
JFrog s’attaque au ML(Sec)Ops
Le spécialiste de l’approvisionnement logiciel entend s’illustrer dans le domaine du MLOps en comblant le fossé qui sépare les équipes de data science et celles formées à l’approche DevOps. Un pari sur l’avenir.

Lors de son événement DevSecOpsDays Paris 2024, face à une audience davantage intéressée par ses solutions de sécurisation de la SDLC, JFrog a présenté plus en détail sa stratégie en matière de MLOps et de MLSecOps.
Le mariage entre une grenouille et un canard
En effet, en juin dernier, le spécialiste de la gestion et de la sécurité de la chaîne d’approvisionnement logicielle a racheté Qwak AI, une jeune pousse israélienne fondée en 2020 et ayant levé 27 millions de dollars au total. Son logo ? Un canard.
Qwak a développé une plateforme pour entraîner, compiler, déployer et superviser des modèles de machine learning et de deep learning, dont les fameux grands modèles de langage.
« Selon Gartner, 90 % des entreprises adopteront le machine learning d’ici à 2027 », déclare Ran Romano, vice-président ingénierie et produit, MLOps, chez JFrog et cofondateur de Qwak AI. « Dans un même temps, le cabinet d’analystes estime que 85 % des projets de ML et d’IA n’atteignent pas le stade de la production ».
Un écart de maturité à combler entre les développeurs et les data scientists
Parmi les nombreuses raisons qui peuvent expliquer ce phénomène, Ran Romano en retient trois qui « s’entrelacent ».
« Les data scientists et les ingénieurs ML ne sont pas des ingénieurs logiciels. Ils n’ont pas une philosophie de la mise en production ni l’expérience des problèmes rencontrés habituellement par les ingénieurs logiciels », affirme Ran Romano.
De fait, l’approche DevOps est née il y a dix-sept ans. Les ingénieurs IT ont eu le temps de bâtir les bonnes pratiques et de s’y accoutumer. À titre de comparaison, la naissance du terme MLOps découle d’un article publié en 2015 par des chercheurs chez Google intitulé la « dette technique cachée dans les systèmes de machine learning », mais est concomitante de la naissance de deux projets Google – Kubeflow et Tensorflow Extended –, en 2018. Du fait de l’explosion des projets d’IA, Ran Romano constate que les équipes de data science ont dû s’adapter à marche forcée.
De plus, « les data scientists ne travaillent pas de manière complètement autonome », poursuit-il. « Ils ne sont généralement pas capables de déployer un modèle en production seuls. Ils s’appuient sur les ingénieurs logiciels pour orchestrer l’ensemble du processus. Ils ont aussi besoin des ingénieurs DevOps pour gérer la production, superviser les charges de travail, mettre en place des systèmes de surveillance et garantir la conformité et la sécurité. Enfin, ils dépendent des ingénieurs en données ».
Les équipes de data science rencontrent divers défis tout au long du cycle de vie de l’apprentissage automatique, qui diffère du génie logiciel classique, signale-t-il. Tout commence par l’accès et la préparation des données issues de systèmes variés (entrepôts, bases de données, système de streaming).
L’apprentissage automatique, expérimental par nature, nécessite des notebooks pour explorer les données, entraîner et ajuster les modèles. Ensuite, l’évaluation et la surveillance des modèles en production sont complexes. « Même un taux d’erreur nul peut produire des résultats non pertinents pour les besoins métier ». Enfin, le déploiement, l’orchestration, la gestion via des registres de modèles et les nouvelles exigences liées aux LLM, comme les bases de données vectorielles, ajoutent encore plus de complexité à ce processus. Et Ran Romano d’afficher en présentation une pile technologique particulièrement éclatée. La voici.
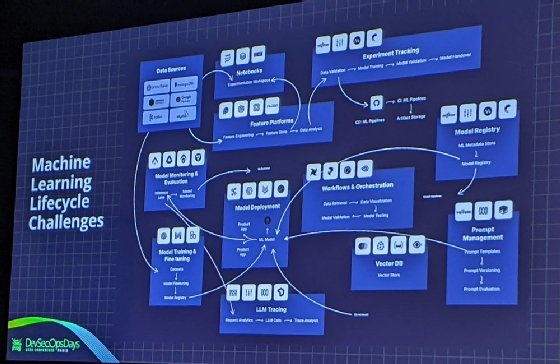
« EveryOps » : JFrog veut établir un pont entre MLOps et DevOps
Et c’est justement pour abattre cette barrière entre les équipes DevOps et de Data science que JFrog encourage ses clients à combiner JFrog ML, le renommage de la plateforme Qwak, avec ses outils.
Dans cette configuration « unifiée », JFrog Artifactory devient le registre des modèles, le dépôt des paquets Python et le registre de conteneurs. Il est également possible de mettre en cache des modèles depuis Huggingface dans Artifactory. Les expérimentations, l’entraînement, le fine-tuning, le déploiement et la supervision des modèles peuvent être gérés depuis JFrog ML. Elle dispose par ailleurs d’un Feature Store et d’une base de données vectorielle.
Quant aux jeux de données, le code des modèles et les binaires des modèles et des outils utilisés peuvent être auscultés à l’aide des outils Xray, Advanced Security, Curation et Runtime Security.
« Nous bénéficions en fait de tous les aspects de la sécurité qui ont été intégrés dans la plateforme JFrog et nous les adaptons au domaine du MLOps », vante Ran Romano.
Tout pour éviter les couacs en production
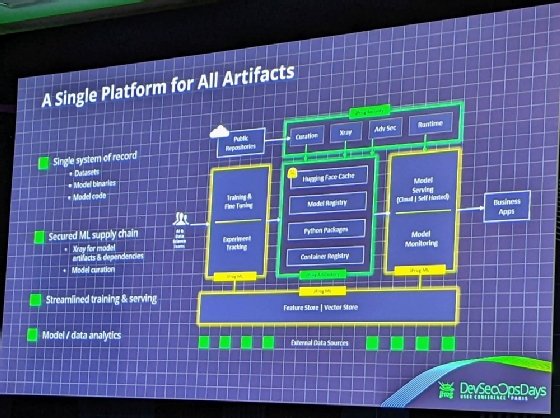
Dans une démonstration, le responsable produit présente le processus en détail.
Il s’agit d’abord de connecter JFrog ML à Artifactory et à Hugging Face. Pour l’instant, l’intégration est principalement manuelle, mais l’éditeur a prévu de la simplifier. Artifactory est alors le centre de gestion de dépendances des projets ML. « Cela permet d’utiliser uniquement des paquets approuvés, en évitant les fuites de données ou de modèles non désirées », assure Ran Romano.
JFrogML standardise les projets ML en introduisant un concept de « build ». « Un build de modèle est une instance de modèle entraînée, sérialisée et testée, regroupée avec les dépendances nécessaires qui peuvent être déployées en production », indique l’éditeur dans sa documentation.
Le processus de build implique la création d’un environnement virtuel, l’exécution de tests unitaires et d’intégration, la sérialisation (versioning) du modèle, la création d’une image Docker et son transfert vers le registre des modèles, ici Artifactory. Un SDK est disponible pour lancer ce processus depuis un IDE ou un notebook.
Des scans sont effectués à la recherche de vulnérabilités. « Il se peut qu’il n’y ait aucune vulnérabilité dans le modèle ML, mais en trouver une dans l’un des packages utilisés, ce qui peut être une dépendance transitive », indique Ran Romano. « Nous scannons un ensemble de vulnérabilités et les affichons. Grâce à X-ray et Curation, nous recherchons des violations de politiques et analysons les composants logiciels et leurs licences. Des politiques peuvent être définies pour empêcher les builds vulnérables d’atteindre la production ».
« C’est crucial », renchérit Fred Simon, cofondateur et chief Data Scientist chez JFrog, auprès du MagIT. « Notre équipe de chercheurs en sécurité a trouvé plus de 60 dépôts Huggingface malicieux. Les attaquants cherchent à se servir des machines des data scientists comme point d’entrée dans des systèmes d’entreprise et les dépendances Python sont de gros vecteurs pour cela ».
La sérialisation permet entre autres de mener une stratégie de déploiement « shadow », c’est-à-dire la possibilité d’adapter le principe d’A/B Testing au machine learning. Il s’agit de tester des modèles avec des données de production sans les exposer directement aux utilisateurs et sans impacter l’application associée. Une fonctionnalité de déploiement canari spécifique aux modèles IA/ML est également à l’étude.
Pour suivre différentes métriques et surveiller le déploiement et le comportement des modèles, JFrog propose sa propre instance Prometheus couplée à Grafana (les visualisations sont embarquées dans l’interface de Jfrog ML). Il est toutefois possible d’exporter les métriques vers un Grafana interne.
JFrog se rapproche de Nvidia pour sécuriser les NIM
Ce n’est pas tout. JFrog a annoncé en septembre un partenariat avec Nvidia. Il s’agit d’intégrer Artifactory et le registre de modèles de Nvidia NIM, les microservices d’inférence contenant – généralement – de grands modèles de langage. Ceux-ci sont référencés à partir du Hub Nvidia NGC. « Une des premières choses que nos clients communs avec Nvidia nous ont dites, c’est qu’ils ne voulaient pas télécharger directement les conteneurs chez Nvidia pour les déployer sur un environnement Kubernetes interne », explique Fred Simon. « Il faut que cela passe par des validations et par un cycle de développement traditionnel DevOps ».
Avec Nvidia, JFrog entend également simplifier les processus de déploiements des NIM sur différentes infrastructures, sur site ou dans le cloud.
Un pari sur l’avenir
JFrog ML est un pari. Les entreprises ont potentiellement mis en place des chaînes d’approvisionnement des modèles et – comme le laissent entendre les analystes de Gartner – n’ont pas encore des taux de réussite très élevés. « Notre approche unifiée du MLOps résonne auprès des clients, même si cela prendra du temps au vu de leur maturité. », note Fred Simon.
Pour l’instant, le site de JFrog ML laisse à voir les retours d’expérience de neuf clients.
Le 7 novembre, lors de la présentation des résultats du troisième trimestre fiscal 2024 aux analystes, Shlomi Ben Haim, cofondateur et CEO de JFrog, a été interrogé sur les retombées potentielles de la solution MLOps en 2025.
« Mettons les choses au clair : l’IA équivaut à des modèles, et les modèles sont des binaires. Si nous semons les bonnes graines aujourd’hui, nous en récolterons les fruits, mais la question du “quand” reste ouverte », répond-il. « Actuellement, mes clients, y compris ceux qui paient pour la solution MLOps, sont encore en phase d’expérimentation », poursuit-il. « Même ceux qui ont osé aller en production se concentrent sur des questions de conformité, sécurité, adoption, échelle et budget. Nous investissons dans la R&D pour tracer un chemin vers une croissance future ».
Pour Fred Simon, actuellement, les clients souhaitent surtout se servir d’Artifactory comme un « proxy » pour le déploiement des paquets et des modèles en provenance de systèmes tiers. C’est le poste-frontière à l’entrée des artefacts liés au machine learning et à l’IA.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
carte-modèles dans l'apprentissage automatique
Par: Stephen Bigelow
-
![]()
JFrog s’adapte à l’infusion de l’IA dans la chaîne de livraison logicielle
Par: Gaétan Raoul
-
![]()
DevSecOps : GitHub et JFrog rapprochent leurs outils
Par: Nicole Laskowski
-
![]()
MWC 2024 : Dell et HPE rivalisent avec les équipementiers télécoms
Par: Yann Serra



