Avec Xplain, Cloudera enrichit son Data Hub de possibilités d’analytique en self-service
Cloudera compte intégrer les technologies de Xplain pour mieux préparer Hadoop aux usages en entreprise, par la voie de l’analytique en self-service. Permettre de mieux consommer Hadoop, en somme.

Cloudera a décidé de compléter son concept de plate-forme dite Enterprise Data Hub d’une couche permettant l’analytique en mode self-service. Le pure-player Hadoop a racheté la petite société Xplain.io dont les développements permettent justement d’identifier les typologies de requêtes les plus utilisées et les données les plus sollicitées.
Logiquement, Cloudera compte rapprocher cette technologie de son environnement Hadoop, CDH. Les deux entreprises ont débuté des travaux d’intégration à l’été 2014.
Il faut noter que le modèle de Cloudera ne consiste pas uniquement à bâtir une offre de support Premium autour de Hadoop ou de peaufiner une version entreprise d’une distribution du framework Java. La société, qui compte dans ses actionnaires Intel, adosse son modèle à ce qu’il baptise « l’Enterprise Data Hub », un ensemble de briques technologiques et services qui viennent augmenter Hadoop afin de mieux rendre l’outil « consommable » par les entreprises.
Parmi les développements clé de Cloudera, on se rappelle Impala, un moteur de requêtes SQL massivement parallèle pour Hadoop dont la vocation est d’accélérer les requêtes, quitte à se passer de MapReduce.
Manipuler de nombreux modèles de données
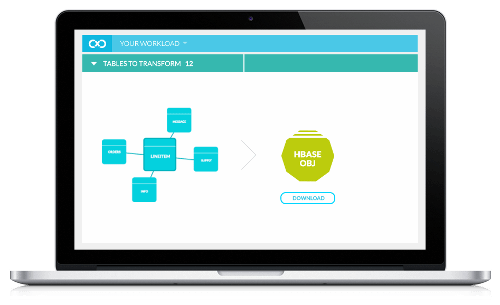
Xplain vient logiquement s’ajouter à ses services satellites permettant de préparer Hadoop à un usage concret en entreprise. “Aujourd’hui, on attend des architectes de la données qu’ils conçoivent, déploiement et entretiennent des data stores avec de nombreux modèles de données comme newSQL, clé / valeur, orienté document, In-Memory. Le problème est très répandu, pourtant aucun outil ne propose de sélectionner le data store le plus efficace pour chaque type de workloads », résume Anupam Singh, l’un des co-fondateurs de Xplain.io dans un billet de blog.
Le moteur développé par cette start-up constitue justement une réponse à ce problème. Il décortique les requêtes récurrentes et donc importantes, en extrait la logique métier et surtout la typologie des données dont l’accès est nécessaire. En dressant une cartographie du modèle de requête, des données associées, de leur modèle et de leur support de stockage (il identifie les tables et les colonnes clés dans chaque workload), Xplain génère des schémas en fonction des patterns identifiés précédemment, les optimise quand nécessaire et créée de nouveaux modèles de données, « sans avoir à coder à la main », précise-t-elle sur son site Internet. Un mécanisme qui a séduit une centaine de clients.
Pour approfondir sur Outils décisionnels et analytiques
-
![]()
Comment le cloud redonne vie aux entrepôts de données
Par: Jack Vaughan
-
![]()
Cloudera et Hortonworks font désormais front commun dans une fusion de 5,2 Md de dollars
Par: Cyrille Chausson
-
![]()
Hadoop ou la force d’un écosystème
-
![]()
Trois méthodes pour bien préparer ses fichiers mainframe à Hadoop
Par: David Loshin


