LLM Mesh : Dataiku prône une approche agnostique de l’IA générative
Dataiku entend prendre en charge les modèles d’IA générative comme il s’occupe des pipelines de traitement de données, de manière centralisée, mais agnostique des services sous-jacents. Une approche qui nécessite tout de même de signer de nombreux partenariats.
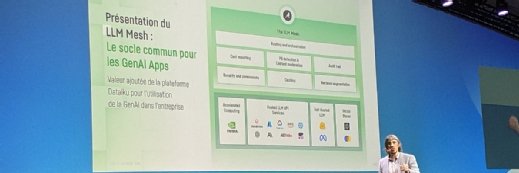
L’éditeur d’origine française a profité de son événement parisien Everyday AI Paris pour présenter LLM Mesh. Cette architecture dévoilée à la fin du mois de septembre doit devenir la « colonne vertébrale commune » des applications d’IA générative.
« La hype qui s’est emparée du monde autour de l’IA générative est énorme, mais elle laisse la place à énormément d’incertitude », affirme Clément Stenac, cofondateur et CTO de Dataiku. « Comment démarrer ? Comment accélérer ? Comment ne pas se perdre dans ses projets relatifs à la Gen AI ? ». Voici les questions auxquelles souhaite répondre l’éditeur.
Disponible en préversion publique dans DSS 12, LLM Mesh doit permettre de se connecter aux API des grands modèles de langage (OpenAI, Snowflake, Azure OpenAI Service, Google Vertex AI, Anthropic, Cohere, AI21 Labs, Amazon Bedrock et MosaicML) et d’en héberger d’autres depuis HuggingFace. En marge de sa conférence, Dataiku a présenté un partenariat avec Databricks en vue de renforcer les intégrations entre le Lakehouse et la plateforme de data science pour prendre en charge l’IA générative, entre autres. Au lancement de LLM Mesh, Dataiku s’était entouré de Pinecone, AI21 Labs et Snowflake.
Les connexions avec Amazon Bedrock et MosaicML ainsi que la fonction d’hébergement local ne sont pas encore disponibles dans Dataiku Cloud, mais l’éditeur entend accueillir les modèles Llama 2, Falcon, Dolly 2, MPT et d’autres.
Adapter les fonctions de DSS à l’IA générative
Outre l’accès à une multiplicité de LLMs, Dataiku défend l’intérêt d’une centralisation de la gouvernance.
Traçabilité de l’audit, gestion des coûts, identification des données personnelles, modération des contenus, détection des biais, gestion des rôles… Aux yeux de l’éditeur, les entreprises doivent traiter les modèles d’IA comme leurs données. Ce sont en tout cas des fonctions prévues sur sa feuille de route.
Techniquement, LLM Mesh se connecte aux bases de données vectorielles Pinecone, FAISS, et ChromaDB. Cela doit permettre la prise en charge des applications RAG (Retrieval Augmented Generation). Pour l’heure, l’utilisation des embeddings n’est compatible qu’avec les services d’OpenAI et d’Azure.
« C’est un monde qui évolue à toute vitesse. Nous ne sommes pas là pour vous annoncer que nous développons notre propre LLM ou notre propre base de données vectorielles », avance Clément Stenac. « Nous sommes là pour que vous puissiez exploiter les technologies de façon sûre, avec l’ensemble des capacités qu’une entreprise est en droit d’attendre ».
Dataiku a conçu Prompt Studio, un environnement dédié aux prompt engineers. « Dans le Prompt Studio, vous pouvez tester et expérimenter vos prompts, les comparer, confronter différents LLM et, lorsque vous êtes satisfait, déployer vos prompts en tant que Prompt Recipes pour la génération de lots à grande échelle », indique la documentation de l’éditeur.
Il propose également deux recettes consacrées à la classification et à la production de résumés textuels.
« Vous pouvez utiliser ces capacités sans aucun code, depuis l’interface utilisateur de Dataiku ou en code complet, via des API que nous mettons à disposition », précise le CTO.
Le service s’appuie évidemment sur des instances Nvidia, pour l’instant essentielles à l’exécution de ces charges de travail. Dans ce but, il convient de déployer un cluster Kubernetes Elastic AI (fourni par Dataiku) sur des instances de calcul compatibles et les bons drivers (cela réclame d’installer une image Almalinux 8 et Python 3.9). L’éditeur recommande une instance dotée d’un GPU Nvidia A10 avec 40 Go de VRAM afin de lancer un modèle de 7 milliards de paramètres (par exemple, Falcon-7B ou LLama 2-7B).
Oui, mais pour quels cas d’usage ? « Depuis le début de l’année, trois grandes tendances, trois grandes typologies d’application se dégagent quand l’on parle d’IA générative », indique Clément Stenac.
Le premier cas d’usage consiste à « remplacer des pipelines NLP existants pour transformer des données non structurées en données structurées, en bénéficiant de la qualité et de l’adaptabilité supérieures de l’IA générative ».
Deuxièmement, selon le CTO, cela peut servir à convertir des résultats d’une analyse, « prédictive ou non » en contenus sur mesure. Troisièmement, il s’agit « d’adapter des bases de connaissances internes en source de confiance accessibles par tous les collaborateurs » à travers le modèle d’architecture RAG.
Il est « trop tôt » pour subir un enfermement propriétaire, selon Dataiku
Snowflake, Databricks, Microsoft, AWS et GCP ont le même objectif avec leurs plateformes d’IA générative. Pourquoi les entreprises se tourneraient-elles vers LLM Mesh ? Dataiku défend le fait que la fonction soit intégrée sans coût supplémentaire de licence dans sa plateforme « cloud native et agnostique ».
« Il est trop tôt pour verrouiller des choix fortement engageants sur ce type de technologie ».
Clément StenacCTO, cofondateur, Dataiku
« [DSS] vous permet de garder le contrôle et le choix entre différents fournisseurs, qu’ils proposent des technologies cloud, des capacités de calcul, des bases de données, mais aussi d’IA générative », affirme Clément Stenac.
Ainsi, Dataiku mise en premier lieu sur une fonction de routage et d’orchestration entre les modèles. « Il est trop tôt pour verrouiller des choix fortement engageants sur ce type de technologie », insiste le CTO.
En clair, il s’agit de convaincre les organisations qui font déjà confiance à Dataiku pour leurs charges de travail analytiques et de machine learning. Celles-là, à l’instar de LVMH, de Michelin, de la Société Générale ou de Sanofi exploitent la plateforme de Data science pour déployer des cas d’usage sur différentes infrastructures (cloud ou non) et dans différentes entités. Ces trois-là ont ajouté l’IA générative à leur feuille de route ou ont prévu de le faire.
Pour approfondir sur Intelligence Artificielle et Data Science