
CERN OpenLab liste les défis auxquels est confrontée l'IT du CERN
La structure de partenariat public/privé créée par l'IT du CERN vient de publier un livre blanc listant les défis auxquels est confrontée l'organisation face à l'explosion des besoins du centre de recherche en matière de puissance de calcul, de bande passante réseau et de stockage.

CERN OpenLab est une structure originale sous partenariat public-privé qui réunit des équipes du CERN et plusieurs de ses grands fournisseurs de technologies IT (comme Brocade, Cisco, Huawei, Oracle, Intel, Rackspace, Siemens ou Seagate). Elle vient de publier un livre blanc qui inventorie les défis auxquels elle est confrontée du fait de la croissance exponentielle des besoins de traitement et de stockage générés par les derniers projets de recherche du CERN.
CERN OpenLab a classé ces défis en 4 catégories. La première concerne les infrastructures de datacenter. La seconde porte sur l’évolution de ses codes logiciels et sur l’optimisation de leur performance.La troisième s’intéresse à l’impact du machine learning et des technologies d’analyse de données sur les données produites par les installations scientifiques du CERN. La dernière s’intéresse aux applications possibles des travaux menés au sein de l’IT de l’organisme d’étude de la physique des particules à d’autres domaines scientifiques, comme l’astrophysique, les sciences de la vie, etc.
Relever le défi de l’hyperscale
En matière d’infrastructure, les problématiques du CERN sont assez uniques. Le cloud OpenStack interne de l’organisme, créé en 2012 et opérationnel en production depuis 2013, exploite actuellement près de 270 000 cœurs processeurs. Les infrastructures du centre sont réparties entre le datacenter historique de Meyrin, en Suisse (10 000 serveurs bisocket et 300 000 cœurs) et celui de Wigner près de Budapest (3500 serveurs et 100 000 cœurs), deux sites reliés par trois fibres optiques à 100 Gbit/s.
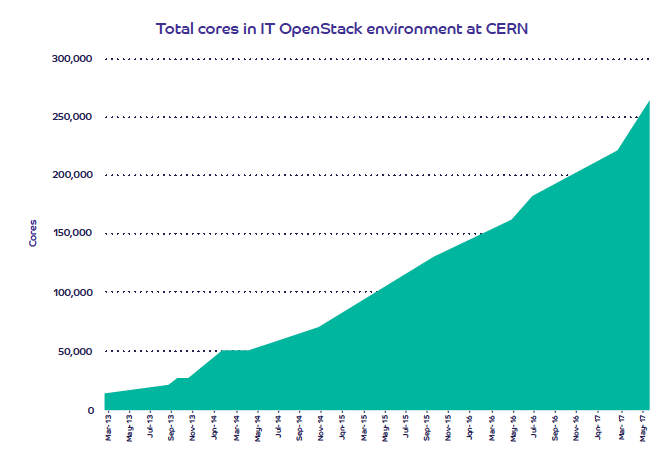 Evolution de l'infrastructure OpenStack du CERN (en nombre de coeurs CPU)
Evolution de l'infrastructure OpenStack du CERN (en nombre de coeurs CPU)
Cette infrastructure, directement opérée par le CERN, est complétée par une grille mondiale chargée de traiter les données issues du grand collisionneur de Haedrons (LHC- Large Haedron Collider).
L’IT du CERN est actuellement dimensionnée pour faire face aux besoins du centre, mais elle ne fera pas le poids face aux besoins des nouvelles expériences prévues pour les prochaines années. En 2021, par exemple, le CERN commencera le troisième cycle d’expériences sur le LHC, un cycle qui devrait générer entre deux et trois fois plus de données qu’aujourd’hui. Au milieu des années 2020, les besoins de traitement devraient avoir été multipliés par 50 à 100 par rapport à aujourd’hui, un challenge auquel le CERN doit trouver des réponses sans faire exploser un budget serré.
Le centre a identifié plusieurs axes de recherche clé pour la transformation de son infrastructure portant sur les technologies réseau, les architectures de datacenter et le stockage.
Adapter les architectures réseau et système
En matière de réseau, le CERN s’intéresse notamment aux applications du DWDM au sein du datacenter pour permettre de transmettre des données non filtrées directement depuis les sites d’expérimentation du LHC vers le datacenter (ce qui nécessite des débits en dizaines de terabit/s sur une paire de fibres. L’organisme de recherche étudie aussi les applications des équipements réseau en marque blanche couplés à un plan de contrôle 100 % logiciel. L’objectif est non seulement de faciliter le provisioning des équipements (déploiement dit « zero-touch »), mais également de rendre plus flexibles les changements de configurations.
Dans le cadre de ses réflexions sur la construction d’un nouveau datacenter (4 MW au début et jusqu’à 12 à 16 MW au final), le CERN s’intéresse aussi à la désagrégation des ressources informatiques au sein du datacenter, une approche qui lui permettrait de réallouer de façon plus souple les ressources disponibles aux différentes applications. Le centre étudie aussi de nouvelles approches de stockage qui combineraient stockage électronique non volatile et disques durs au sein de pools massifs à l’échelle du rack. Il envisage également de mettre en œuvre des technologies Flash à haute densité et à bas coûts (vraisemblablement de la NAND QLC) pour son stockage de données à froid, une approche qui reléguerait la bande au seul archivage de données.
OpenStack pour coordonnées les ressources d’infrastructure
Toutes ces réflexions technologiques devront s’intégrer à la grille OpenStack massive du CERN, déjà forte de près de 300 000 cœurs CPU et qui en accueille plusieurs dizaines de milliers d’autres par an. Pour cela, le cloud OpenStack devra évoluer pour gérer les nouvelles infrastructures désagrégées et permettre leur provisioning.
Vu l’échelle à laquelle travaille le CERN, l’organisme entend approfondir ses travaux autour d’OpenStack Cells, qui permet d’opérer un grand cloud OpenStack de façon distribuée. Le centre continuera aussi ses travaux autour du Software Defined Networking et en particulier d’OpenStack Neutron. Il entend enfin travailler sur une meilleure compréhension de l’usage des ressources et en particulier sur la mise en oeuvre de mécanismes d’intelligence artificielle pour optimiser l’utilisation des ressources au sein du cloud.
Au sein du CERN, l’IT Analytics Working Group a ainsi commencé à appliquer des méthodes d’analyse statistique et de machine learning aux vastes quantités de métriques remontées par le cloud (en matière de CPU, de consommation de stockage, de topologie réseau et de flux). Il a obtenu de premiers résultats encourageants en matière de placement de workload et d’optimisation de l’usage des ressources.
Pour approfondir sur HPC
-
![]()
Le Cern se dote d’un nouveau datacenter plus vert
Par: Pierre Berlemont
-
![]()
Infrastructures cloud : le Français Thierry Carrez prend les rênes d’OpenStack
Par: Yann Serra
-
![]()
LHC : le CERN teste un data warehouse autonome
Par: Alain Clapaud
-
![]()
Les 7 entreprises qui ont réenchanté leur datacenter en 2019
Par: Yann Serra


