Dataiku : le Machine Learning « transparent » au cœur de DSS 6
En réponse aux boites noires de l'IA, la version 6 de Data Sciences Studio s'enrichit d'outils pour décortiquer les résultats des algorithmes et contrer les biais. Autre nouveauté: les déploiements cloud mis dans les mains des métiers.

L'éditeur français de préparation des données (Data Prep), d'automatisation du Machine Learning et de pipeline analytique sort en cette fin 2019 le sixième millésime de son outil, Data Sciences Studio (alias DSS).
« Il y a deux thèmes très importants dans DSS 6 », explique au MagIT Jérémy Greze, Product Manager.
Le premier est « l'Intelligence Artificielle transparente, ou Whitebox ML [N.D.R. : autre nom du concept d'XAI], pour que les Data Scientists aient confiance dans les modèles ».
Le deuxième est le concept « d'élasticité » - c'est à dire la possibilité pour les utilisateurs finaux de DSS de faire appel à des ressources cloud temporaires pour exécuter leurs tâches, et ce sans forcément passer par l'IT.
White Box ML
La capacité d'auditer les résultats issus d'algorithmes pour les rendre explicables est d'autant plus critique que des outils comme Dataiku (ou son grand concurrent américain Alteryx) introduisent de plus en plus d'automatisation. En clair : « le modèle d'IA est en grande partie construit, tout seul, par le logiciel », confirme Jérémy Greze. « Du coup, si un Data Scientist en crée un autre manuellement, il veut comprendre ce qui fait que l'un est meilleur que l'autre ».
Autre cas, un utilisateur métier, qui ne met pas du tout les mains dans les algorithmes, doit pouvoir s'assurer que son travail ne comporte pas de biais.
D'une manière plus large, « l'explicabilité » est de plus en plus importante pour le grand public. « Nous sommes tous confrontés à des décisions automatisées - ouverture de compte en banque, demande de crédit, etc. - il faut donc pouvoir comprendre et expliquer les paramètres de ces décisions », avertit à juste titre le responsable produit. Dans le cas contraire, la défiance vis à vis des boites noires du Deep Learning - tant soulignées par la presse grand public - pourrait déteindre sur le ML et refroidir les velléités d'analytique avancé des métiers.
Partial Dependancy Plot et analyse par sous-populations
Dataiku a bien compris qu'il y avait là un frein qu'il fallait déverrouiller. Pour le faire, DSS 6 introduit concrètement deux fonctionnalités.
La première se nomme Partial Dependancy Plot. Elle permet de visualiser l'influence d'une variable sur le résultat d'un modèle. Par exemple, dans un modèle prédictif de santé, l'influence de l'âge est-elle linéaire ou la corrélation est-elle exponentielle ?
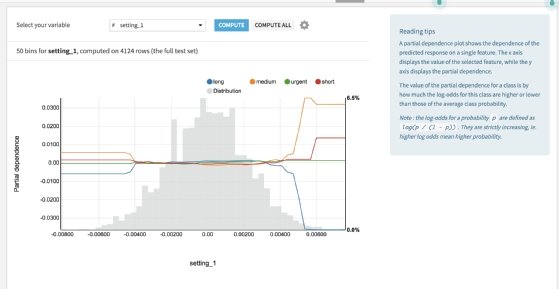
Le Partial Dependancy Plot représente graphiquement cette influence avec la variable étudiée en abscisses, avec le delta de probabilité sur les ordonnées, et avec la densité représentée en arrière plan (beaucoup de personnes d'une classe d'âge ou pas). « Nous avions déjà un peu [ce type d'outil dans DSS], mais c'était beaucoup moins facilement utilisable », souligne Jérémy Greze.
La deuxième nouveauté de DSS 6 dans le domaine concerne l'analyse par sous-population (sub-population).
Ce type d'analyse, elle aussi graphique, permet de voir si un modèle est biaisé et s'il « discrimine » une catégorie (la sous-population en question) en comparant simultanément les résultats du modèle entre les différentes sous-populations.
DSS permet de définir en amont les catégories que l'on souhaite observer : hommes vs femmes, par classe d'âges, par tranche de revenus, etc.
« A la différence du Partial Dependancy Plot, on étudie ici le modèle dans sa globalité, pas juste pour une variable », précise le responsable de DSS. « Si un modèle score et accepte 20 % des demandes de crédits, on pourra voir s'il y a un biais homme/femme en comparant les résultats [de cette segmentation du jeu de données]. S'il y a 30 % d'accords pour les hommes et 10 % pour les femmes, l'analyse par sous-population montrera rapidement le biais. Ou à l'inverse, elle montrera peut-être que c'est bien 20 % pour tout le monde ».
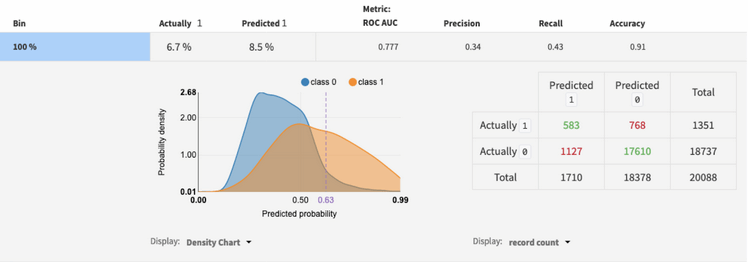 Analyse par sous-populations dans Data Science Studio 6 de Dataiku
Analyse par sous-populations dans Data Science Studio 6 de Dataiku
« Élasticité »
L'autre « grosse » nouveauté de DSS 6 concerne l'élasticité. « L'élasticité c'est pouvoir envoyer le travail ou l'apprentissage du modèle chez le fournisseur de cloud de votre choix », explicite Jérémy Greze. « C'est élastique dans le sens où la capacité s'adapte au volume [des données et au compute nécessaire]. »
« Là encore, c'était déjà possible ; mais nous allons un pas plus loin avec DSS 6. La vraie nouveauté, c'est que nous facilitons tout cela. Jusqu'ici, déployer Spark sur Kubernetes devait passer par un administrateur système qui devait tout configurer. Aujourd'hui, un utilisateur va pouvoir démarrer un cluster tout seul. S'il a un gros travail de processing à venir, il va pouvoir - depuis l'interface de DSS6 - démarrer son cluster, et à la fin de la journée le fermer et déprovisionner ».
Le but est d'accélérer les projets mais absolument pas de court-circuiter l'IT. Les administrateurs peuvent en amont « isoler et gérer la puissance de calcul afin que chaque équipe bénéficie exactement de ce dont elle a besoin », souligne bien le communiqué officiel du lancement de DSS 6.
Sur l'IA et le ML explicables :
Explicabilité des IA : quelles solutions mettre en œuvre ?
S’il est communément accepté que les algorithmes de type Machine Learning/Deep Learning fonctionnent comme des boîtes noires, la recherche avance quant à l’explicabilité des résultats délivrés par les IA.
IBM veut industrialiser la détection des défauts de l’AI
Ce service se repose sur une série d’algorithmes open source qui identifie et score les biais des modèles d’intelligence artificielle et permet de les corriger.
Eminence mise sur la transparence des algorithmes
La marque de sous-vêtements masculins s'est tournée vers le Français Twin Solutions pour se doter d'une plateforme de prévision des ventes. Avec une particularité : les prévisions délivrées par les algorithmes sont explicables et transparentes.




