Lumière sur LightOn : l’IA générative française « sur mesure » et sur site
LightOn permet de déployer une IA générative et un RAG qui sont entièrement maîtrisés par l’entreprise cliente. Une solution particulièrement adaptée pour les secteurs critiques. En pleine croissance, l’éditeur est profitable et livre au MagIT ses pistes de R&D et de développement.
La France a plusieurs pépites dans l’IA générative. Moins grand public que Mistral, LightOn a été un précurseur dans le domaine des grands modèles de langage (LLM).
« Nous nous positionnons aujourd’hui plus sur les couches au-dessus du LLM », confirme Laurent Daudet, DG et co-fondateur de LightOn. « Mais nous savons toujours en faire ». Depuis sa création en 2016, LightOn en a conçu une douzaine, dont certains de plus de 100 milliards de paramètres. « Nous pensons néanmoins que la valeur se situe plutôt dans l’application de ces LLMs pour les besoins des entreprises : déploiement, gestion du cycle de vie, les RAGs, hybrider les moteurs de recherche interne avec l’IA générative ».
Dans cette optique désormais plus « application », LightOn s’intéresse particulièrement à la mise en place d’« agents ». Ces agents « sont capables de travailler sur des workflows complexes et des données hétérogènes ».
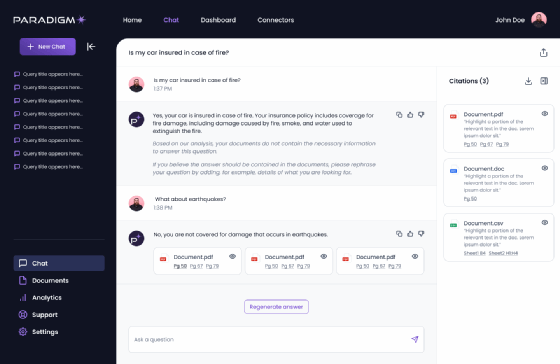
Concrètement, LightOn propose une plateforme, Paradigm, qui repose sur un modèle d’IA générative, Alfred. Alfred est un modèle Falcon (un LLM open source, à 40 milliards de paramètres) avec un fine tuning spécifique et optimisé pour le RAG. « Nous considérons que 40 milliards, c’est un bon compromis entre la performance et le fait de pouvoir le déployer sur une infrastructure qui ne soit pas trop gigantesque et trop coûteuse », justifie Laurent Daudet.
Côté utilisateur, Paradigm propose aussi des fonctionnalités originales comme la « Task Factory » qui aide à faire des prompts. « Par exemple, “draft an email response” est un prompt qui n’est pas assez complet », illustre le DG. « L’outil va vous poser des questions pour enrichir la demande : voulez-vous des choses qui soient précises ? Claires ? Très professionnelles ? ».
Des LLMs sur site et sous contrôle
« 40 milliards de paramètres est un bon compromis entre la performance et le fait de pouvoir le déployer sur une infrastructure pas trop gigantesque. »
Laurent DaudetDG et co-fondateur de LightOn
Mais une spécificité majeure de LightOn est de s’installer on-premise (sur site) sur les serveurs des clients ou sur des clouds privés. Ce qui permet de garder la main sur la totalité de l’IA. L’éditeur a même fait du air-gap pour le secteur de la défense.
« Nous déployons chez eux toute la plateforme Paradigm, dont le LLM, mais aussi tout l’environnement c’est-à-dire de quoi faire des embeddings, des bases de données de texte, etc. ».
Même si le déploiement est accompagné, LightOn a des outils pour automatiser cette tâche.
L’éditeur français cible donc les grands comptes des secteurs critiques qui veulent avoir leur IA générative totalement sous contrôle, particulièrement – mais pas que – les banques et assurances, la santé, la défense (Safran) ou encore les pouvoirs publics (Conseil Régional d’Île-de-France) ou assimilés (Docapost).
Partenariats avec Orange Business
Paradigm peut aussi être déployé sur n’importe quel IaaS d’hyperscaler (comme Azure) ou souverain (comme OVHcloud, Outscale ou Scaleway).
« Depuis à peu près une année, les clouders français commencent à avoir de bons GPU », se réjouit Laurent Daudet.
LightOn vient d’ailleurs de passer un partenariat avec Orange Business, qui va aussi proposer ce type de hardware sur son infrastructure. L’accord concerne également sa filiale Business & Décision pour le conseil et l’intégration.
L’atout RAG
L’éditeur a aussi spécialisé ses compétences sur le RAG (Retrieval Augmenterd Generation), cette technologie qui permet de recentrer un LLM sur un corpus d’informations bien défini.
LightOn a par exemple travaillé avec le Comité régional de l’île de France – qui voulait faire diminuer le nombre de tickets au support IT.
« Nous avons mis en place un système RAG sur toute la documentation de tout leur service IT sur plus de 200 sous-systèmes », illustre Laurent Daudet. « C’est un corpus assez complexe. Mais depuis, les utilisateurs peuvent interroger cette base de connaissances (comment réinitialiser son mot de passe, etc.) directement, via un chatbot et en langage naturel ».
Même principe chez Safran qui a déployé LightOn pour faire un système de recherche dans ses documents de R&D (articles, brevets, etc.).
Parmi les principaux usages où LightOn a été choisi, le DG cite la recherche, le résumé et la synthèse de documents, l’analyse de mails de plaintes (service client), ou encore l’écriture et la standardisation de fiches produits à partir d’informations communiquées par des fournisseurs différents (e-commerce).
La GenAI « sur mesure »
Face aux géants de l’IT qui embarquent l’intelligence artificielle et qui infusent des LLMs directement dans leurs solutions, l’éditeur français joue aussi la carte du « sur mesure ».
« La vérité c’est que le RAG sur étagère ça ne marche pas »
Laurent DaudetDG et co-fondateur de LightOn
« Nous avons un côté transversal et horizontal. Nous sommes présents sur toute la chaîne de valeur. Nous sommes capables de fine-tuner le LLM pour le client, sur des corpus particuliers, ou de créer des agents particuliers », confirme Laurent Daudet.
Aujourd’hui, le RAG est même devenu le cœur de l’offre de LightOn. « Il y a beaucoup de gens qui prétendent qu’en trois clics on a un RAG. La vérité c’est que le RAG sur étagère ça ne marche pas », constate le DG.
De fait, LightOn est aujourd’hui plus en concurrence avec un AI 21, un Cohere ou un Aleph Alpha qu’avec Mistral, Anthropic et autres OpenAI.
Une tarification au serveur
Côté prix, LightOn facture au serveur installé. « Comme nous sommes on-prem, nous ne voulons pas facturer à l’usage, parce que nous ne voulons pas monitorer cet usage. Le client achète une licence Paradigm pour une installation, et il peut s’en servir autant qu’il veut ».
Fine-tuner un modèle demande en revanche deux licences (l’opération demandant deux serveurs).
Le nombre de licences peut également augmenter si l’usage, et donc la charge, augmente. Par exemple « si vous commencez par un usage de support en interne, et que vous généralisez l’aide en l’ouvrant à l’extérieur ».
Un serveur peut supporter quelques dizaines d’utilisateurs en simultané. « Cela dépend de plusieurs facteurs, dont la taille des requêtes. Mais typiquement, un serveur sert parfaitement une business unit », résume le DG.
Agent vs Chatbot
Voilà pour le présent. Pour l’avenir, la R&D de LightOn travaille sur des « agents » qui devraient arriver dans le produit d’ici quelques mois.
Mais quelle est la différence entre un chatbot (déjà disponible) et un agent ? Pour LightOn un chatbot est une interface avancée pour du Q&A. Par exemple, un bot alimenté par un LLM répondra à la question « comment poser des congés ? »… en citant ses sources, insiste Laurent Daudet, « ce qui minimise les risques d’hallucination ».
LightOn en action
Un agent va plus loin. « Un chatbot fait un seul appel au LLM pour obtenir la réponse. Un agent va faire plusieurs appels successifs. Il va prendre la sortie d’un appel pour la réintégrer dans le suivant. Il travaillera aussi sur des données plus hétérogènes, par exemple sur les tableaux de chiffres. En résumé, il y a de la planification et du raisonnement dans un agent. Et il peut aussi aller chercher sur le web ».
À terme, on peut aussi imaginer des agents qui interagissent avec d’autres systèmes, par exemple pour poser les jours de congés dans le SIRH.
D’autres options de LLMs que Falcon devraient également être rapidement disponibles. « Notre plateforme va devenir multimodèle », confie Laurent Daudet. « Il sera possible d’avoir plusieurs modèles à la fois et de choisir en fonction des usages ».
Société fondée par des ingénieurs, LightOn explore par ailleurs des technologies en avance de phase, à l’instar des « architectures originales » comme Mamba.
MAMBA
MAMBA est un nouveau type d’architecture qui permet de faire du continuous pre-training, « c’est-à-dire que le modèle peut continuer à être entraîné aussi longtemps qu’on lui rajoute des données », explique Laurent Daudet.
Dans un LLM « classique », il faut prévoir le corpus d’apprentissage. « On ne peut pas partir sur 3 TeraToken d’entraînement et décider d’en rajouter un de plus après ».
Avec l’architecture MAMBA, cette limitation saute.
Un éditeur qui grossit
LightOn emploie aujourd’hui une quarantaine de personnes. Son équipe R&D est composée d’une dizaine d’ingénieurs, à laquelle s’ajoute une dizaine de « software developers ». La R&D est chargée des nouveaux modèles, du fine tuning et des nouvelles architectures. Les développeurs, eux, pensent l’interface et les fonctionnalités de la plateforme.
Le reste de l’équipe se répartit entre commerciaux, software architect, support clients et administratifs.
Signe de la bonne réception de l’offre de LightOn par le marché, l’éditeur a presque doublé de taille en un an. Et, à part pour quelques fonctions spécifiques (« trouver un très bon DevOps est compliqué », confirme Laurent Daudet), LightOn n’a pas de problème à embaucher… aussi parce que sa stratégie RH est internationale. Ses équipes regroupent aujourd’hui pas moins de 10 nationalités différentes.
Stratégie internationale aussi pour les ventes. LightOn a aussi des clients hors de France, notamment aux États-Unis (cf. encadré « LLM ad hoc ») ou aux Émirats arabes unis.
Résultat, après 8 ans d’existence et d’investissements, LightOn a été profitable pour la première fois en 2013. Et 2024 s’annonce – dixit son président – comme une année de forte croissance.
LightOn fait (encore) des LLMs ad hoc
LightOn est lauréat d’un appel d’offres « Commun Numérique » de la BPI. Dans ce cadre, il va concevoir un modèle (LLM) « from scratch » en s’appuyant sur la puissance de calcul de Jean Zay.
Le LLM sera ensuite versé à l’open source.
« Nous avons envie de garder cette compétence de faire des modèles », justifie Laurent Daudet. « Je pense que cela fait partie de notre valeur ajoutée aussi, de faire des modèles particuliers pour certains clients ».
C’est d’ailleurs cette compétence qui a été sélectionnée par un grand client américain dans la santé qui souhaitait « son » LLM.
Pour approfondir sur IA appliquée, GenAI, IA infusée


 Laurent Daudet, DG de LightOn -
Laurent Daudet, DG de LightOn -