Trifacta veut accélérer la préparation des données
La société s’appuie sur une technologie qui automatise les suggestions de transformation de données et de détection d’erreurs. Google en a fait une pièce de son outil Dataprep.

Accélérer la valorisation des données en plaçant leur préparation entre les mains des métiers. C’est l’enjeu qu’a décidé de relever Trifacta, une société américaine qui s’est fait un spécialiste du secteur auto-baptisé du « Data Wrangling » - cela consiste à assembler, transformer, nettoyer et enrichir un ensemble de données disparates. Si la société n’est pas une inconnue, celle-ci a en revanche évolué.
Entrée dans les entreprises pour des besoins d’analyse en volume, aussi bien dans les grandes entreprises que dans le secteur de la recherche, la société a vu progressivement sa cible s’étendre vers des sociétés dont la manipulation des données est le cœur de métier, nous a expliqué Bertrand Cariou, directeur marketing en charge des solutions et des partenaires chez Trifacta, rencontré dans leurs locaux de San Francisco. D’entreprises plus petites, comme celles du secteur du marketing digital ou encore du CRM. Bertrand Cariou cite par exemple Nation Builder, un outil de CRM que nombre de partis politiques français se sont appropriés lors des dernières élections. Au-delà, Trifacta compte parmi ses clients des banques comme Santander ou la Royal Bank of Scotland, des multinationales comme PepsiCo, mais aussi la Nasa.
Il faut dire que Trifacta souhaite accélérer l’exploitation des données, en raccourcissant les délais, généralement longs, portant sur leur préparation. Une étape qui compte généralement pour 80% du temps avant même de pouvoir utiliser les données. Trifacta souhaite donc raccourcir ces temps de préparation, qui comportent une multitude d’étapes placées entre les mains d’experts (des tâches comme la découverte des données, leur structuration, leur nettoyage, leur enrichissement, le blending et l’optimisation, …)
La société s’adosse donc à une technologie qui pré-mâche ces traitements. « La majeure partie de nos utilisateurs sont des utilisateurs d'Excel », poursuit Bertrand Cariou.
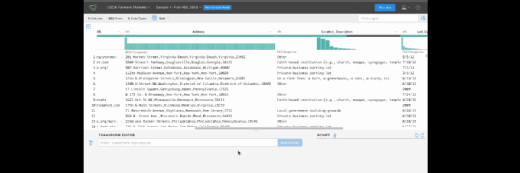
Concrètement, les fichiers de données sont importés dans Trifacta. La solution applique une série d’algorithmes et détermine automatiquement le meilleur tri et rangement des données dans une grille d’analyse. Cette grille affiche des notions de qualité, pour repérer les erreurs et détecter d’éventuelles anomalies. « Il s’agit de la première évaluation des données », commente-t-il. Trois types de valeur sont attribués aux données qui étiquettent leur niveau de qualité (Succeeded, Incomplete Terminated). L’utilisateur peut ensuite interagir avec les données, grâce à un mode de sélection interactif. « Trifacta demande par exemple ce que l'utilisateur veut faire avec les données, comme conserver les colonnes ou les supprimer- le tout en fonction des statuts établis », commente-t-il. En gros, la solution suggère automatiquement des modifications, des erreurs et des transformations à réaliser.
Ces étapes sont réalisées via des algorithmes de Machine Learning, qui s’enrichissent au fur et mesure des versions, rappelle Bertrand Cariou, afin d’ajouter d’autres cas d’usage.
Les performances de la plateforme sont soutenues par Photon Compute Framework, un framework maison qui s’appuie notamment sur une série d’outils comme le In-Memory, le traitement multi-threadé ou encore la compression des colonnes. L’objectif est par exemple de permettre de traiter un grand volume de données disparates et non structurées dans Trifacta, sans dégrader les performances de l’interface et les suggestions automatiques de l’outil.
Un accord avec Google dans le Cloud
Cette interface, et ces méthodes de sélection intuitives et automatisées, ont récemment retenu l’attention…de Google pour un service de préparation de données 100% Cloud nommé Dataprep. Présenté à l’occasion de GoogleNext qui s’est tenu début mars à San Francisco, ce service Cloud reprend fondamentalement les principes clés de Trifacta : explorer et découvrir des données brutes et les nettoyer afin de les rendre « consommables » et ainsi exploitables pour analyses. Sur la plateforme Cloud de Google, cela se traduit ainsi par une proximité native de Big Query, le service d’analyse de données en volume, et DataFlow, un service de traitements de données unifié (dont le moteur a été placé dans l’Open Source, au sein du projet Apache Beam).
Pour Trifacta, ce partenariat avec Google s’apparente, certes à une validation de sa technologie et de son modèle, mais constitue aussi un potentiel de croissance important alors que Mountain View cherche justement à faire entrer les services de sa plateforme dans les entreprises. Ce qu’il peine à faire, face à Microsoft Azure et AWS, le n°1 du secteur. Trifacta représente aussi pour Google une autre porte d’entrée vers les départements métiers et de science de la donnée des entreprises.
Pour approfondir sur Outils décisionnels et analytiques
-
![]()
WeTransfer : le Toulousain NetExplorer lance une alternative souveraine
Par: Philippe Ducellier
-
![]()
Analytics Cloud : Alteryx passe la seconde
Par: Eric Avidon
-
![]()
AI Act : la CNIL se prépare en créant un nouveau service
Par: Gaétan Raoul
-
![]()
Alteryx unifie (enfin) ses fonctionnalités cloud dans une seule plateforme
Par: Eric Avidon



