
alphaspirit - stock.adobe.com
Datadog veut appliquer l’observabilité de bout en bout à l’IA générative
Lors de sa conférence DASH au Moscone Center de San Francisco, le Franco-New-Yorkais Datadog s’est largement épanché sur la supervision des grands modèles de langage et des applications connexes. Les annonces sont principalement fondées sur la mise à jour de son agent et l’ajout de tableaux de bord préconfigurés.

L’éditeur avait déjà présenté en mai une solution pour contrôler l’usage, les performances et les coûts associés aux API d’OpenAI. Comme l’avait évoqué Yrieix Garnier, VP of Product chez Datadog au MagIT, l’éditeur étend ses capacités à différents modèles LLM disponibles sur le marché. Datadog annonce que sa plateforme permettra de surveiller les collections de modèles d’OpenAI, PaLM 2 de Google, Claude et Claude 2 d’Anthropic, Coral de Cohere, Amazon CodeWhisperer d’AWS, ainsi que ceux accessibles depuis les plateformes Azure Machine Learning, Vertex AI de GCP, Amazon Bedrock (qui prend en charge les modèles d’AI21 Labs et de Stability AI) et Huggingface.
Douze intégrations et des tableaux de bord

C’est la partie immergée de l’iceberg. Datadog évoque une supervision de bout en bout de la pile technologique nécessaire à l’entraînement et à l’inférence de ces grands modèles de langage (LLM).
Il entend assurer la surveillance des infrastructures, des bases de données vectorielles, des plateformes d’orchestration du déploiement et d’exécution des modèles, ainsi que des frameworks nécessaires à la conception d’applications d’IA générative.
Concrètement, Datadog propose douze nouvelles intégrations au sein de l’agent qui nourrit sa plateforme d’observabilité. En sus de collecter les logs, les métriques et les événements, l’éditeur construit des tableaux de bord préconfigurés pour afficher les informations essentielles.
Ainsi, dans la mise à jour 7.47 de son agent, l’éditeur prend en charge les métriques exposées par le module Prometheus nommé sobrement DCGM Exporter. Ce paquet se déploie dans un environnement Kubernetes via l’opérateur Nvidia GPU Operator. Celui-ci exploite la suite d’outils open source Nvidia Data Center GPU Manager (DCGM).
Températures (de la VRAM et du GPU lui-même), fréquence mémoire, vitesse du flux multi processeurs, énergie électrique consommée, erreurs mémoires, bandes passantes de la passerelle NVlink, vitesse des ventilateurs (bien que la plupart des GPU utilisés dans les data centers disposent d’un refroidissement liquide ou passif), pourcentage d’utilisation de la mémoire, identification des goulets d’étranglement… DCGM offre un large panel d’indicateurs pour suivre de près les performances des GPU Nvidia pour data center comme les produits A100, H100, L40, L4 ou encore K80.
Datadog dispose également d’une intégration spécifique au TPU de Google. Pour le suivi des performances des puces d’AWS, il convient d’installer l’agent sur les instances EC2, mais les logs collectés ne fournissent pas actuellement le niveau de détail offert par DCGM. L’éditeur ajoute qu’il peut monitorer les instances déployées sur les trois infrastructures cloud majeures (AWS, GCP et Azure).
Datadog L’éditeur annonce par ailleurs une intégration avec CoreWeave, un spécialiste de l’orchestration des charges de travail GPU qui installe – avec le soutien technique et financier de Nvidia – ses propres infrastructures cloud aux États-Unis. Comme c’est déjà le cas avec AWS, GCP et Azure, Datadog veut suivre les performances ainsi que mesurer la consommation et les dépenses liées aux instances CoreWeave.
La version 7.47 de l’agent prend également en charge des bases de données vectorielles, c’est-à-dire les SGBD qui accueillent et traitent les embeddings, des représentations vectorielles de phrases et de mots utilisés dans les prompts (les commandes ou requêtes) envoyés aux modèles d’IA générative. Datadog propose ainsi des intégrations et des tableaux de bord préconfigurés pour Weaviate, une base de données vectorielle open source, et Pinecone. Par effet de bord, Datadog mentionne l’intégration à l’orchestrateur de flux ELT/ETL Airbyte et rappelle que son agent est d’ores et déjà compatible avec Redis, dont le SGBD in-memory peut accueillir sans broncher des embeddings.
« Ces intégrations incluent les mesures standard des bases de données, telles que les temps de latence des requêtes, la vitesse d’importation et l’utilisation de la mémoire », explique Datadog dans un billet de blog. « Elles incluent également des mesures spécifiquement adaptées à la surveillance des bases de données vectorielles, notamment les opérations et les tailles d’index, ainsi que les durées des opérations par lots d’objets et de vecteurs ».
Airbyte est mentionné comme moyen de populer ces SGBD spécialisés. Les outils de Datadog serviraient à analyser les transferts de données afin d’éviter les « pertes de qualité de données ».
En sus de superviser les performances CPU, GPU et réseau, la latence et les erreurs des instances appelées par les plateformes Google Cloud Vertex AI et AWS Sagemaker, la version 7.47 de l’agent de Datadog extrait les logs et métriques en provenance de TorchServe, la bibliothèque de déploiement de modèles associée à PyTorch. L’intégration permet de suivre les événements de déploiement ou de dépréciation de modèles, le volume de requêtes envoyées à l’API TorchServe, les erreurs ou encore les versions des modèles ainsi que l’usage de la RAM et de la VRAM.
Enfin, l’agent de Datadog récupère les données en provenance des applications bâties à l’aide du framework LangChain. « Le tableau de bord Datadog LangChain permet de visualiser les taux d’erreur, le nombre de tokens, les temps de prédiction moyens et le nombre total de requêtes pour l’ensemble de modèles [déployés] », ajoute l’éditeur.
Si selon le dépôt Git de l’éditeur, il reste quelques défauts et bugs à corriger, la version 7.47 de l’agent Datadog est disponible depuis quatre jours sur la plateforme Docker Hub.
LLM Observability : Datadog se met au niveau des acteurs spécialisés
Lors de sa conférence annuelle, l’éditeur a présenté un autre service en cours de développement. Accessible en bêta privé, LLM Observability s’appuie sur les intégrations et les tableaux de bord présentés dans cet article afin d’unifier, puis pousser l’observabilité de la pile technologique et des modèles d’IA générative un cran plus loin.
En sus d’inventorier les LLM exploités en production, ce service doit faciliter l’examen des prompts envoyés aux modèles et des réponses obtenues afin de détecter les hallucinations, et identifier les dérives potentiellement dues aux mises à jour d’un modèle ou des requêtes qui lui sont envoyées. Il s’agit aussi de superviser les feed-back effectués par les utilisateurs d’une application propulsée par un LLM.
Ces retours doivent faciliter la détection de problèmes de performance comme l’indisponibilité d’une API, mais également servir à affiner les résultats d’un modèle ou à le réentraîner.
« Les performances des modèles se dégradent au fil du temps », prévient Junaid Ahmed, VP, engineering observability, chez Datadog, lors de la conférence DASH. Le responsable peut en témoigner : il a dirigé plusieurs projets liés à l’exploitation de moteurs de recherche et du NLP pour le compte d’Apple et de Microsoft. « Les données du monde réel ne correspondent pas forcément aux données d’entraînement. Et, en raison de la complexité des réseaux de neurones, le débogage prend souvent l’allure d’un jeu de la taupe », ajoute-t-il.
LLM Observability est pensé pour aider les équipes à s’attaquer à ces problèmes. Par exemple, un prompt peut s’avérer trop long ou complexe pour qu’il soit correctement interprété par le modèle. De plus, la mesure du nombre de tokens (nombre de caractères dans une requête et dans une réponse) a son importance : c’est ce qui détermine le coût d’utilisation d’un tel service.
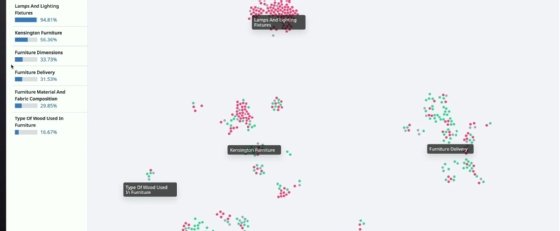
Par ailleurs, LLM Observability dispose d’un tableau de bord représentant un nuage de points pour classer les prompts et leurs résultats par sujet au fil du temps. Il s’agit d’identifier les thématiques les plus populaires et ceux où le modèle génère le plus de bonnes ou de mauvaises réponses.
Si pratiquement toutes les plateformes d’observabilité, y compris les outils open source, sont capables de traiter les données en provenance des applications et des modèles d’IA, avec LLM Observability, Datadog tente de se mettre au niveau d’acteurs spécialisés tels Honeycomb et Weight and Biases.
C’est le bon moment pour Datadog : les entreprises multiplient les expérimentations et les cas d’usage, soit par leurs propres moyens, soit avec le soutien d’ESN, comme Capgemini ou SFEIR. Mais ce type de solution semble davantage orienté pour les usages massifs de l’IA générative que l’on observe aujourd’hui chez les géants du Web, dont Microsoft et Google.
De plus, c’est aux développeurs, aux data scientists et aux data engineers de décider si ce type de traceurs leur sont utiles. Si Datadog articule sur le papier l’observabilité de bout en bout des stacks LLM, les ingénieurs doivent tout de même assurer leur instrumentation.
Pour approfondir sur Intelligence Artificielle et Data Science
-
![]()
AgenticOps et SOC agentique, les concepts inédits de Splunk
Par: Yann Serra
-
![]()
Avec AgentCore, AWS s’équipe pour la mise en production de l’IA agentique
Par: Esther Shittu
-
![]()
IA agentique : Datadog jauge l’intérêt des clients
Par: Gaétan Raoul
-
![]()
Le ministère des Armées déclare la guerre au « Shadow AI »
Par: Christophe Auffray



