Application et IA générative : l’émergence d’une architecture type
L’architecture applicative universelle n’existe pas, mais un modèle s’impose quand il est question d’exploiter un grand modèle de langage (LLM). Il s’agit d’enrichir les résultats d’un modèle avec une base de connaissances. Une approche extensible, selon des data scientists employés de Red Hat.
Les géants du cloud et les éditeurs poussent tous des services pour concevoir des applications propulsées par de grands modèles de langage.
Mais quelles sont les briques essentielles pour ce faire ? Comment déployer de tels modèles quand il n’est pas possible de recourir aux LLM disponibles depuis un cloud public ?
Premièrement, si les modèles NLG peuvent générer du texte, ils sont désormais réputés pour leurs hallucinations. Ces erreurs empêchent de les utiliser tels quels en entreprise.
Celles-ci sont en partie dues à la manière dont ces modèles fonctionnent. À partir de leurs données d’entraînement et d’une entrée – un prompt –, leur rôle est de prédire le prochain ou le précédent mot d’une phrase.
Pour ancrer leurs sorties ou productions dans la réalité et éviter les effets de toxicité ainsi que les imprécisions, il est nécessaire de recourir à la recherche vectorielle.
« Les LLM sont généralement des boîtes noires. Si vous les utilisez dans une phase de brainstorming, les résultats peuvent être intéressants, mais si vous avez besoin de faits il vous faut un moyen pour qu’ils interagissent avec une base de connaissances », rappelle Shray Anand, data scientist chez Red Hat.
L’état de l’art : nourrir le modèle d’IA générative de données contextuelles
Lors de l’Open Source Summit 2023 à Dublin, Shray Anand et son collègue Surya Prakash Pathak ont présenté l’architecture type d’un système de question-réponse propulsé par un grand modèle de langage.
Cette mise en contexte de données nécessite d’utiliser ou de déployer des pipelines de données. Il convient d’acheminer des documents vers un modèle qui est chargé de diviser les textes en tokens, puis de les représenter à l’aide de nombres à virgule flottante, appelés vecteurs ou embeddings. « Les embeddings emprisonnent des informations concernant l’objet en entrée », explique Shray Anand. « Il s’agit de placer des mots dans un espace vectoriel où les termes ayant des significations similaires sont proches les uns des autres. Par exemple, les vecteurs équivalant à un chien et un chat seront plus adjacents que celui représentant une voiture », illustre-t-il.
Dans le cas d’un système de question-réponse, typiquement un agent conversationnel qui anime une foire aux questions (FAQ), il convient d’encoder des paires de questions-réponses dans des vecteurs d’un certain nombre de dimensions, poursuit la data scientist. Plus le nombre de dimensions est élevé, plus il est possible de capturer des nuances et des relations complexes entre les mots. En clair, si une demande appelle un résultat simple, alors il est peu probable que l’on utilise un modèle d’embeddings capables d’interpréter des centaines de milliers de dimensions. Généralement, les LLM gèrent des vecteurs d’une centaine à un peu plus d’un millier de dimensions.
Ces vecteurs sont stockés et indexés dans une base de données vectorielle.
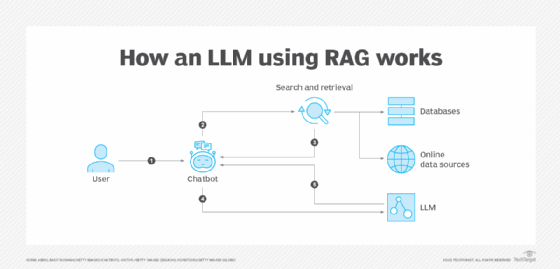
Une interface utilisateur permet de soumettre une requête, une instruction ou une question. Celle-ci est acheminée vers la base de données vectorielle afin d’enclencher une recherche de similarité entre les termes de la requête et la sémantique « emprisonnée » dans la dimension d’un vecteur. Cette ressemblance est calculée à l’aide du score de la similarité cosinus.
Dans le cas de l’application déployée par la data scientist de Red Hat, le mécanisme de recherche sélectionne les trois candidats les plus proches. Ensuite, le texte correspondant est envoyé au modèle avec le prompt via un orchestrateur, afin de générer la réponse.
« La requête et les candidats vont vers un gestionnaire de prompts, ou un outil capable de générer un prompt pouvant communiquer avec l’interface API interagissant avec votre LLM », décrit la data scientist. « Le modèle crée alors la réponse finale, puis la renvoie à l’API, également interfacée avec l’application front-end ».
Il s’agit de la description d’une application de retrieval augmented generation (ou RAG).
Une architecture extensible
La technique Retrieval Augmented Generation peut être utilisée pour propulser un chatbot interne ou externe, mais également pour contextualiser des résumés ou des tâches de classification.
En juin dernier, Andreessen Horowitz avait présenté une architecture émergente bien plus complexe que cette dernière. Selon Shray Anand, il est plus simple de débuter avec une architecture simple, mais extensible. « C’est un squelette que vous pouvez améliorer de bien des façons. Vous pouvez ajouter de la recherche lexicale ou par mot-clé à la recherche vectorielle, vous pouvez installer un système de file d’attente, de mise en cache ou encore de planification des tâches », explique-t-il.
La barrière d’entrée est tellement basse qu’il est possible de déployer un modèle et une application sur site ou dans le cloud, à des fins de test.
Il s’agit alors d’assembler des composants open source et/ou propriétaire, selon le data scientist. Oui, mais lesquels ?
Concernant la base de données vectorielle, il existe plus d’une cinquantaine de solutions qui prennent en charge les embeddings. « Les acteurs open source les plus importants sont Qdrant, Milvus, Weaviate ou encore Pgvector », indique Shray Anand. Pgvector correspond plus particulièrement à une extension de PostgreSQL sélectionné par Google Cloud pour agrémenter sa DbaaS AlloyDB d’une prise en charge des vecteurs. Elasticsearch ou OpenSearch supportent aisément ces représentations numériques.
« Dans le cadre de notre démonstration, nous avons choisi Qdrant, parce qu’elle peut être déployée sur Kubernetes et s’exécuter en mémoire localement », indique le data scientist. Shray Anand ajoute que, d’après son expérience, les SGBD spécialisés obtiennent de meilleurs résultats, et renvoie aux benchmarks effectués par l’équipe derrière Qdrant.
Le gestionnaire de prompts, ici, n’est autre que LangChain, l’un des frameworks les plus populaires en la matière. L’on peut également citer LlamaIndex ou Auto-GPT.
Bien choisir son modèle d’IA générative
Quant au modèle, l’équipe de Red Hat a d’abord utilisé l’API de GPT 3.5. Le modèle d’OpenAI n’est pas open source, mais plutôt performant. Les modèles propriétaires, GPT-4 et Claude 2 d’Anthropic sont des références.
Parmi les familles de modèles open source, les chercheurs listent : GPT-X, Gopher, Falcon, Pythia, Flan ou encore Bloom. L’on peut ajouter Mistral 7B de Mistral AI et Alfred de LightOn. Pour rappel, Llama 2 n’est pas open source, mais dispose d’une licence propriétaire permissive, tant que l’application développée ne dépasse pas les 700 millions d’utilisateurs.
« Le choix des modèles dépend de votre budget, de vos exigences en matière de licence et de ses performances », résume Surya Prakash Pathak. Plus le nombre de paramètres est important, plus un LLM nécessite de ressources IT, principalement de puissants GPU.
En outre, il faut comprendre que chaque LLM a ses forces et ses faiblesses et qu’il s’avère souvent nécessaire d’utiliser un modèle par type de cas d’usage, suivant s’ils servent à propulser un système de question-réponse, de génération de résumés, de code, etc.
Si le mécanisme de recherche documentaire ne suffit pas pour obtenir des réponses satisfaisantes, il est possible de recourir au prompt engineering puis à une phase d’apprentissage supervisée.
Pour établir une FAQ consacrée à Red Hat OpenShift for AWS (ROSA), les chercheurs ont effectué le fine-tuning supervisé du modèle préentrainé Flan, à l’aide de paires de questions-réponses liées à son cas d’usage. Il existe également des jeux de données open source comme Falcon-Instruct et Dolly v2 pour compléter ce data set.
Si l’application concernait un outil de revue de code, un cas d’usage en cours de développement chez Red Hat, les paires de requêtes-instructions auraient concerné l’identification d’erreurs dans un langage de programmation, par exemple Java. En clair, ce principe peut s’appliquer à une grande variété de cas d’usage.
Les composants nécessaires pour déployer un LLM
Reste à savoir comment déployer le ou les modèles utilisés.
« Pour le déploiement de modèles, il faut prendre en compte la taille du modèle et la disponibilité des GPU », indique Surya Prakash Pathak. « Vous devez également optimiser le déploiement en matière de coûts, de performances, de latences, de maintenance et d’utilisabilité ».
« Pour le déploiement de modèles, il faut prendre en compte la taille du modèle et la disponibilité des GPU ».
Surya Prakash PathakData scientist, Red Hat
« Il faut se poser la question : “combien d’utilisateurs doivent pouvoir utiliser le modèle ?” », poursuit-il.
Lors du déploiement du modèle, il faut également prendre en compte les spécificités de la plateforme ou de l’orchestrateur que l’on compte utiliser. Ces technologies sont généralement conteneurisées et peuvent être orchestrées à l’aide de Kubernetes.
La plupart des modèles nécessitent d’installer des librairies Python, PyTorch/TensorFlow ainsi que CUDA et son Kernel.
Plusieurs frameworks d’entraînement et d’inférence ont vu le jour. TensorFlow a une visée généraliste, tout comme Ray, le framework imaginé par Anyscale. D’autres projets comme OpenLLM (BentoML), vLLM (qui reprend quelques briques de Ray), ou DeepSpeed-MII (une déclinaison du projet de Microsoft consacré à l’inférence) sont dédiés aux modèles d’IA générative. HuggingFace propose un serveur Web nommé Text Generation Inference (TGI) qui exploite des composants écrits en Python et Rust, ainsi que le protocole gRPC.
« Des outils comme DeepSpeed-MII et vLLM offrent une faible latence, mais ils ont des intégrations limitées avec d’autres technologies », indique Surya Prakash Pathak.
« Nous nous intéressons plus particulièrement à Ray Serve [la brique d’inférence de Ray, N.D.L.R] et Text Generation Inference. Ray Serve n’est pas le plus rapide, mais il simplifie la mise à l’échelle, permet de coupler plusieurs modèles et dispose d’une intégration native avec LangChain », illustre le data scientist.
Il existe également des orchestrateurs comme SkyPilot, un outil permettant de déployer des LLM sur OCI, GCP, Azure, AWS, ou encore IBM Cloud.
Une supervision nécessaire
Dans le cadre du développement de son application FAQ, l’équipe de data scientist est en train de récolter des retours des utilisateurs afin de lancer une phase de reinforcement learning with human feedback (RLHF). Cette phase réclame d’entraîner un modèle de récompense à partir des retours des utilisateurs.
Selon les data scientists de Red Hat, cette phase est nécessaire quand une réponse de référence n’existe pas, quand une réponse est juste, mais peu satisfaisante pour l’utilisateur, et qu’il faut mettre en place des règles d’éthique. Pour la collecte des feedbacks, ils recommandent le recours à Argilla. Dans certains cas, l’introduction de cette collecte réclame de personnaliser l’interface utilisateur en conséquence.
Si cette technique est désormais documentée, elle n’est pas forcément à la portée de toutes les entreprises. En attendant, mettre en place un outil de collecte de logs et de supervision paraît nécessaire.
Dans le monde open source, il est possible de se tourner vers le couple Prometheus-Grafana. Les produits du marché dont ceux de Datadog, Dynatrace ou encore New Relic proposent des fonctionnalités pour collecter, superviser et agir sur les logs, traces, métriques des applications et modèles utilisés.
Oui, mais pour surveiller quelles données ? Il y a bien sûr des données de performances, dont le débit, calculé en nombre de tokens générés et de requêtes gérées par seconde, ainsi que le temps de réponse du modèle et des mécanismes de RAG. Du côté du LLM, l’on peut aussi observer les coûts d’inférence et l’occupation de la VRAM par le modèle suivant les requêtes, afin d’ajuster la taille des clusters.
« Pour évaluer les résultats de recherche, la métrique Normalized Discounted Cumulative Gain (ou NDCG) est la plus appropriée ».
Surya Prakash PathakData scientist, Red Hat
Afin d’évaluer la qualité des réponses du modèle, il faut à la fois modérer la qualité des réponses transmises par la base de données vectorielle et le texte généré.
« Pour évaluer les résultats de recherche, la métrique Normalized Discounted Cumulative Gain (ou NDCG) est la plus appropriée », considère Surya Prakash Pathak. Cette mesure de pertinence graduelle est employée pour noter le système de recherche vectorielle en fonction des documents renvoyés.
En ce qui concerne la génération de texte, ce contrôle peut être en partie automatisé. Il faut alors s’appuyer sur une réponse de référence à une question donnée, et utiliser les benchmarks NLP, comme BLEU et ROUGE.