
Photobank kiev - Fotolia
Comment bâtir un système de stockage Cloud avec OpenStack : les bases
Les composants de stockage d’OpenStack – Cinder et Swift – vous permettent de construire des systèmes de stockage objet et en mode bloc dans votre Cloud privé.

Dans l’évolution vers l’informatique à l’échelle du Web, des technologies essentielles telles que la virtualisation, le passage à l’architecture x86 et l’adoption rapide de la méthodologie DevOps ont transformé l’écosystème informatique. Etant donné que le volume de systèmes déployés dans les services informatiques continue d’augmenter, le prochain défi consistera à orchestrer et gérer les ressources de traitement, de stockage et réseau de la manière la plus rationnelle et efficace, en fournissant des services à ce qui est désormais connu sous le nom de Cloud privé.
OpenStack est un projet de plateforme de Cloud Open Source, lancé à l’origine par la NASA et Rackspace Hosting dans le cadre d’un co-projet en 2010. Le code source est géré par la Fondation OpenStack et distribué sous licence Apache. Ce qui permet de distribuer et de modifier librement le code, sous réserve de conserver les mentions originales relatives aux droits de reproduction. OpenStack s’est fait connaître en tant que plateforme de déploiement d’applications scale-out ; la plateforme est utilisée par un grand nombre de prestataires de services pour la mise à disposition de Clouds publics, et par de grandes entreprises cherchant à mettre en oeuvre une infrastructure de Cloud privé. Il est important de souligner que la plateforme OpenStack est conçue pour fonctionner avec les applications scale-out et qu’elle convient peu aux déploiements d’applications monolithiques traditionnelles, telles que Microsoft Exchange, ou reposant sur des bases de données telles qu’Oracle.
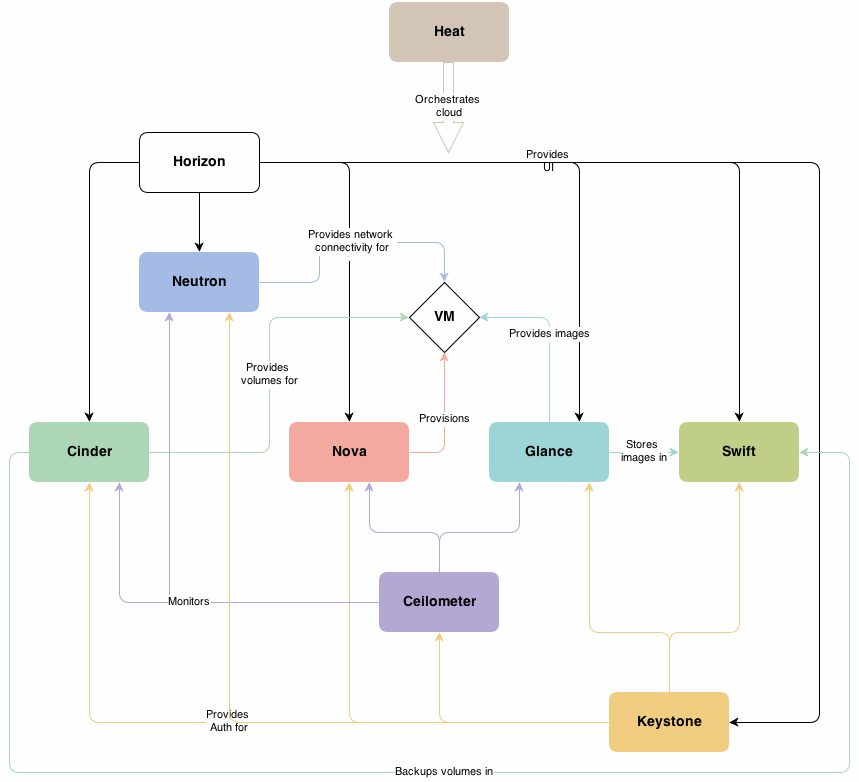
Le logiciel OpenStack comporte nombre de modules différents qui gèrent les divers aspects d’un environnement Cloud :
SWIFT : stockage objet
CINDER : stockage en mode bloc
NOVA : machines virtuelles (VM)/traitement
NEUTRON : réseau
HORIZON : tableau de bord
KEYSTONE : services de gestion des identités
GLANCE : service d’images
CEILOMETER : télémétrie
HEAT : orchestration
TROVE : base de données as-a-service (DBaaS, DataBase as a Service)
A chaque nouvelle version du code OpenStack (la dernière version étant appelée Kilo), des projets sont créés ou dérivés à partir de projets existants, ou encore lancés comme des projets entièrement nouveaux ; par exemple Ironic pour Bare Metal Provisioning et Sahara for Elastic MapReduce, dont la sortie était prévue pour la version Juno d’OpenStack.
Cinq des composants fournissent les services de données. Swift est le sous-projet qui gère le stockage objet de l’infrastructure OpenStack. Le stockage en mode bloc est pris en charge par Cinder à l’aide de protocoles IP de stockage standard tels que NFS et iSCSI. Glance est un référentiel pour les images VM. Il utilise le stockage sous-jacent d’un système de fichiers de base ou de Swift. Trove fournit les fonctionnalités DBaaS, tandis que Sahara offrira les fonctions Elastic MapReduce, également appelées stockage pour clusters Hadoop. Nous nous focaliserons sur Cinder et Swift, les deux principales plateformes de stockage.
Stockage objet et stockage en mode bloc
Les déploiements OpenStack font la distinction entre les systèmes de stockage objet et en mode bloc. Le composant Swift fournit un stockage objet, tandis que Cinder fonctionne en mode bloc. Ces deux plateformes peuvent être mises en oeuvre sur du matériel courant ou s’intégrer aux composants des fournisseurs traditionnels.
Cinder pour le stockage en mode bloc
Le stockage en mode bloc est un élément essentiel de la mise en oeuvre d’une infrastructure virtuelle et constitue la base du stockage des images VM et des données utilisées par les VM. Avant le développement de Cinder, introduit en 2012 dans la version Folsom d’OpenStack, les machines virtuelles (VM) étaient temporaires et leur stockage se limitait à leur durée de vie. Cinder prend en charge la gestion du stockage en mode bloc au niveau de la couche de traitement (Nova), à l’aide des protocoles iSCSI, Fibre Channel ou NFS, ainsi que d’un certain nombre de protocoles propriétaires offrant une connectivité d’arrière-plan.
L’interface Cinder propose un certain nombre de fonctions standards qui permettent de créer et de connecter des appareils en mode bloc aux VM, telles que « create volume » (créer un volume), « delete volume » (supprimer un volume) et « attach volume » (connecter un volume). Des fonctions plus avancées prennent en charge la capacité d’étendre les volumes, de prendre des instantanés et de créer des clones à partir d’une image VM.
De nombreux fournisseurs proposent une prise en charge de la technologie de bloc avec leurs plateformes matérielles, grâce à l’utilisation d’un pilote Cinder qui convertit l’API Cinder en commandes sur le matériel spécifique du fournisseur. Parmi ceux qui offrent une prise en charge Cinder, on compte EMC (avec VMAX et VNX), Hewlett-Packard (3PAR StoreServ et StoreVirtual), Hitachi Data Systems, IBM (sur l’ensemble des plateformes de stockage), NetApp, Pure Storage et SolidFire. Il existe également des solutions logicielles comme celles d’EMC (ScaleIO) et de Nexenta.
En outre, certaines plateformes Open Source permettent de fournir une prise en charge de Cinder, comme Red Hat avec Ceph et GlusterFS. Ceph a été intégré au noyau Linux. Ce dernier devient ainsi l’un des moyens les plus simples de fournir des fonctions de stockage en mode bloc à un déploiement OpenStack.
En 2013, une prise en charge NFS a été intégrée à la septième version d’OpenStack, appelée Grizzly - bien qu’une prise en charge « à titre expérimental » ait déjà été proposée précédemment dans la version Folsom. Avec NFS, les volumes sont traités comme des fichiers distincts d’une manière similaire à la méthode utilisée au sein de l’hyperviseur VMware ESXi ou des VHD sur Microsoft Hyper-V. L’encapsulation des volumes VM sous la forme de fichiers permet la mise en oeuvre de fonctions telles que les instantanés et le clonage.
Différentes fonctions de stockage ont été introduites dans Cinder au fil des versions, et des prises en charge par la suite par les fournisseurs de solutions de stockage. La liste complète disponible sur la page Wiki d’OpenStack traitant des pilotes de stockage en mode bloc OpenStack.
Swift prend en charge le stockage objet
Dans OpenStack, le stockage objet est fourni via Swift. Ce dernier met en oeuvre un magasin d’objets scale-out réparti entre les noeuds d’un cluster OpenStack. Les magasins d’objets stockent les données sous la forme d’objets binaires, sans référence spécifique à un format. Les objets sont stockés dans Swift et en sont extraits à l’aide de simples commandes, telles que PUT ou GET, utilisant le protocole (Web) HTTP, connu également en tant qu’API RESTful.
L’architecture Swift se compose d’un certain nombre de services logiques, comprenant serveurs d’objets, serveurs proxy, serveurs conteneurs et serveurs de compte, qui ensemble sont classés en tant qu’anneau. Les données sont stockées sur les serveurs d’objets avec les autres composants utilisés pour suivre les métadonnées relatives à chaque objet stocké et pour gérer l’accès aux données.
Au sein de Swift, le concept de zones permet de gérer la résilience des données. Une zone représente le sous-composant d’un anneau utilisé pour fournir une copie particulière des données, plusieurs zones servant à stocker les copies redondantes des données appelées « répliques » (avec un minimum de trois par défaut). Dans Swift, une zone peut être représentée par un seul lecteur ou serveur, en tenant compte de la répartition géographique des données entre les datacenters.
A l’instar de nombreux magasins d’objets, Swift se fonde sur l’idée d’une cohérence finale pour mettre en oeuvre la résilience des données.
Cela signifie que les données ne sont pas répliquées de manière synchrone à l’échelle d’un cluster OpenStack, comme cela pourrait être le cas avec un stockage en mode bloc. En effet, les données sont plutôt répliquées entre zones, sous forme d’une tâche en arrière-plan ; une tâche qui peut être suspendue ou qui peut échouer si les systèmes sont soumis à une charge élevée.
En comparaison du stockage en mode bloc, où la réplication synchrone est utilisée pour permettre un niveau élevé de disponibilité, la cohérence finale peut sembler quelque peu risquée. Toutefois, un équilibre doit être trouvé entre évolutivité, performances et résilience. La cohérence finale permet à une archive d’évoluer beaucoup plus facilement qu’un système reposant sur le stockage en mode bloc ; dans le cas de Swift, les serveurs proxy récupèrent la copie la plus récente des données, même si certains serveurs du cluster sont inaccessibles.
Comme avec tous les projets OpenStack, le développement de Swift se poursuit avec de nouvelles fonctions et améliorations à chaque nouvelle version. OpenStack Grizzly a apporté des contrôles granulaires des répliques, permettant aux anneaux de disposer d’un nombre configurable de répliques. Les performances de lecture des objets ont également été améliorées grâce à l’idée d’un tri basé sur la synchronisation et destiné aux serveurs d’objets. Grâce à cette approche, les données sont distribuées par le serveur d’objets qui répond le plus rapidement ; un paramètre important pour une montée en charge sur des réseaux plus étendus.
Etant donné que Swift utilise le protocole HTTP, il serait tout à fait possible d’utiliser des solutions tierces pour le stockage objet dans OpenStack, comme les produits de Cleversafe et de Scality, ou des Clouds publics tels qu’Amazon Web Services Simple Storage Service.
La partie 2 de ce dossier traitera du choix important entre Swift et Cinder.




