Hadoop : MapR package trois scenarii d’usage
MapR propose trois kits de démarrage Hadoop pour déployer sa distribution selon trois scénarios d’usage : entrepôt de données, moteur de recommandation et optimisation d’un SIEM.

MapR, l’un des pure-players du monde Hadoop, a profité de la conférence Strata+Hadoop World qui s’est tenue la semaine dernière aux Etats-Unis, pour déployer un peu plus sa stratégie : rapprocher Hadoop du monde des entreprises. Dans ce cadre, la société a présenté ce qu’il baptise des kits de démarrage Hadoop (MapR Quick Start) qui permet de déployer la distribution MapR selon des scenarii définis. Une façon donc d’accélérer l’adoption du framework Java d’une part, mais également de le porter au plus des usages des entreprises.
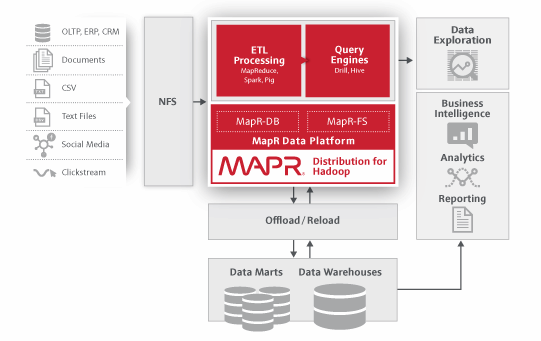
Trois scénarri Big Data ont été identifiés par MapR : optimisation d’un entrepôt de données avec Hadoop pour accroitre par exemple la capacité de traitement ; renforcement d’un système de sécurité SIEM via une capacité accrue d’analyse de logs ou d’incidents ; et mise en place d’un moteur de recommandation, comme on peut le trouver chez nombre d’acteurs du e-commerce.
Un parckage avec des bonnes pratiques
Ces scénarri correspondent à des versions de Quick Start (commercialisées 30 000 dollars chacune) et comprennent « des modules d’ingestion de données, des gabarits de solutions, deux à quatre semaines de services professionnels, une formation intégrée et un petit cluster Hadoop qui peut être facilement étendu selon les exigences de la solution », explique MapR dans un communiqué. L’éditeur affirme s’être appuyé sur des meilleures pratiques.
Ces kits de démarrage Hadoop s’inscrivent dans une stratégie globale de l’éditeur, qui depuis son origine a souhaité faciliter l’intégration d’Hadoop au SI existant des entreprises. Cela passe ainsi par un système de fichiers maison MapR FS, reposant sur NFS – plus commun en entreprise – mais également par le biais de collaboration avec HP notamment autour de HP Vertica Analytics Platform on MapR, ou dans la mise à disposition d’un bac à sable Hadoop pour donner aux développeurs la possibilité de tester le framework.






