DBaaS : Google gonfle les capacités de Cloud Bigtable
La montée à l’échelle automatique est un thème clé de la dernière série de mises à jour que Google apporte à son service de base de données NoSQL managé dans le cloud. À la clé, une limite de stockage doublée et la promesse d’une réduction des coûts.
Google a annoncé à la fin du mois de janvier une série de mises à jour en disponibilité générale pour son service de base de données Cloud Bigtable.
Google Cloud Bigtable est un service de base de données NoSQL managé qui peut gérer des charges de travail analytiques et opérationnelles. Parmi les nouvelles mises à jour apportées à Bigtable, citons une capacité de stockage accrue : jusqu’à 5 To de stockage SSD sont désormais accessibles par nœud, soit le double par rapport à la limite précédente de 2,5 To. L’entreposage de données sur HDD est restreint à 16 To par nœud, contre 8 auparavant.
À titre de comparaison, Atlas, la DBaaS de MongoDB peut accueillir 4 To de stockage physique par cluster, mais le sharding permet de dépasser largement ce seuil pour emmagasiner plusieurs dizaines de téraoctets par cluster.
DocumentDB d’AWS dispose d’un quota de 64 To de stockage par cluster. Bigtable réclame a contrario de déployer le stockage par nœud pour obtenir des facultés similaires. Rappelons que 5 To de stockage SSD ou 16 To de stockage HDD sont des capacités maximales. « Une bonne pratique consiste à ajouter suffisamment de nœuds à votre cluster, afin de n’utiliser que 70 % de ces limites », recommande la documentation de Google Cloud Platform (GCP).
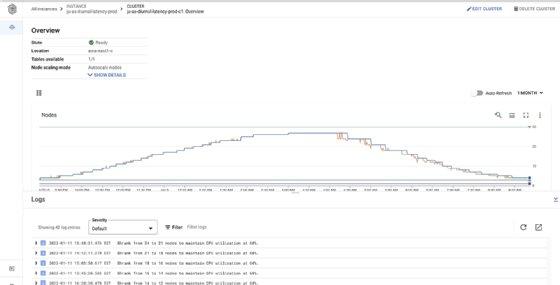
GCP offre également des capacités de mise à l’échelle automatique améliorées, de sorte qu’un cluster du SGBD NoSQL accroît ou diminue ses capacités de calcul et de stockage sans intervention humaine, en fonction de la demande. La mise à jour de Bigtable est complétée par une meilleure visibilité des charges de travail de la base de données, afin de cerner plus rapidement les causes profondes d’un problème.
« Les nouvelles fonctionnalités annoncées dans Bigtable témoignent de l’attention continue portée à l’automatisation et la montée à l’échelle, qui deviennent les principaux enjeux pour les services de cloud modernes. »
Adam RonthalAnalyste, Gartner
« Les nouvelles fonctionnalités annoncées dans Bigtable témoignent de l’attention continue portée à l’automatisation et la montée à l’échelle, qui deviennent les principaux enjeux pour les services de cloud modernes », déclare Adam Ronthal, analyste chez Gartner. « Elles favorisent également l’amélioration du rapport prix/performance – la mesure clé pour évaluer et gérer tout service de cloud – et l’observabilité, qui sert de base à une meilleure gouvernance et à une meilleure optimisation financière. »
Cloud Bigtable : un autoscaling natif, revu et corrigé
L’une des promesses du cloud est depuis longtemps la possibilité de faire évoluer les ressources de manière élastique en fonction des besoins, sans nécessiter de nouvelles infrastructures physiques pour les utilisateurs finaux.
La mise à l’échelle programmatique a toujours été disponible dans Bigtable, selon Anton Gething, chef de produit Bigtable chez Google. Il ajoute que de nombreux clients de Google ont développé leurs propres approches de mise à l’échelle automatique pour Bigtable par le biais d’APIs. Spotify, par exemple, a mis à disposition une implémentation open source de Cloud Bigtable autoscaling.
« La dernière version en date de Bigtable introduit une solution native de mise à l’échelle automatique », précise Anton Gething.
Il ajoute que l’autoscaling natif surveille directement les serveurs Bigtable, afin d’être très réactif. En conséquence, la taille d’un déploiement Bigtable peut évoluer en fonction de la demande.
Selon Anton Gething, les utilisateurs n’ont pas à mettre à jour leur déploiement existant pour bénéficier de la capacité de stockage accrue. Il précise que Bigtable sépare le calcul et le stockage, ce qui permet à chaque type de ressource d’évoluer indépendamment.
« Cette mise à jour de la capacité de stockage vise à optimiser les coûts, pour les charges de travail axées sur le stockage et qui nécessitent davantage de ressources, sans qu’il soit nécessaire d’augmenter la capacité de calcul », assure Anton Gething.
« Dans l’une de nos expériences, la mise à l’échelle automatique a réduit les coûts d’une charge de travail diurne commune de plus de 40 % », vantent les porte-parole de GCP dans un billet de blog.
« Vous aurez besoin de deux informations : une utilisation cible du CPU et une fourchette dans laquelle maintenir votre nombre de nœuds. Aucun calcul, aucune programmation, ni aucune maintenance complexe ne sont nécessaires », ajoutent-ils.
Deux contraintes sont à prendre en compte selon eux. Le nombre maximal de nœuds ne peut pas être 10 fois supérieur au nombre minimal de nœuds et il n’est pas possible de configurer l’utilisation des espaces de stockage, l’autoscaling s’en charge automatiquement.
Google Cloud opte pour un autoscaling natif dédié à Bigtable et davantage de métriques pour surveiller les charges de travail.
Optimisation des workloads et observabilité
Une autre nouvelle capacité atterrit dans Bigtable : elle est connue sous le nom de routage de groupes de clusters.
Anton Gething explique que dans une instance répliquée de Google Cloud Bigtable, les groupes de clusters permettent un contrôle plus fin des déploiements à haute disponibilité et une meilleure gestion des charges de travail. Avant la nouvelle mise à jour, il a noté qu’un usager d’une instance Bigtable répliquée pouvait acheminer le trafic vers l’un de ses clusters Bigtable dans un mode de routage de cluster unique, ou vers tous ses clusters dans un mode de routage multiclusters. Le responsable indique que les groupes de clusters permettent désormais aux clients de router le trafic vers un sous-ensemble de leurs clusters.
Google a également ajouté une métrique spécifique à l’utilisation du processeur par profil d’application. Elle offre une meilleure visibilité sur les performances d’une charge de travail applicative donnée. Bien que Google ait fourni une certaine visibilité de l’usage du CPU aux administrateurs de Bigtable avant cette mise à jour, Anton Gething explique que GCP propose de nouvelles dimensions de visibilité sur les méthodes d’accès aux requêtes de données et aux tables elles-mêmes.
« Sans ces dimensions supplémentaires, le dépannage pouvait être difficile », reconnaît M. Gething. « Vous aviez la visibilité de l’utilisation du CPU du cluster, mais vous ne pouviez pas savoir quel profil d’application exploitait le CPU, ou quelle application accédait à quelle table et avec quelle méthode. »