes tâches et différents domaines.
Taille de la fenêtre contextuelle
Un autre facteur à prendre en compte lors de l’évaluation d’un LLM est sa fenêtre contextuelle : la quantité d’entrées qu’il peut traiter en même temps. Différents LLM ont des fenêtres de contexte différentes – mesurées en tokens, qui représentent de petits morceaux de texte –, et les vendeurs améliorent constamment la taille de la fenêtre de contexte pour rester compétitifs.
Par exemple, Claude 2.1 d’Anthropic a été publié en novembre 2023 avec une fenêtre contextuelle de 200 000 tokens, soit environ 150 000 mots. Malgré cette augmentation de la capacité par rapport aux versions précédentes, les utilisateurs ont noté que les performances de Claude avaient tendance à diminuer lorsqu’il traitait de grandes quantités d’informations. Cela suggère qu’une fenêtre contextuelle plus large ne se traduit pas nécessairement par une meilleure qualité de traitement.
Caractéristiques uniques du modèle
Si les critères de performance et la taille de la fenêtre contextuelle couvrent certaines capacités du LLM, il faut également évaluer d’autres caractéristiques du modèle, telles que les capacités linguistiques, la multimodalité, le réglage fin, la disponibilité et d’autres caractéristiques spécifiques qui correspondent à leurs besoins.
Prenons l’exemple de Gemini 1.5 de Google. Le tableau ci-dessous présente quelques-unes de ses principales caractéristiques.
| Facteur | Gemini 1.5 Pro |
| Multilingue | Oui |
| Multimodal | Oui |
| Support du fine-tuning | Oui |
| Fenêtre de contexte | Jusqu'à 2 million de jetons (~ 1,5 million de mots) |
| Appel de fonction | Oui |
| Mode JSON | Oui |
| Disponibilité | Service cloud uniquement |
| Score MMLU score | 81,9 |
Bien que Gemini 1.5 possède des propriétés impressionnantes – notamment le fait d’être le seul modèle capable de gérer jusqu’à 2 millions de jetons au moment de la publication –, il n’est disponible que sous la forme d’un service Cloud via Google. Cela pourrait constituer un inconvénient pour les organisations qui utilisent un autre fournisseur de services cloud, qui souhaitent héberger des LLM sur leur infrastructure ou qui ont besoin d’exécuter des LLM sur un petit appareil.
Heureusement, une large gamme de LLM permet un déploiement sur site. Par exemple, la série de modèles Llama 3 de Meta offre une variété de tailles de modèles et de fonctionnalités, permettant plus de flexibilité aux organisations ayant des exigences spécifiques en matière d’infrastructure.
Exigences en matière de GPU
Un autre élément essentiel à évaluer lors du choix d’un LLM concerne les exigences en matière d’infrastructure.
Les modèles plus importants, avec plus de paramètres, ont besoin de plus de VRAM GPU pour fonctionner efficacement sur l’infrastructure d’une organisation. Une règle générale consiste à doubler le nombre de paramètres (en milliards) pour estimer la quantité de VRAM GPU nécessaire à un modèle. Par exemple, un modèle comportant 1 milliard de paramètres nécessiterait environ 2 Go de GPU VRAM pour fonctionner efficacement.
À titre d’exemple, le tableau ci-dessous présente les caractéristiques, les capacités et les besoins en GPU de plusieurs modèles Llama.
| Modèle | Fenêtre de contexte | Fonctionnalités | Besoin en VRAM GPU | Applications | Score MMLU |
| Llama 3.2 1B |
128K jetons |
Multilingue, texte uniquement |
Bas (2 Go) |
Edge computing, terminaux mobiles |
49 |
| Llama 3.2 3B |
128K jetons |
Multilingue, texte uniquement |
Bas (4 Go) |
Edge computing, terminaux mobiles |
63 |
| Llama 3.2 11B |
128K jetons |
Multimodal (texte + image) |
Moyen (22 Go) |
Reconnaissance d'image, analyse de documents |
73 |
| Llama 3.2 90B |
128K jetons |
Multimodal (texte + image) |
Élevé (180 Go) |
Reconnaissance d'image avancée, tâches complexes |
86 |
| Llama 3.1 405B |
128K tokens |
Multilingue, capacités à l'état de l'art |
Très élevé (810 Go) |
Connaissances générales, mathématiques, utilisation d'outils, traduction |
87 |
Lors de l’examen des exigences en matière de GPU, le choix d’un LLM dépendra fortement du cas d’utilisation prévu. Par exemple, si l’objectif est d’exécuter une application LLM avec des fonctions de vision sur un appareil standard d’utilisateur final, Llama 3.2 11B pourrait être un bon choix, car il prend en charge les tâches de vision tout en ne nécessitant qu’une mémoire modérée. Cependant, si l’application est destinée à des appareils mobiles, le Llama 3.2 1B pourrait être plus approprié grâce à ses besoins en mémoire plus faibles, qui lui permettent de fonctionner sur des appareils plus petits.
Outils de comparaison des LLM
De nombreuses ressources en ligne sont disponibles pour aider les utilisateurs à comprendre et à comparer les capacités, les scores de référence et les coûts associés à différents LLM.
Par exemple, le Chatbot Arena LLM Leaderboard donne un score de référence global pour différents modèles, avec GPT-4o comme modèle leader actuel. Il faut toutefois garder à l’esprit que l’approche crowdsourcing de Chatbot Arena a suscité des critiques de la part de certaines parties de la communauté de l’IA.
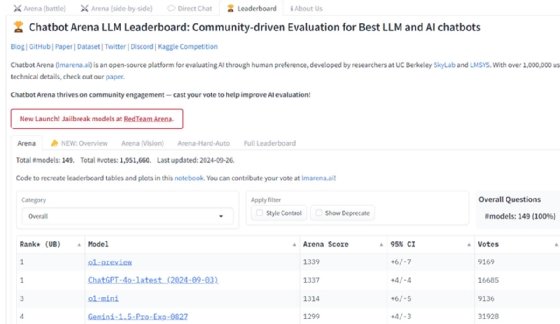
Artificial Analysis est une autre ressource qui résume différentes mesures pour divers LLM. Elle montre les capacités et les fenêtres contextuelles des modèles, ainsi que leur coût et leur temps de latence. Cela permet aux utilisateurs d’évaluer les performances et l’efficacité opérationnelle.

En utilisant la fonction de comparaison d’Artificial Analysis, les utilisateurs peuvent non seulement évaluer les paramètres spécifiques d’un LLM donné, mais aussi voir comment il se situe par rapport à l’ensemble des autres LLM disponibles.
Marius Sandbu est un évangéliste de l’informatique dématérialisée pour Sopra Steria en Norvège. Il se concentre principalement sur l’informatique pour l’utilisateur final et la technologie « cloud-native ».
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce qu'une fenêtre contextuelle ?
Par: Venus Kohli
-
![]()
Granite 4.0 : IBM veut écraser la concurrence sur le terrain de l’inférence
Par: Gaétan Raoul
-
![]()
Llama 4 : Meta s’inspire de ses concurrents chinois
Par: Gaétan Raoul
-
![]()
Gemma 3 : Google lance des modèles frugaux dédiés aux développeurs
Par: Gaétan Raoul



