
arthead - stock.adobe.com
7 algorithmes à connaître en 2021 : fonctionnalités, différences, principes et applications
Approches algorithmiques explicables, modèles d’attention et transformers, algorithmes génératifs (GAN et VAE), algorithmes multimodaux et multitâches, algorithmes sur les graphes et GNN, causalité et algorithmes TCN, Small Data et Transfer Learning : Nicolas Meric de Dreamquark revient sur ces sept évolutions clefs de l’IA.

Le domaine de l’intelligence artificielle est un domaine très actif, porté par l’intérêt grandissant du monde économique, les développements des acteurs de la tech et du monde académique. Les besoins du secteur de la tech et des autres entreprises amènent au développement de nouveaux algorithmes pour analyser les quantités grandissantes de données (voix, texte, images, vidéos, données tabulaires), développer des applications dont l’expérience utilisateur sera satisfaisante et bien sûr le faire en prenant en compte les exigences réglementaires grandissantes. Cela dit, la quête par certains grands acteurs de la tech, de l’intelligence artificielle générale (en capacité de répliquer – voire de dépasser – notre intelligence) amène à des développements en avance des besoins exprimés par la majorité des acteurs économiques.
J’ai identifié sept tendances fortes qui ont émergé au cours des deux dernières années et qui se confirment en 2021 au travers de l’augmentation significative de publications scientifiques, du nombre de projets open source et de leur adoption dans des applications à visée commerciale.
1 – Approches algorithmiques explicables
L’accélération de l’investigation de l’usage de l’intelligence artificielle par les régulateurs – avec notamment la proposition d’une nouvelle réglementation par l’Union européenne, l’article de la CNIL sur la prise de décision automatique, ou encore un rapport sur la gouvernance des algorithmes d’intelligence artificielle dans le secteur financier par l’ACPR –, amène à de nouveaux développements pour prendre en compte ces exigences réglementaires émergentes.
Par ailleurs, l’enjeu de l’adoption (et donc de compréhension) et les problématiques de robustesse grandissantes entraînent la nécessité de repenser notre approche de la transparence, de l’interprétabilité ou de l’explicabilité des algorithmes d’intelligence artificielle.
Ces dernières années le sujet de l’explicabilité des algorithmes fait l’objet d’un intérêt grandissant soutenu par le support financier d’acteurs comme la Darpa. Depuis 2016 des approches émergent pour assurer d’identifier les variables et combinaisons de variables (en anglais : features - pixel, colonne d’un tableau Excel, variation sur un intervalle de temps d’un échantillon sonore, séquence de mots, etc.) les plus importantes pour une décision algorithmique donnée.
Ces approches – par exemple SHAP, LIME ou les algorithmes de gradients intégrés (souvent destinées aux data scientists) – calculent après coup l’apport de chacune des variables utilisées pour réaliser les prédictions.
Depuis 2019, de nouveaux algorithmes, naturellement explicables, émergent afin de répondre à la demande grandissante pour l’explicabilité et d’apporter à la fois, précision, explicabilité, rapidité et optimisation de la quantité de calcul nécessaire pour obtenir ces explications.
C’est par exemple le cas de l’algorithme TabNet, dont DreamQuark propose une implémentation reconnue à la fois open source et accessible à tous via des interfaces intuitives. Une des particularités de Tabnet est de s’appuyer sur le mécanisme d’attention inventé en deep learning, pour reproduire le mécanisme d’attention cognitive de l’homme.
Il s’agit généralement d’ajouter une couche de neurones entièrement connectée suivie d’une fonction qui va transformer les sorties de cette couche de neurones en probabilités. Cette couche va permettre de renforcer le poids que donne l’algorithme aux informations les plus importantes. Les probabilités obtenues peuvent être analysées pour savoir quelles informations sont jugées les plus importantes, ce qui renforce le caractère explicable.
2 – Modèles d’attention et transformers
Depuis sa renaissance autour des années 2010, le deep learning est progressivement devenu l’approche dominante, notamment en traitement de l’image, de la voix ou du texte. Différentes approches ont été proposées pour répondre à la demande de plus de précision et accroître la qualité de la modélisation de la voix ou du texte (notamment pour améliorer les recherches web ou l’expérience des assistants vocaux et numériques).
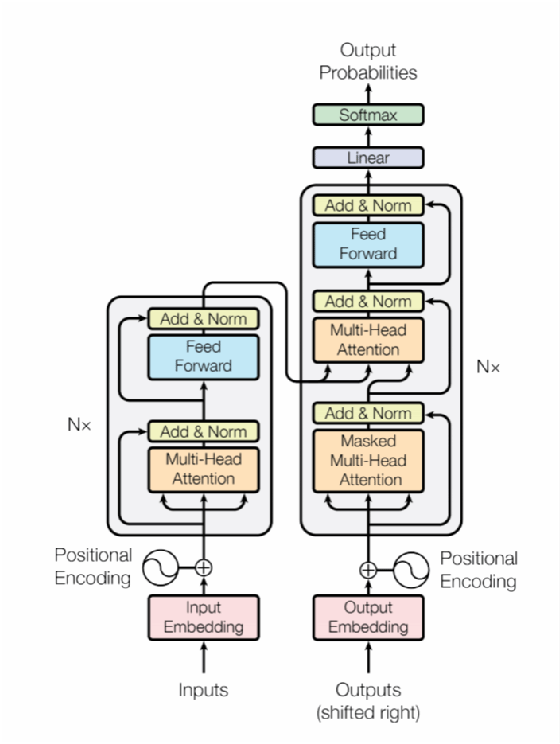
En 2017, Google a proposé un article, « Attention is all you need », qui a ouvert le champ de recherche d’une famille algorithmes de deep learning à mécanisme d’attention, appelé le « Transformer », tout d’abord dans le domaine de l’analyse de texte et dont le mécanisme a été adopté à tous les types de données. Le mécanisme d’attention est quant à lui utilisé dans d’autres algorithmes.
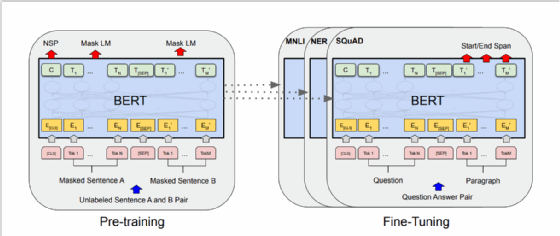
En 2018, Google a par ailleurs proposé une nouvelle architecture d’algorithmes pour le traitement du langage naturel nommée BERT – pour Bidirectional Encoder Representations from Transformers – qui a permis d’accroître significativement les performances des modèles de deep learning appliqués à l’analyse du langage sur de nombreuses tâches de traitement du langage naturel (traduction, classification de texte, résumé de texte, extraction d’informations, génération de textes, etc.).
L’approche adoptée par BERT consiste à préentraîner un Transformer sur deux tâches de manière non supervisée (prédiction d’un mot masqué dans une phrase et prédiction de la phrase suivante dans un texte) et à optimiser – via des données labélisées et un apprentissage supervisé – le modèle obtenu dans cette première phase pour les tâches que nous souhaitons réaliser (dans leur article, les auteurs appliquent cette approche à 11 tâches de traitement du langage naturel).
BERT n’est pas la seule architecture de Transformer appliquée au traitement du langage, et contrairement à d’autres architectures le mécanisme d’attention est bidirectionnel, à savoir qu’il utilise aussi bien les informations à gauche du mot caché que celles à sa droite.
3 – Algorithmes génératifs (GAN et VAE)
L’architecture de réseau de neurones dite Transformer a ouvert la voix aux algorithmes les plus performants de génération de texte et a accru la course aux très grands modèles de langage avec plusieurs milliards de paramètres (voire des milliers de milliards) qui se sont entraînés sur des corpus de texte sans commune mesure avec ce qui était fait jusqu’à présent.
Les modèles génératifs ne sont pas, quant à eux, nouveaux. Les premiers développements ont eu lieu dès 2014 avec l’invention des Réseaux génératifs antagonistes (GAN) et des autoencodeurs variationnels (VAE) capables de produire des images et des vidéos de plus en plus réalistes.
Les algorithmes génératifs, dont les architectures peuvent être variées, vont souvent s’appuyer sur le principe de l’architecture précédente et sur une procédure d’apprentissage machine. Dans un premier temps, un algorithme contenant d’un côté un encodeur, et de l’autre un décodeur, va tenter de reproduire de la donnée non bruitée à partir d’une donnée, généralement bruitée, passée en entrée (par exemple une image pour apprendre à générer cette même image).
Cette procédure va permettre d’apprendre les paramètres de l’encodeur et les paramètres du décodeur (dont les architectures sont relativement symétriques). L’espace latent, quant à lui obtenu après l’encodeur, va permettre de résumer les informations contenues dans l’ensemble des données utilisées en entrée de l’algorithme.
Une fois l’encodeur et le décodeur appris et l’espace latent constitué, il faudra alors enlever l’encodeur et il sera possible de générer de nouvelles données très réalistes en modifiant les valeurs dans cet espace latent. Bien que ces algorithmes aient des applications variées, les algorithmes génératifs ont été mis en avant du fait de la qualité des photos de personnes générées par les meilleures versions de ces algorithmes. C’est d’ailleurs cette qualité qui amène à leur utilisation dans le but de produire des « deepfakes » difficilement identifiables.
En traitement du langage, les algorithmes génératifs montrent eux aussi des capacités grandissantes version après version alors que le nombre de paramètres de ces algorithmes, la quantité de données sur lesquels ils apprennent et leur coût (financier et écologique) s’accroissent (les dernières versions auraient plus de 1 000 milliards de paramètres).
Alors que les architectures des toutes dernières versions sont restées confidentielles, les architectures des versions précédentes sont accessibles.
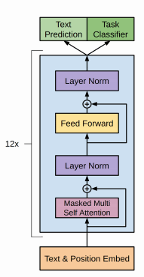 Architecture de GPT –
Architecture de GPT –
Source Radford et al.
Les versions successives du modèle de langage GPT s’appuient sur des versions modifiées de l’architecture de Transformer présentée dont la cellule principale (ici en bleu) est répétée successivement 12 fois.
Ces algorithmes (tout comme les algorithmes de type BERT) ont montré leur capacité à réaliser de nouvelles tâches avec relativement peu d’effort. Il faut pour cela s’appuyer sur une version préentraînée qu’il faudra légèrement optimiser (via une phase d’entraînement supplémentaire) sur des données labélisées (ou sur un nouveau problème de manière non supervisée) pour réaliser la nouvelle tâche.
L’algorithme GPT-2, ayant appris sur un corpus de données très large, avec quelques textes en plusieurs langues (GPT-3 a quant à lui aussi été entraîné sur du langage informatique), cet algorithme peut réaliser plusieurs tâches sans avoir à être réentraîné (apprentissage dit zero-shot), mais simplement en initialisant correctement certains paramètres libres de l’algorithme et le texte de départ.
Ainsi l’algorithme peut non seulement générer du texte, mais aussi en résumer, répondre à des questions, voire traduire des passages de texte.
4 – Algorithmes multimodaux et multitâches
Les capacités grandissantes des algorithmes dont nous avons parlé (BERT, GPT, GAN, Transformers) et leur capacité à réaliser de nouvelles tâches avec relativement peu d’effort – voire en ayant juste à ajuster l’initialisation de l’algorithme au moment de son exécution – offrent un potentiel large et jusqu’à présent relativement inexploré, car les algorithmes étaient limités par ce que l’on appelle l’oubli catastrophique.
Cet oubli catastrophique entraînait, jusqu’à présent une perte de pouvoir prédictif importante sur les anciennes tâches apprises à mesure que l’algorithme en apprenait de nouvelles, ou faisait évoluer ses connaissances sur de nouvelles données. La majorité des algorithmes souffrent de cette limitation.
Lors de la parution de l’article de BERT, les auteurs l’avaient utilisé sur 11 tâches de traitement du langage naturel différentes, en réentraînant légèrement la version initiale sur des données labélisées et pour chacun des problèmes.
Dans le cas des algorithmes de la famille de GPT, l’apprentissage non supervisé utilisé et la grande variété de données permettent de réaliser sans nouvel apprentissage plusieurs tâches, le nombre de tâches réalisables dépendant fortement de la quantité (et la variabilité) des données utilisées pour l’apprentissage (et donc du nombre de paramètres).
Dans les utilisations plus récentes des Transformers, les algorithmes sont entraînés sur plusieurs tâches à la fois, ce qui amène à des algorithmes capables de traiter plusieurs tâches en parallèle, mais aussi à des gains de performance par rapport à des algorithmes qui seraient entraînés à ne réaliser qu’une seule de ces tâches.
De nombreux cas d’usages impliquent l’usage de données de types différents en combinaison (par exemple du texte et de l’image, des bases de données structurées et du texte, etc.). Les concepts les plus complexes sont par ailleurs mieux définis au travers de données multiples.
Afin de pallier aux limitations des algorithmes unimodaux, de nouveaux algorithmes multimodaux émergent désormais tels que CLIP ou DALL-E de OpenAI. Une autre façon d’aborder ces problématiques complexes est d’avoir recours à des approches composites au travers de workflows, combinant différentes approches de traitement du langage naturel, de données tabulaires, de reconnaissance d’image en s’appuyant sur de l’apprentissage machine et des approches d’intelligence artificielle symbolique (règles métiers).
Pour finir, un champ de recherche plus poussé (peut-être le Graal ?) émerge autour des algorithmes tout à la fois multimodaux et multitâches. Les approches d’IA composite peuvent permettre cela au travers de workflows combinant de multiples types de modèles et données, pour réaliser des tâches variées en séquences ou en combinaison.
La combinaison de multiples types de données au sein d’un même algorithme, pour réaliser plusieurs tâches au travers d’un algorithme unique, permet néanmoins d’ouvrir des perspectives inédites où il est par exemple possible de générer des données complexes (rapports, images contenant du texte, image contenant plusieurs objets sur la base d’une phrase indiquant le nombre d’objets, etc.) ou de réaliser des tâches de haut niveau (par exemple obtenir le contenu d’une image ou d’une base de données complexe sur la base d’une question posée en langage naturel).
5 – Algorithmes sur les graphes et GNN (graph neural networks)
Un graphe est un modèle de données qui représente la donnée sous forme de nœuds et de liens. Les nœuds peuvent représenter des personnes, des entreprises, des mots. Et les liens représentent les relations entre ces différentes entités.
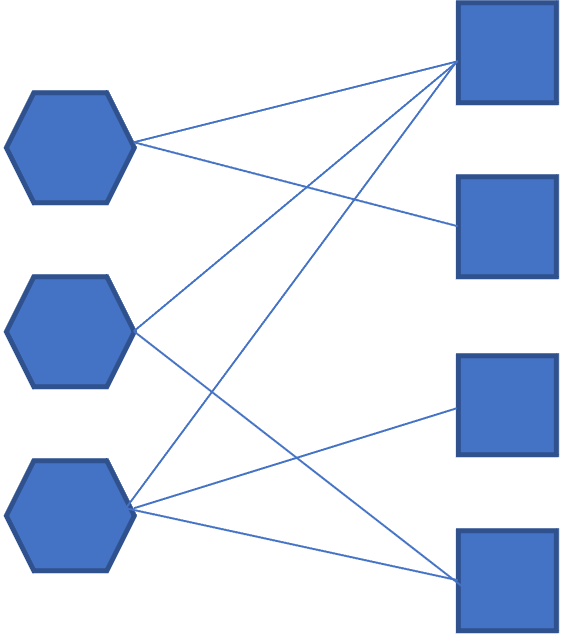 Exemple de graphe avec deux types de nœuds (par exemple personne et objet ou entreprise et fournisseur) et les liens entre ces nœuds.
Exemple de graphe avec deux types de nœuds (par exemple personne et objet ou entreprise et fournisseur) et les liens entre ces nœuds.
Ainsi les représentations des données sous forme de graphes sont de plus en plus utilisées en entreprise pour identifier les liens entre personnes ou entités. Les applications sont nombreuses (visualiser ou modéliser un réseau routier ou informatique, suivre les transactions financières, connaître les relations entre des entreprises et des fournisseurs pour estimer le risque sur une chaîne de valeur, suivre les flux commerciaux entre pays, calculer le nombre d’amis d’une personne sur un réseau social, etc.).
Par ailleurs la donnée (notamment textuelle) est de plus en plus structurée sous forme de bases de connaissances et de graphes de connaissances (ou ontologies). Avec l’émergence des modèles de traitement du langage, que j’ai présentés plus haut, et leur adoption par les entreprises, celles-ci devraient aussi adopter des approches de graphes de connaissance pour mieux structurer et interagir avec l’information contenue dans ces données.
L’analyse de ces graphes dans les applications commerciales est un défi du fait de la taille des graphes. C’est là que rentrent en jeu les algorithmes de traitement de graphes et notamment les GNN (graph neural networks) qui émergent depuis plusieurs années.
Plusieurs cas d’application existent, notamment classifier un nœud (est-ce que cette personne est un fraudeur ?), prédire la relation entre deux nœuds (doit-on recommander ce produit à ce client ?), classifier un graphe entier (quel est le thème de ce texte ?).
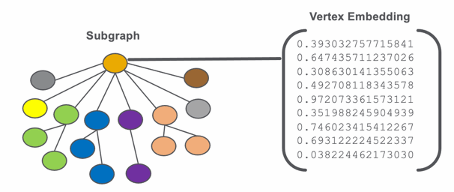 Exemple d’embedding – Source
Dan McCreary
Exemple d’embedding – Source
Dan McCreary
Dans un GNN, le graphe va être tout d’abord transformé pour construire ce que l’on appelle un « embedding », qui va donner une représentation plus simple du graphe, sous forme d’un vecteur unique, qu’un réseau de neurones (par exemple ceux que nous avons présentés plus haut) ; ou un autre algorithme va pouvoir plus facilement traiter pour apprendre les relations importantes et réaliser ensuite les prédictions attendues (par exemple recommander le meilleur produit pour un client donné).
Avec la diffusion des bases de données de graphes, les graphes de connaissance et la multiplication des connexions, les GNN, leurs dérivés et leurs alternatives ont de beaux jours devant eux
6 – Prise en compte de la causalité et algorithme TCN (Temporal convolutional neural networks)
Les algorithmes actuels sont limités par leur absence de généralisation et leur difficulté d’adaptation à des données, dont la distribution à l’exécution est différente de celle lors de l’entraînement (ce que l’on appelle le phénomène de dérive). Ces limites sont problématiques, car lorsque de nouveaux comportements émergent, ou que certains évènements surviennent, les algorithmes peinent à réagir et à adapter leurs réponses.
Par ailleurs, les algorithmes modernes s’appuient généralement sur des corrélations qu’ils ont identifiées, plutôt que sur les causes derrière la survenance des évènements, qu’ils sont pourtant conçus pour prédire et anticiper.
Dans le cas de la dérive des algorithmes du fait d’un changement de distribution de données – ou du lien entre les données d’entrée et l’information à prédire – il est possible de détecter ces dérives et de les corriger, grâce à de l’apprentissage continu, un réentraînement de modèle et les techniques d’un champ en plein essor appelé le MLOps.
De nombreux problèmes peuvent être résolus grâce à ces techniques. Mais en cas de changement brusque, d’évènement soudain, de modification périodique de comportement, il est rarement possible de réagir suffisamment vite. Et le risque est grand de ne plus être en mesure de détecter des comportements historiques que les versions de ces algorithmes précédentes étaient capables de détecter, et toujours susceptibles de se produire dans le futur.
Les besoins d’explications de qualité, la nécessité de comprendre les facteurs déclencheurs (par exemple du départ d’un client, de l’achat d’un produit ou de la survenance d’une maladie), la capacité de s’adapter à des conditions changeantes (par exemple dans le domaine de la voiture autonome) conduisent à la nécessité de passer d’une approche de l’apprentissage par les corrélations à un apprentissage de la causalité.
Ce champ de domaine est naissant, mais quelques applications et algorithmes émergent déjà pour prendre cela mieux en compte.
Dans le domaine du marketing, il est par exemple important de comprendre quelles actions ont déclenché l’achat d’un produit et ont eu un impact sur les revenus. C’est tout l’objet des techniques d’attribution marketing et notamment des problématiques de « uplift modeling » conçues pour identifier les clients en capacité d’être convertis et les actions qui aident à la conversion de ces clients. L’intérêt de cette approche est de permettre au travers de tests A/B de définir des prédictions causales sur le changement du comportement d’un client du fait des actions marketing.
Les algorithmes TCN (Temporal convolutional neural networks) sont des algorithmes particulièrement adaptés à la modélisation de séries temporelles (par exemple des données de marché). La modélisation de séries temporelles est un sujet important pour de nombreux secteurs, qui a fait l’objet de recherche et a permis l’émergence de nouveaux algorithmes utilisés en reconnaissance de la voix, ou en traitement du langage naturel. Mais ces algorithmes souffrent de nombreuses limitations, notamment au niveau du temps de calcul.

Les TCN, dont l’architecture est présentée sur ce schéma, permettent de pallier les limitations de ces précédentes familles d’algorithmes. Leur implémentation est relativement aisée et leur temps d’entraînement réduit, tandis que leurs performances et leur stabilité sont généralement supérieures.
Ces algorithmes ont, par ailleurs, grâce à des couches de convolution causales, une meilleure robustesse et assurent l’absence de fuite de données future [ce qui n’est pas garanti par d’autres approches]. Ils peuvent par ailleurs prendre en compte des historiques de données très longs, sans souffrir des limitations d’autres algorithmes utilisés pour la modélisation des séries temporelles (qui perdent en performance du fait d’un phénomène appelé « vanishing gradients »).
7 – Des deux côtés du spectre : Big Data vs Small Data [et Transfer Learning]
Les précédents points nous ont permis de mettre en avant que les nouvelles générations d’algorithmes s’appuient sur des quantités exponentiellement croissantes de données. Le graphique ci-dessous montre cette croissance exponentielle du nombre de paramètres des modèles d’IA. Et le mouvement continue : GPT3 est 20 fois plus gros avec 175 milliards de paramètres, tandis que Google a présenté une architecture avec 1 000 milliards de paramètres au début de l’année 2021.
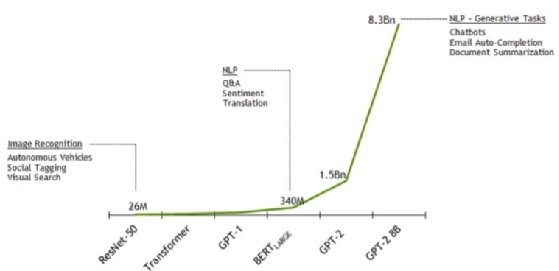
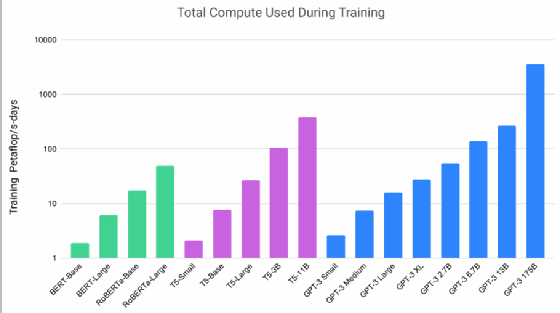
Cette croissance implique le recours à des ressources de calcul significatives, notamment en GPU, et à des infrastructures de calcul adaptées et largement parallélisées.
Comme il n’est pas toujours possible d’avoir recours à de telles infrastructures, il est nécessaire de considérer aussi l’autre côté du spectre. La réalité étant qu’à certaines exceptions près, les jeux de données en entreprise – même lorsqu’ils constituent tous ensemble du Big Data – rentrent séparément dans la catégorie du Small Data. Cela est d’autant plus vrai pour les petites et moyennes entreprises, qui ont-elles aussi des données.
Il est généralement plus compliqué d’avoir des performances élevées avec des petits jeux de données et ces jeux ont plus de chances de contenir des biais importants dont l’impact sera significatif.
Une façon de réussir avec du small data est d’améliorer le préprocessing de la donnée en créant des variables prédictives de haut niveau à partir des données que l’on possède, et en s’appuyant sur son expertise métier.
Si on connaît très bien un problème et que des données ne sont pas facilement accessibles, il est possible d’avoir recours à des règles métier, qui peuvent être combinées à d’autres modèles d’apprentissage machine, ou encore d’utiliser des modèles d’apprentissage très simples.
Il y a bien d’autres techniques qui peuvent être mises en place. Les modèles que j’ai présentés dans cet article permettent aux entreprises de s’affranchir de leur entraînement, car ils sont accessibles en open source pour la plupart – et des entreprises comme DreamQuark proposent des versions packagées de ces algorithmes avec des fonctionnalités supplémentaires. Il est possible de les utiliser pour faire du transfer learning en spécifiant ces modèles avec un minimum de données supplémentaires labélisées (par exemple pour les utiliser dans une application spécifique d’assurance, il ne faut que quelques échantillons de réclamations dont le résultat du traitement est connu).
Ces algorithmes permettent ainsi d’avoir recours à des approches d’apprentissage zero-shot (présentées plus haut).
Si seulement quelques données sont disponibles, une solution est d’avoir recours à des données synthétiques ou d’avoir recours à des techniques d’augmentation de la donnée. Il est aussi possible de commencer avec un premier modèle entraîné sur ce que l’on a comme données et d’adopter des approches d’apprentissage continu pour améliorer au fur et à mesure la performance des algorithmes conçus.
Finalement, il est possible que la donnée labélisée en notre possession soit en petite quantité, mais que nous ayons une quantité beaucoup plus grande de données non labélisées, auquel cas les approches d’apprentissage non supervisé ou de détection d’anomalies pourraient fonctionner.
Conclusion
L’intelligence artificielle est un domaine riche. Nous avons présenté des architectures d’algorithmes ayant émergé au cours des 3 ou 4 dernières années.
Ces approches ont des applications économiques concrètes pour l’amélioration de l’expérience client, la croissance commerciale, la réduction du risque, l’optimisation des processus internes, le développement de nouveaux produits.
Des acteurs – dont DreamQuark – facilitent aussi l’accès à ces algorithmes et leur utilisation au travers d’interfaces intuitives, de kits de développement de logiciels, ou de packages open source avec des fonctionnalités supplémentaires pour résoudre des applications concrètes et faciliter leur mise en production, tout en prenant en compte les enjeux de gouvernance modernes.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que l'apprentissage automatique (AutoML) ?
Par: Ben Lutkevich
-
![]()
Qu'est-ce que le pré-entraînement d'un modèle linguistique amélioré par la recherche ?
Par: Alexander Gillis
-
![]()
L'apprentissage par renforcement à partir du feedback humain (RLHF) ?
Par: Andy Patrizio



