
iStock
Comment assurer au mieux le suivi des microservices asynchrones ?
Comment retracer un workflow complexe dans une architecture asynchrone axée sur les microservices ? Voici deux options à considérer : les ID de corrélation et les outils de traçage distribué.

Avec des composants et des API répartis sur plusieurs serveurs dans des environnements virtuels basés sur le cloud, il est difficile de définir un flux pour des interactions synchrones afin d’en connaître précisément l’ordre d’exécution.
Microservices synchrones et asynchrones
Le schéma de requête-réponse des microservices synchrones est le suivant :
- Une demande est adressée au microservice distribué.
- Le microservice traite la demande, mais bloque le client.
- Le microservice débloque le client lorsqu’il renvoie une réponse.
- Lorsque le client reçoit la réponse, le flux de contrôle se poursuit.
Ce type de communication est principalement utilisé pour connecter un microservice à un seul composant, par exemple pour appeler une API en particulier. Le modèle asynchrone, lui, s’adapte mieux à l’interaction entre microservices, puisqu’il ne crée pas de dépendances.
En effet, dans une architecture asynchrone, il n’est généralement pas nécessaire de mettre en place un système de requête-réponse. Les clients publient des événements à une file d’attente, un broker de messages tels RabbitMQ ou Kafka. Divers abonnés y retirent alors individuellement des informations et les exploitent. Dans la plupart des cas, il n’y a aucune garantie que les abonnés suivront l’ordre de publication des messages auprès du courtier. Bien que cela ne nuise généralement pas à l’intégrité d’une application, et que la plupart des structures asynchrones orientées microservices tiennent compte de la nature arbitraire de l’ordre des messages, cela augmente d’un cran la difficulté.
Comme dit l’adage, rien n’est impossible à qui veut vraiment. Avec les bons outils et un peu de connaissance du fonctionnement des architectures associées, l’on peut résoudre le délicat puzzle du traçage des microservices distribués.
Tracer les microservices distribués
Pour retracer des comportements dans une architecture asynchrone, l’on peut utiliser le modèle d’identificateur de corrélation (ID). L’on peut aussi recourir à un outil de traçage distribué.
L’ID de corrélation est l’identifiant unique qui unifie les messages qui font partie d’un même flux de travail.
Lorsqu’un abonné reçoit un message d’un broker, il en inspecte l’en-tête pour vérifier la présence du header, x-correlation-id. Il s’agit d’une extension des attributs standards du header, mais la communauté de développement des microservices l’accepte de manière conventionnelle.
Si l’attribut est présent, il sera transmis dans l’en-tête de tout message émis par l’abonné actuel. S’il est absent, l’abonné peut en créer un – généralement sous la forme d’un GUID – et l’envoyer comme si l’ID de corrélation était en usage dans le message initial.
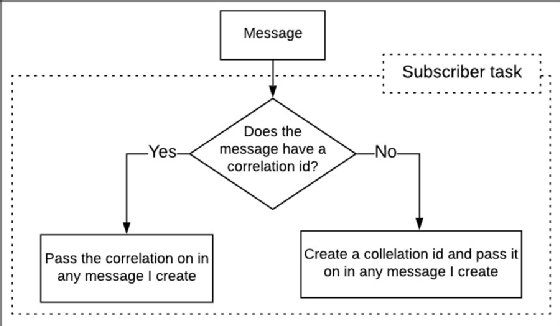
Ensuite, lorsqu’il est temps d’étudier ou de déboguer un workflow, un développeur peut consulter les entrées du journal des messages en fonction de l’ID de corrélation spécifié. Une fois qu’un ingénieur a récupéré tous les logs et les messages associés à l’ID de corrélation, il utilisera une analyse logique pour obtenir des indications sur la manière d’exécuter correctement le flux de travail.
Ces étapes supposent que la politique de collecte de logs de l’architecture orientée microservices, fournit un ID de corrélation et une valeur à toutes les entrées de journal faites par un microservice donné associé à un workflow. Si certaines entreprises font preuve de discipline en ce qui concerne les ID de corrélation, d’autres sont moins formelles. Les règles de gestion des identifiants et de logging doivent être synchronisées. Dans le cas contraire, les équipes risquent de ne pas disposer de l’ensemble des logs nécessaire au suivi des workflows.
Les outils de traçage des microservices
Dans les contextes moins fiables, il est plus facile d’utiliser un outil de traçage de microservices distribués qui gère automatiquement cette corrélation.
Cet outil observe les activités de messagerie au sein d’une application orientée microservices, et rapporte ces activités de manière organisée. Il existe de nombreux produits de profilage pour effectuer un suivi distribué. Certains, comme Java Flight Recorder, sont open source, tandis que d’autres nécessitent une licence.
OpenTelemetry est une collection d’outils open source qui prennent en charge le traçage asynchrone. Le logiciel Zipkin, développé par Twitter, prend également en charge cette fonction. Java Mission Control peut aussi fournir des informations sur le comportement d’un microservice sur une machine virtuelle Java spécifique.
Parmi les produits sous licence, citons l’APM et l’outil de suivi distribué de Datadog ou Wavefront de VMware.
C’est généralement en combinant l’ID de corrélation et en incorporant éventuellement un logiciel spécialisé dans le profilage des données que les développeurs peuvent résoudre l’énigme des microservices distribués asynchrones de traçage. Cependant, n’oublions pas de mentionner que la plupart des architectures de microservices marient des procédés synchrones et asynchrones et qu’il faut également surveiller la latence des requêtes-réponses.
Pour approfondir sur Architectures logicielles et SOA
-
![]()
Qu'est-ce que l'APM ? Guide de surveillance des performances des applications
Par: Stephen Bigelow
-
![]()
Traçage distribué vs logging : quelles différences ?
Par: Donald Farmer
-
![]()
Digital Workplace : les bénéfices de la vidéo asynchrone pour le travail hybride
Par: David Maldow
-
![]()
Les rôles des sidecars dans une architecture de microservices
Par: Joydip Kanjilal



