Data Fabric, Process Mining, IA générative : les plans d’Appian pour 2024
Lors d’Appian Europe à Londres, l’éditeur a présenté la version 23.4 de sa plateforme low-code. L’occasion de détailler son approche en matière d’IA générative qu’il compte réellement mettre en œuvre l’année prochaine.
En amont de son événement européen se déroulant à Londres le 15 novembre, le spécialiste américain du Low-code a annoncé la disponibilité de sa mise à jour majeure 23.4, la dernière de cette année.
Appian s’occupe principalement d’enrichir sa Data Fabric et de refondre les outils de process mining qu’il a acquis auprès de Lana Labs.
Outre la possibilité de lire des données depuis des systèmes sources, cette couche de virtualisation permet de synchroniser des enregistrements entre ces sources et des tables exploitées par les applications Appian. Jusqu’alors, Data Fabric autorisait la lecture et l’écriture de données dans des SI disparates. Désormais, il est possible d’effacer les données des systèmes sources et cibles.
Cette couche virtuelle doit accélérer la conception des applications. « Les développeurs peuvent réutiliser les données qui se trouvent dans le tissu de données comme si elles étaient dans une même base de données », assure Annelise Dubrovsky, VP of Product Management, chez Appian. « Les connecteurs demeurent pour maintenir la synchronisation entre les SGBD sources et les applications ».
Selon l’éditeur, 66 % des sites existants et 93 % des nouveaux sites (applications Web) en production s’appuient sur cette architecture. Le niveau d’adoption est toutefois à nuancer. Il se peut qu’une entreprise utilise Data Fabric pour simplifier l’accès à des données situées dans des tables différentes d’une même base de données, d’après Annelise Dubrovsky. Aussi, les applications ne peuvent contenir qu’un nombre de lignes fixe. En conséquence, Appian entend revoir son architecture pour surmonter cette limite.
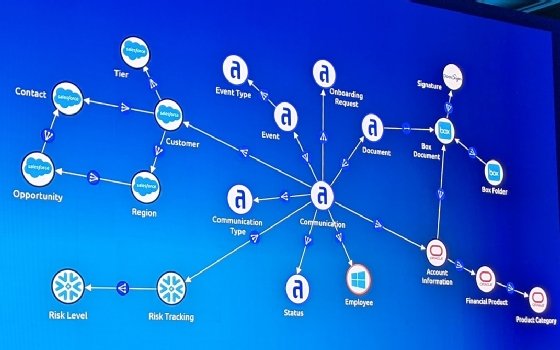
Un exemple de la mise en pratique de la couche de virtualisation de Data Fabric dans une application Appian.
Process HQ : la refonte des produits de Lana Labs touche à son terme
Côté process mining, l’entreprise est revenue sur le développement en cours de Process HQ, dont la disponibilité est prévue l’année prochaine. La suite doit simplifier l’accès aux sources de données, automatiser la préparation, inclure une interface pour développer un modèle BPMN, effectuer l’analyse des processus, distinguer les goulets d’étranglement et suivre les évolutions et les dérives « en continu ». Ici, l’éditeur entend s’appuyer sur le Data Fabric pour simplifier le formatage de données, puis proposer des actions pour les préparer avant de les analyser.
« Process HQ fournira automatiquement une vue d’ensemble du processus afin que vous puissiez accéder facilement à des informations de haut niveau sur vos données de processus, avec des graphiques montrant les distributions et les tendances au fil du temps, mais aussi d’autres indicateurs plus détaillés », avance Karina Buschieweke, directrice stratégie produit chez Appian et cofondatrice de Lana Labs. « Process HQ proposera automatiquement trois à cinq recommandations suivant vos objectifs à moindre effort et sans besoin de faire appel à des experts pour examiner les processus », ajoute-t-elle.
Une couche d’analytique en libre-service pour Data Fabric
Les ajouts les plus notables de cette version sont encore en préversion. Ainsi, l’éditeur développe une fonctionnalité d’analytique en libre-service spécifique au Data Fabric. Celle-ci doit permettre de réutiliser les données des applications, potentiellement en provenance de plusieurs sources (ERP, CRM, HCM, etc.) afin de les analyser dans un contexte applicatif.
Les jeux de données correspondants sont réutilisables depuis un data catalog interne à la plateforme. Il est possible de gérer les accès aux données suivant les rôles désignés. Cette « protection » peut être appliquée au niveau d’une ligne. Mais surtout, Appian propose un outil interne pour créer des visualisations et des rapports concernant ces données.
Les entreprises ont déjà de nombreux outils de BI à leur disposition. Pourquoi utiliseraient-elles ceux d’Appian ? « L’avantage, c’est que ces analyses sont intégrées », défendent les porte-parole.
Ces analyses peuvent être expliquées par AI Copilot, le système d’IA générative infusé par Appian. L’éditeur ouvre une partie des capacités de ce système à ses clients. C’est le rôle du composant Records Chat, qui permet d’utiliser les enregistrements employés dans les applications Appian pour contextualiser les réponses d’un agent conversationnel interne, par exemple pour mieux gérer les cas BPM, mais aussi externe.
Il exploite également le NLP pour automatiser la traduction des applications en plusieurs langues dans son segment Total Experience.
Par ailleurs, il se prépare à lancer un nouvel « AI Skill », plus spécifiquement une capacité d’Intelligent Data Processing. L’outil doit améliorer la précision du texte extrait de documents PDF. Les utilisateurs peuvent entraîner un modèle de machine learning personnalisé avec quelques exemples de documents à traiter.
« Par exemple, vous pouvez étiqueter des blocs d’adresses ou des noms de fournisseurs et Appian extraira ces champs, même si les étiquettes “Adresse du fournisseur” ou “Nom du fournisseur” n’apparaissent pas dans le document », illustre la documentation.
Deux autres AI Skill sont en cours de développement. Le premier doit permettre de créer une application de type formulaire à partir d’un PDF. Appian s’appuie à la fois sur les capacités OCR de sa plateforme et un modèle OpenAI, ainsi que des capacités prédictives et prescriptives pour produire le code et les objets Appian correspondants.
Le second vise à donner une interface de prompt engineering aux utilisateurs pour personnaliser le développement d’applications propulsées par un grand modèle de langage.
Private AI : contenir les modèles dans un périmètre de sécurité maîtrisé par l’entreprise
Malgré ces annonces, Appian se veut prudent concernant l’IA générative. Matt Calkins, PDG de l’entreprise, insiste sur la notion de « Private AI », sur le fait que l’IA doit compléter la combinaison des processus et des données, mais que ni Appian ni ses partenaires ne doivent pouvoir accéder aux données des entreprises. Il faut toutefois préciser ce qu’entend Appian par ce terme. Cette IA devrait résider dans l’environnement logique de l’entreprise, ici, la plateforme Appian Cloud et son socle, AWS. « Les données ne quittent jamais le périmètre de sécurité logique », insiste Adam Glaser, SVP, Product Management, chez Appian.
Records Chat s’appuie sur un modèle de fondation proposé par AWS dans sa plateforme Amazon Bedrock. C’est pour l’instant la seule fonctionnalité de l’éditeur qui s’appuie sur cette plateforme, mais l’éditeur se prépare à étendre ce dispositif.
« Nous sommes en train d’intégrer les LLM de Bedrock dans l’architecture d’Appian. Ceux-ci résideront derrière notre pare-feu, afin de garantir que les données ne quittent jamais cet environnement ».
Malcom RossSVP Product Strategy, Appian
« Nous sommes en train d’intégrer les LLM de Bedrock dans l’architecture d’Appian. Ceux-ci résideront derrière notre pare-feu, afin de garantir que les données ne quittent jamais cet environnement », précise Malcom Ross, SVP Product Strategy chez Appian. « Les données [des clients] ne sont jamais utilisées pour entraîner les modèles ».
Malcom Ross explique ce choix par le fait qu’OpenAI et Microsoft ne proposent pour l’instant que la certification SOC 2, en sus d’engagements sur le respect des réglementations CCPA et RPGD. Bedrock est compatible avec le RGPD et respecte la réglementation HIPAA. AWS a passé une évaluation 3PAO auprès d’un auditeur tiers afin d’indiquer aux autorités américaines que le service respecte les exigences de la norme FedRAMP. AWS n’a pas encore obtenu l’autorisation, mais elle sera précieuse pour Appian. Sa plateforme est exploitée par les administrations et le secteur de la Défense aux États-Unis.
L’éditeur n’a pas expliqué s’il souhaitait (ou comment) apporter ces fonctionnalités sur site.
Le prompt engineering, un gage de confidentialité selon Appian
De manière générale, Appian ne recommande pas de réentraîner les grands modèles de langage (LLM) avec des données clients. « Quand vous entraînez un grand modèle de langage sur un jeu de données, il en conserve la connaissance. Nous ne savons pas encore comme lui faire oublier une information », indique Malcom Ross.
Néanmoins, Appian est amené à fine-tuner les modèles pour accomplir des tâches spécifiques et tenter de filtrer les éléments non essentiels pour ses usages.
La mise en contexte à travers la méthode RAG (Retrieval Augmented Generation) est une fonctionnalité clé qu’il faut encore développer. Pour le compte de son client DAS, une société de protection juridique hollandaise, Appian intègre sa plateforme avec la base de données vectorielle Pinecone. Elle cherche à automatiser et assister le traitement de quelque 125 000 cas et 7 millions de documents légaux par an.
« Pinecone est utilisé par DAS pour vectoriser et pour fournir une couche sémantique par-dessus son jeu de données afin de le rendre plus interprétable par un LLM », explique Malcom Ross. « Nous sommes également en train d’envisager l’intégration avec les solutions d’Elastic qui mêle recherche vectorielle et par mots clés », raconte le responsable.
Selon Malcom Ross, Appian aura la tâche d’intégrer une couche sémantique dans sa plateforme et d’en simplifier l’accès à des développeurs low-code/no-code. « Manipuler une base de données vectorielle n’est pas à la portée de tous. Nous n’avons pas encore décidé si cette couche s’appuiera sur Pinecone, Elastic ou autres, mais l’objectif est de la rendre très accessible à nos usagers », déclare-t-il.
Pour l’instant, Appian mise sur le prompt engineering et le prompt tuning. Ces techniques sont à la fois les moins chères à exploiter et n’impliquent pas de rétention de données à long terme. Avec Records Chat, un prompt « caché » est utilisé sous le capot pour définir les interactions possibles avec les données contenues dans une application Appian. À titre de comparaison, GitHub a fait le même choix pour animer une fonction de détection de vulnérabilités dans CodeQL.
Les entreprises peuvent aussi, si elles le souhaitent, se connecter aux API d’OpenAI en mode « Bring Your Own AI ». C’est la méthode utilisée actuellement pour résumer les visualisations dans la fonction d’analytique en libre-service de Data Fabric.
« L’addition salée » de « la grande fête de l’IA »
Pour l’heure, la question de la tarification reste ouverte. Appian doit encore statuer sur une offre suffisamment intéressante pour lui et ses clients.
« Collectivement, c'est un peu comme si en 2023 nous avions eu la grande fête de l'IA et que maintenant, nous nous réveillions le lendemain avec la gueule de bois et que nous constations l'addition salée du restaurant ».
Malcom RossSVP Product Strategy, Appian
« C’est une autre raison pour laquelle nous n’offrons pas de réentraînement des modèles parce que c’est coûteux, cela nécessite du temps de GPU Nvidia sur les architectures en cloud et cela peut prendre un jour ou plus pour faire l’entraînement, en fonction de la taille du volume de données sur lequel vous vous entraînez », relate Malcom Ross.
« Collectivement, c’est un peu comme si en 2023 nous avions eu la grande fête de l’IA et que maintenant nous nous réveillions le lendemain avec la gueule de bois et que nous constations l’addition salée du restaurant », plaisante-t-il.
« Plus sérieusement, tout le monde se demande quelle est la valeur réelle [des capacités de l’IA générative] et comment, en tant qu’éditeur, nous pouvons créer des modèles de tarification qui sont acceptables pour nos clients ».