Quelle différence entre Docker et Kubernetes ?
Les deux outils sont complémentaires. Mais là où Docker gère le cycle de vie des containeurs Linux, Kumbernetes gère leur orchestration. Et plus encore.
Une fois tous les cinq ans, le monde de l’IT connait une évolution majeure. Sur les deux décades qui viennent de s’écouler, le paradigme informatique est passé du serveur aux architectures web, qui ont-elles-mêmes maturé pour donner naissance aux architectures orientés services avant de finalement virer vers le Cloud.
Quand AWS a lancé en 2008 Amazon EC2, rien ne pouvait laisser présager que ce portail en self-service - qui permet de provisionner des serveurs virtuels en quelques clics – allait révolutionner la vie des développeurs et des administrateurs.
L’élasticité et l’automatisation du service a pourtant introduit la très puissante notion d’infrastructure programmable. Les applications sont devenues « conscientes » de l’infrastructure et elles ont pu la dimensionner (à la hausse ou à la baisse) de manière dynamique.
Aujourd’hui, nous voyons arriver une nouvelle vague technologique, qui continue le mouvement, avec les « conteneurs », cette technologie qui peut faire tourner plusieurs instances applicatives sur un seul OS.
Docker ressuscite les conteneurs
Le concept de conteneur n’est pas nouveau - FreeBSD, Solaris, Linux et même Windows proposent une forme d’isolement pour faire tourner des applications autonomes.
Quand une application tourne dans un conteneur, elle a l’illusion d’être la seule à avoir accès au système. Ceci n’est pas sans rappeler la virtualisation, où un OS invité a l’illusion d’être le seul à exploiter le hardware sous-jacent.
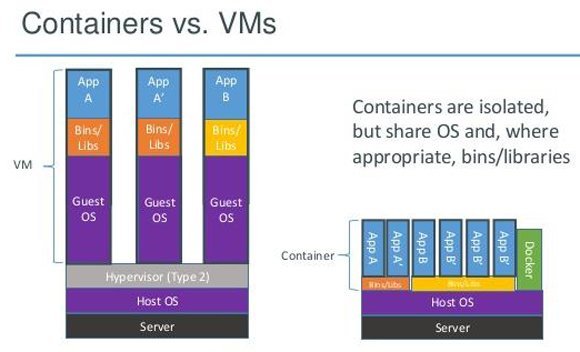
Conteneur et machines virtuelles (VMs) ont certes beaucoup de points communs, mais ils sont fondamentalement différents dans leurs architectures. Les conteneurs sont des processus poids plumes qui tournent sur un OS, là où une VM dépend d’un hyperviseur pour émuler une architecture x86.
Du fait de l’absence d’hyperviseurs, les conteneurs sont plus légers, plus rapides, plus efficaces et plus simples à gérer.
Une des sociétés à avoir démocratiser l’utilisation des conteneurs Linux est Docker.
Docker n’a pas créé la technologie, mais on doit lui créditer d’avoir construit un ensemble d’outils et d’API qui ont rendu les conteneurs beaucoup plus facilement gérables.
Comme souvent avec les nouveautés, le succès de Docker est aussi dû au fait qu’il est arrivé au bon moment, pile quand l’industrie cherchait un moyen de mieux gérer le Cloud et ses workloads Web.
Ceci dit, Docker est plus qu’une trousse à outils. La société a aussi fédéré tout un écosystème, foisonnant, qui a commencé à contribuer à un ensemble divers d’outils de gestion des cycles de vie des conteneurs.
En juin 2014, la DockerCon, la première conférence jamais organisée sur le sujet, a par exemple pu se targuer de la présence d’acteurs majeurs comme Google, IBM, Microsoft, Amazon, Facebook, Twitter ou Rackspace, tous venus témoigner de leurs utilisations des conteneurs.
Comment Google fait tourner des workloads critiques dans des conteneurs
Si Docker est dans la lumière des projecteurs, une autre entreprise – qui maîtrise l’art du dimensionnement – est passé maître dans l’art d’utiliser les conteneurs pour ses workloads de production. Cette société s’appelle Google.
Google gère en effet chaque semaine plus de deux milliards de conteneurs. Des services comme Gmail, Search, Apps ou Maps tournent tous dans des conteneurs.
Et aussi
Demandez à n’importe quel administrateur qui a eu à gérer plusieurs centaines de VMs et il vous dira que c’est un vrai cauchemar. Mais gérer des conteneurs s’avère très différent.
Sur la décennie écoulée, Google a ainsi conçu plusieurs outils pour gérer un nombre très important de conteneurs. Lorsqu’il s’est lancé en tant que fournisseur de Cloud (avec App Engine et Compute Engine) Google a ouvert ces outils de gestions aux développeurs. Ce qui bénéfice à la communauté mais qui permet aussi de différencier Google Cloud Paltform.
Kumbernetes : une nouvelle ère pour les containeurs
Un des principaux outils que Google a rendu open-source s’appelle Kumbernetes - qui signifie en grec « pilote » ou « barreur ».
Kumbernetes fonctionne en complément de Docker. Alors que Docker permet de gérer le cycle de vie des conteneurs, Kumbernetes apporte l’orchestration et la gestion de clusters de conteneurs.
Pour bien comprendre la différence, il faut faire une plongée dans la manière dont fonctionne le IaaS.
Les clients qui provisionnent des VMs sur AWS, Azure ou sur n’importe quel Cloud Public, n’ont que faire de ce qui se passe du côté du hardware. Du moment qu’ils ont les VMs qu’ils souhaitent, avec les bonnes performances qui vont avec, ils ne se préoccupent pas de savoir comment cela marche « en dessous ». Savoir si les serveurs physiques d’AWS sont de chez HP, Dell ou IBM est le cadet de ses soucis.
L’utilisateur choisit un type d’instance, un OS, une zone géographique et c’est tout. Côté fournisseur, un outil logiciel – appelé orchestrateur, ou « fabric controller » - prend en charge le provisionnement de la VM sur une des serveurs physiques disponibles dans le datacenter. En résumé, la couche IaaS fait complètement abstraction de la couche hardware.
Lorsque l’on provisionne un conteneur, le même processus intervient. Mais à la place de provisionner une nouvelle VM, le moteur d’orchestration de conteneurs peut décider de booter un conteneur dans une VM existante. Ou, en analysant la disponibilité des VMs déjà créées, il peut tout aussi bien décider de lancer une nouvelle VM pour booter le conteneur dessus.
On peut donc dire que l’outil d’orchestration de conteneurs fait aux VMs ce que le Fabric Controller fait au matériel physique.
Kumbernetes va donc bien au-delà de la création de conteneurs.
Avec cet outil de gestion et de monitoring, les administrateurs peuvent aussi créer des Pods, des collections de conteneurs liés à une application. Ces Pods sont provisionnés dans des VMs ou sur des serveurs bare-metal.
Traditionnellement, les PaaS – comme Azure, App Engine, Cloud Foundry, OpenShift, Heroku ou Engine Yard – donnent la possibilité de faire tourner du code sans se préoccuper de l’infrastructure. Les développeurs y hébergent leurs codes et fournissent des métadonnées qui explicitent les exigences et les dépendances de l’application.
Le moteur du PaaS analyse ces metadonnées de configuration et provisionne le code. Une fois en production, le PaaS dimensionne les ressources, monitore et gère le cycle de vie de l’application.
Pour faire court, Kumbernetes et Docker tiennent les promesses du PaaS en simplifiant le processus.
Une fois que l’administrateur système a configuré et déployé Kumbernetes sur une architecture spécifique, les développeurs peuvent commencer à pousser leurs codes dans le cluster, ce qui cache la complexité des manipulations en lignes de commande et évite d’avoir à utiliser les APIs et les tableaux de bord spécifiques des fournisseurs de IaaS.
Les développeurs peuvent définir leurs applications de manière déclarative et Kumbernetes utilisera ces informations pour provisionner et gérer des Pods. Si le code, le containeur ou la VM viennent à faillir, Kumbernetes remplacera l’entité par une autre en état de marche.
Actuellement, Kumbernetes est supporté par les environnements Google Compute Engine, Rackspace, Microsoft Azure et vSphere. Quant à Red Hat et Pivotal, ils travaillent sur l’intégration de Docker et Kubernetes à CloudFoundry et OpenShift.



