La course est engagée pour réduire le coût des réseaux de datacenter
Le coût des infrastructures réseau représente une part croissante de celui des datacenters. LeMagIT revient sur les raisons d'une inflation qui explique peut-être le rachat d'Annapurna Labs par Amazon.

La semaine dernière, Amazon a acquis la start-up israélienne Annapurna Labs, qui selon nos confrères du Wall Street Journal, développerait des puces réseau pour les datacenters. La force des composants d’Annapurna serait leur aptitude à transférer plus de données tout en consommant moins d’énergie que leurs concurrentes. Ces puces pourraient être utilisées par Amazon AWS afin d’améliorer l’infrastructure réseau de ses datacenters, une infrastructure qui devient essentielle alors que les flux de données dans le datacenter ne cessent de croître et que le coût des infrastructures réseau prend une part de plus en plus importante dans les dépenses des opérateurs de grands datacenters.
La performance réseau déconnectée de la loi de Moore
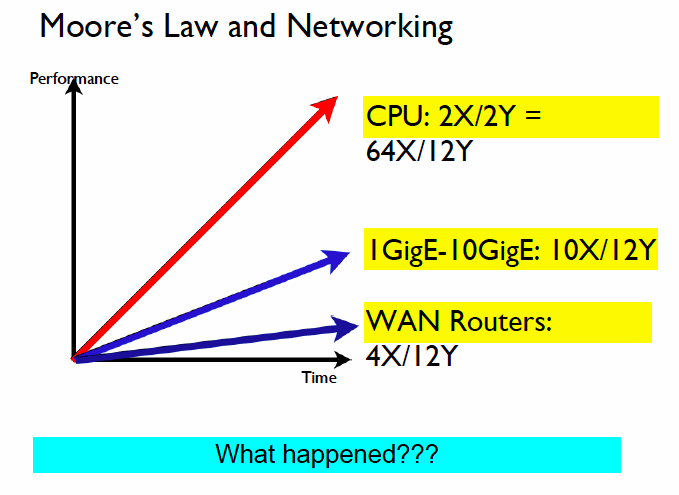 La loi de Moore et les réseaux
La loi de Moore et les réseaux
Comme l’expliquait déjà Andy Bechtholsheim, le cofondateur et Président d’Arista Networks, lors d’une présentation fin 2012 au congrès du groupe des opérateurs télécoms d’Amérique du Nord (Nanog), le coût des infrastructures réseau n’a cessé de progresser au cours des dernières années, l’industrie des télécoms n’ayant pas réussi à suivre le rythme d’évolution des processeurs. Selon Bechtholsheim, la performance des composants réseau n’a pas suivi celle des processeurs : la première a été multipliée par 64 en 12 ans, tandis que celle des réseaux LAN ne progressait que d’un facteur de dix. Dans le même temps, le débit moyen des routeurs WAN augmentait d’un facteur de quatre.
Le problème est que pour tirer parti des processeurs les plus récents il faut les alimenter en données. La performance des réseaux doit donc retrouver une courbe alignée avec celle de la loi de Moore, qui s’applique toujours assez largement aux processeurs.
Pour Bechtholsheim, l’industrie des réseaux doit s’attaquer à plusieurs facteurs pour faire face à ce défi. Le premier est que si la loi de Moore permet de doubler le nombre de transistors, elle ne s’applique pas à leur performance. La vitesse des transistors ne progresse que lentement. Ensuite, le nombre de broches dédiées aux entrées/sorties sur les puces est largement fixe. Ce nombre est contraint par les technologies de packaging et par la taille des puces elles-mêmes (qui a tendance à se réduire), ce qui veut dire que la seule façon de doper les performances est d’accroître le débit par port de sortie. De façon générale, le débit d’I/O d’une puce est facteur du nombre de broches d’entrées/sorties et de leur débit, pas du nombre de transistors sur la puce. Or le débit d’un composant SERDES (Serializer/Deserializer, un bloc fonctionnel dont l’objectif est de collecter les données provenant de multiples liens parallèles pour les transmettre sur un lien point à point en mode série) n’a progressé que de 8 fois en 12 ans et le nombre de SERDES par package n’a progressé que d’un peu plus de 50 % entre 2002 et 2014. De telle sorte que le débit moyen d’une puce de commutation réseau n’a été multiplié que par 10 entre 2002 et 2014 (pour atteindre 8 000 Tbit/s).
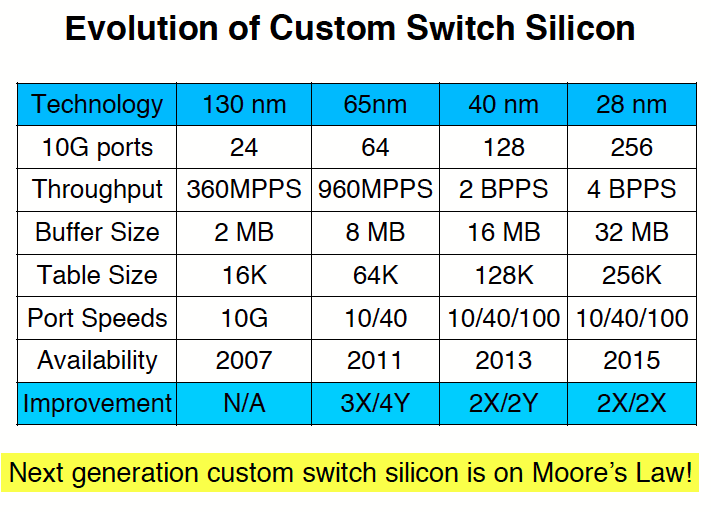 Performance des composants réseaux
Performance des composants réseaux
Selon Bechtholsheim, il y a toutefois de l’espoir, puisque la dernière génération de puces réseau gravées en 28 nm, attendue cette année, devrait afficher des débits 2 fois supérieurs à celle de 2013 (soit un alignement sur la loi de Moore).
L’explosion du trafic Est-Ouest dans les Datacenters
Il n’est que temps. L’arrivée des dernières générations de puces serveurs d’Intel, mais aussi l’émergence de puces ARM 64 bit performantes promet en effet d’accélérer l’adoption du 10 Gigabit, mais aussi du 40 et du 100 Gigabit dans les datacenters. 80 % des serveurs vendus en 2015 disposeront ainsi d’interfaces à 10 Gigabit. Le marché des équipements 10/40/100 gigabit devrait quant à lui passer de 4 Md$ en 2010 à 16 Md$ en 2016 et le nombre de ports actifs de 5 millions à 67 millions.
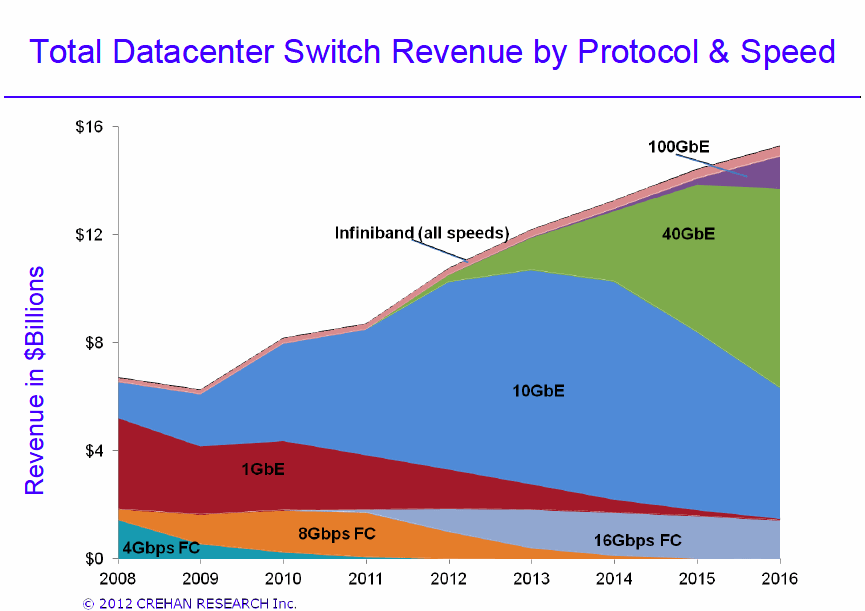 Marché des réseaux de datacenter (Crehan)
Marché des réseaux de datacenter (Crehan)
La plupart de ce trafic sera un trafic Est-Ouest (c’est-à-dire entre serveurs au sein du datacenter) et non pas un trafic Nord-Sud (c’est-à-dire des serveurs vers les utilisateurs). La raison est simple à comprendre : une simple requête d’un utilisateur déclenche en cascade des centaines de transactions entre serveurs au sein du datacenter (par exemple pour la consultation d’un solde bancaire, ou une réservation d’avion ou d’hôtel).
Il y a donc un problème croissant de réseau dans les datacenters. Ce problème a dans un premier temps entraîné la remise à plat des architectures réseau vers des topologies de type Leaf and Spine, mieux adaptées aux nouveaux modèles de trafic. Cette conversion est encore en cours, mais est désormais considérée comme inexorable, y compris par Cisco, qui s’est peu à peu converti à ce modèle.
Réduire le coût des réseaux optiques à 100 Gigabit
Dans un second temps, il se traduit par des efforts intenses de normalisation de nouvelles interfaces réseau, dont de nouveaux débits de 25 et 50 Gbit/s pour Ethernet et de nouvelles interfaces optiques afin d’abaisser le coût des interfaces optiques à 100Gbit qui deviennent nécessaires pour agréger les flots de trafic à 10Gbit/s émanant des serveurs.
L’une des interfaces qui a le vent en poupe est l’interface 100 Gigabit CLR4 soutenue entre autres par Intel, Arista, Brocade, Ciena, Dell, Ebay, HP, Fujitsu et Oracle. Elle vise à standardiser une interface 100 Gigabit d’une portée maximale de 2 km s’appuyant sur des transceivers QSFP + capable de transmettre 4 flux 25 Gbit/s multiplexés sur 4 longueurs d’ondes sur une fibre Single mode duplex (voir à ce propos la présentation de lancement de l’alliance CLR4). Son but est de proposer une interface 100Gbit, bien moins coûteuse et moins gourmande en énergie que les interfaces 100G LR4 (10km) conçues pour le monde des opérateurs télécoms.
Pour approfondir sur LAN, Wifi
-
![]()
Gigabit Ethernet
-
![]()
Cisco dévoile deux familles de commutateurs 400G, l'une pour l'hyperscale, l'autre pour l'entreprise
Par: Christophe Bardy
-
![]()
Ethernet : Le coût de la bande passante dans les datacenters à un plus bas niveau en six ans
Par: Antone Gonsalves
-
![]()
Qualcomm livre des puces 5G pour remplacer la fibre et les réseaux privés
Par: Yann Serra



