Comment améliorer les requêtes avec la réplication MySQL / RedShift (1)
La réplication des bases de données peut améliorer sensiblement la performance des requêtes. Mais pour que cela soit possible, les développeurs doivent bien comprendre tous les composants qui entrent en ligne de compte. Voici comment procéder avec Amazon RedShift et MySQL.
Les données sont au cœur de beaucoup d’applications, surtout si on parle d’analytique. Afin d’optimiser et de mieux structurer les requêtes, il est assez courant de disposer de plusieurs réplicas des données, stockées dans plusieurs bases. La réplication de données au sein de la base offre un gros avantage : la capacité d’optimiser les performances du système. Toutefois, le choix de la bonne base dépend de plusieurs facteurs, comme celui du type de données et de la capacité adéquate.
Amazon RedShift est un service d’entrepôt de données Cloud, entièrement managé, avec des capacités de l’ordre du pétaoctet, qui a la particularité de s’intégrer aux autres services AWS. Le service propose une interface SQL, comme fonction de base. RedShift propose aussi une fonction de réplication qui permet de migrer les données en temps réel depuis MySQL vers des environnements RedShift, via S3. Ce qui évite d’exporter et d’importer des données à la main.
Les entreprises préfèrent généralement utiliser la réplication des bases MySQL au-dessus de RedShift à cause de meilleures performances en matière de requêtes analytiques. MySQL est optimisée pour gérer un petit volume de données. Mais là où RedShift se distingue : il s’appuie sur une architecture massivement parallèle et sur une base en colonnes pour agréger et analyser des grands volumes de données. Cela est particulièrement intéressant pour analyser des données en temps réel.
Réplication de bases MySQL : trois approches
Organizations typically choose MySQL database replication over Redshift due to MySQL's multiple data stores and improved analytical query speed.
Le transfert et la récupération de données complets (Full Dump and Load). Il s’agit de l’approche la plus simple de réplication MySQL. MySQL décharge régulièrement les tables pour les recharger dans RedShift. Les tables RedShift correspondantes sont recrées lors du processus de chargement. Bien que cette méthode soit simple, elle comporte toutefois certains risques. Par exemple, la base de données peut être verrouillée lors des opérations de transfert. Cela peut provoquer une forte latence, surtout si la table est volumineuse. Il est donc suggéré de décharger les tables à partir de réplicas en lecture et non de la base en production.
Le transfert et la récupération de type incrémental. A l’inverse du transfert et de la récupération complets, une requête est paramétrée pour aller vérifier régulièrement les mises à jour. RedShift ne charge ensuite que les nouvelles données ajoutées et celles mises à jour. Une requête de consolidation (MERGE) reconstruit la table originale. Avec cette approche, seules les mises à jour sont extraites et chargées dans RedShift. Les requêtes périodiques réduisent donc les chargements – seulement une petite partie de la base de données est mise à jour entre deux opérations consécutives de chargement. Cette approche a plusieurs inconvénients. Les lignes supprimées ne peuvent pas être capturées- les développeurs ne peuvent ainsi pas les retourner dans une requête. Une requête de consolidation reconstruit la table originale lors de la réplication vers RedShift. La meilleure approche consiste à utiliser un réplica en lecture au lieu de la base en production, car les opérations de consolidation ajoutent de la complexité au déploiement.
Réplication des logs binaires. Les logs binaires de MySQL journalisent les logs pour chaque opération effectuée par la base de données. Après le premier déchargement dans la base MySQL, le log binaire diffuse en continu et charge les données dans RedShift. Avec cette approche, les tables ne sont pas verrouillées ; les lignes supprimées et les modifications des tables sont aussi prises en compte.
Transférer vers S3, copier vers RedShift
Une autre approche de réplication : MySQL transfert une copie vers S3 et utilise la commande de RedShift pour charger les données dans l’entrepôt de données d’AWS. Cette méthode est adaptée à de petites bases de données.
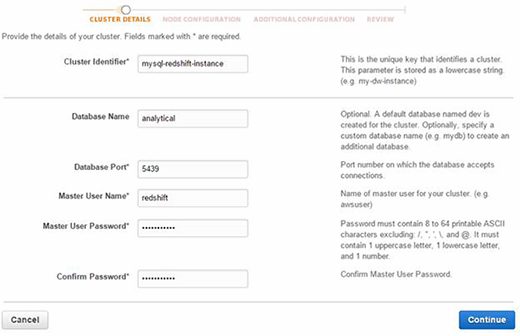
Pour réaliser cette opération, identifiez-vous dans la console d’administration AWS pour créer et configurer un cluster RedShift.
Figure 1. Utilisez la console AWS pour entrer les détails de votre cluster.
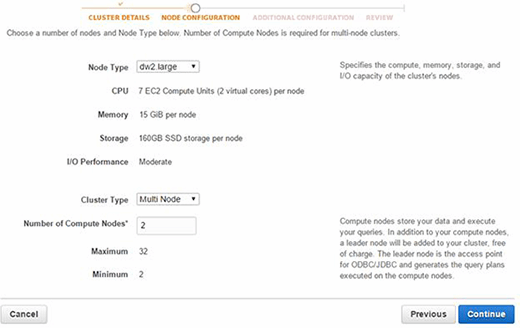
Puis, configurez le nœud.
Figure 2. Paramétrez le nœud.
Créez le cluster RedShift, puis configurez les groupes de sécurité pour autoriser l’accès Host. Après cela, exportez les tables vers RedShift.
Dans l’exemple suivant, une commande est entrée pour sélectionner toutes les transactions depuis le 1er janvier 2016. Ils sont ensuite splittés, avec un maximum d’1 million de lignes par fichier :
Après ce chargement des données à partir de S3, exécutez une commande VACUUM pour réorganiser les données et la commande ANALYSE pour mettre à jour les statistiques de la table :
$ vacuum tbl_product
$analyze table_product
Les données sont désormais disponibles dans le cluster RedShift. Pour vérifier les données, utilisez certaines commandes depuis la console psql :
$ analytical=# \d tbl_product;
Pour vérifier si la table s’est chargée correctement :
$ analytical=# SELECT COUNT(*) FROM tbl_product;
Il existe également des outils Open Source, comme Tungsten ou Embulk, pour migrer de gros volumes de données d’un système à l’autre. Il est important de savoir si vous avez besoin d’une forte capacité de traitement, d’une latence élevée ou des chargements fréquents de schémas. Si c’est le cas, considérez un autre outil.