
alphaspirit - Fotolia
BI : que mijote la R&D de Qlik pour ses clients ?
Elif Tutuk, la chef de Qlik Research, explicite dans un entretien les projets sur lesquels son équipe travaille pour améliorer l'expérience de ses utilisateurs : un moteur associatif plus intelligent, des visualisations multi-attributs et le NLP.

Elif Tutuk, directrice de Qlik Research, a détaillé pour nous les nouveaux projets technologiques que son équipe est en train d'incuber pour les futurs produits de Qlik.
Son groupe de recherche est responsable d'un certain nombre de fonctionnalités qui sont aujourd'hui intégrées dans les produits, comme le moteur cognitif Qlik Cognitive Engine - un framework IA - ou le Associative Big Data Indexing.
Elif Tutuk explique également comment elle continue à travailler sur le concept à la base de son AI Associative Engine pour l'appliquer à ce qu'elle appelle les « livewired data » - des données reliées automatiquement via des connexions entre elles qui ne s'appuient pas sur des paramètres définis par le développeur.
Elle nous dévoile également les projets de Qlik en cours de développement, tels qu'une capacité d'analyse visuelle multi-attributs (Data Swarm), l'intégration du traitement du langage naturel (NLP) et de la reconnaissance vocale dans la visualisation.
Qlik espère que ces chantiers l'aideront à se différencier de ses concurrents, au premier rang desquels Tableau, Tibco ou MicroStrategy.
« Livewired data » et « Data Swarm »
LeMagIT : Pouvez-vous expliciter votre concept de « livewired data » ? Et son lien avec le moteur associatif de Qlik ?
Elif Tutuk : Ce qui est unique avec le moteur [AI de Qlik], c'est qu'il peut associer les valeurs des données entre elles automatiquement. Nous exécutons des algorithmes sur les données qui examinent leurs valeurs pour déterminer les connexions possibles.
Le premier avantage d'un « moteur associatif », c'est que les données se définissent d'elles-mêmes, par opposition à une approche relationnelle où un humain doit définir les liens entre les données à partir de questions pré-établies.
De ce point de vue, j'utilise la terminologie « livewired » (NDR : qui se traduit littéralement par « câblage vivant ») dans le sens où la technologie crée elle-même des liens dynamiques, par opposition à une approche relationnelle, que je qualifie de « hard wired » dans le sens où les liens (ou les relations) sont déterminés en dur par des développeurs. L'intérêt est que les utilisateurs qui posent des questions n'ont pas besoin de suivre un chemin prédéfini pour être en mesure d'explorer (drill down) les données.
Avec notre moteur associatif, nous analysons l'ensemble des données, ce qui est très différent d'un outil relationnel à base de requêtes. Dans ce deuxième cas de figure, lorsque vous posez une question, vous avez déjà filtré les données, de sorte que l'IA ne s'intéresse qu'à cette partie des données.
Chez Qlik, nous utilisons la question comme un moyen pour la machine de comprendre vos intérêts et de définir un contexte, mais nous ne filtrons pas une partie des données [avant d'y appliquer l'IA]. Vous obtenez des enseignements cachés supplémentaires (des « hidden insights ») qui vous aident à penser au-delà de votre question initiale. Cela vous aide à poser une autre question à laquelle vous n'aviez peut-être même pas pensé.
LeMagIT : Sur quels autres projets votre équipe travaille-t-elle ?
Elif Tutuk : L'un de nos projets en cours est une expérience visuelle qui permet d'effectuer une analyse multi-attributs sur les données. Nous avons appelé cela Data Swarm (« essaim de données »).
En tant qu'utilisateur, je peux dire au système ce qui m'intéresse... mais avec mon esprit humain, je suis limité par le nombre d'attributs que je peux trouver pour analyser l'ensemble des données. En utilisant des algorithmes, nous pouvons aider l'utilisateur à analyser ses données et ne pas se limiter à une dimension, à une mesure ou à deux attributs. Les algorithmes modélisent les données sous forme de points et créent ainsi une image qui permet de voir les patterns et les valeurs aberrantes.
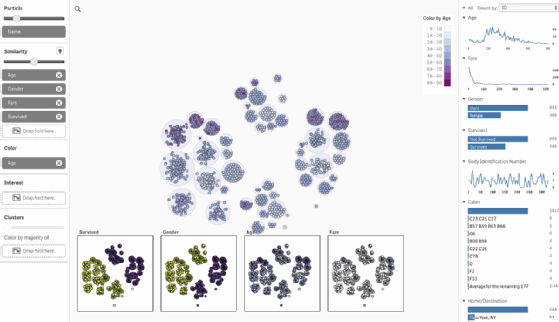
En vous appuyant sur ces patterns - que vous voyez - vous pouvez creuser certaines données et effectuer des analyses plus approfondies avec des visualisations plus traditionnelles, comme des diagrammes à barres ou des graphiques de dispersion.
Data Swarm n'est pas encore disponible mais c'est bon un exemple de la façon dont nous travaillons pour ajouter des capacités d'analyse de grands volumes de données qui ont un grand nombre d'attributs.
CrunchBot devient Qlik Insight Bot
LeMagIT : Qlik a racheté CrunchBot. Qu'est-ce que cela va changer pour vos utilisateurs ?
Elif Tutuk : Effectivement, nous avons récemment fait l'acquisition de CrunchBot pour intégrer le langage naturel dans notre moteur cognitif (Qlik Cognitive Engine).
Au sein de mon équipe Qlik Research, nous avons déjà travaillé sur cette expérience d'analyse conversationnelle.
Je crois fermement que le simple fait d'avoir une barre de recherche n'est plus suffisant pour accompagner les utilisateurs.
Vous utilisez Google lorsque vous connaissez déjà la question que vous voulez poser. Les moteurs de recherche sont parfaits dans ce cas là, parce que vous obtenez des réponses très rapidement. C'est d'ailleurs pourquoi nous continuons à construire un moteur de recherche avec des capacités de langage plus naturelles.
Mais l'expérience de l'analyse conversationnelle que nous sommes en train d'incuber combine ces capacités de recherche et de langage naturel avec une dimension plus visuelle. Imaginez une expérience où vous posez une question, vous obtenez une réponse, et lorsque vous posez la question suivante, nous vous aidons à voir visuellement les chemins que vous empruntez. Vous pouvez littéralement voir le cheminement de votre pensée. C'est une approche vraiment nouvelle de la recherche appliquée à la BI.
Avec la quantité de données dont nous disposons, vous devez vraiment créer une expérience où l'utilisateur peut avoir plusieurs visualisations en même temps et interagir avec elles. De surcroît, lorsque vous interagissez avec telle ou telle visualisation, cela donne à la machine une compréhension de votre contexte et des choses qui vous intéressent. Ce sont des choses qui sont sur notre feuille de route... Nous avons déjà un prototype fonctionnel.
LeMagIT : Et la recherche vocale, quel rôle jouera-t-elle dans les futurs produits de Qlik ?
Elif Tutuk : La voix a aussi sa place [dans la BI]. Si j'étais une commerciale qui se rend à mon prochain rendez-vous, je voudrais poser ma question à voix haute, simplement. C'est une des choses que nous voudrions faire avec Qlik Insight Bot, qui sera le nouveau nom de CrunchBot. Vous pourrez avoir des commandes vocales en plus de la dictée.
Il y a différents utilisateurs qui ont des besoins différents... mais ils ont tous les mêmes attentes : ils veulent utiliser la technologie facilement et ils veulent être épaulés par les données pour obtenir des enseignements qui débouchent sur des décisions ou des actions concrètes. C'est ce sur quoi nous travaillons actuellement chez Qlik Research.





