Avec Stinger.Next, HortonWorks veut rapprocher Hive du temps réel
Le projet Stinger.Next a pour objectif de poursuivre les améliorations à Hive pour le doter de capacités quasi temps-réel et améliorer sa conformité au standard SQL 2011.

HortonWorks poursuit ses travaux pour améliorer la performance de Hive dans Hadoop et plus généralement pour fournir un moteur SQL performant à même de concurrencer les bases de données traditionnelles. Des travaux qui apparaissent comme logiques dans le cadre de la progression d’Hadoop mais qui pourraient finir par ne pas faire rire les spécialistes des bases de données MPP voire les grands éditeurs de bases de données.
Historiquement, Hive a été conçu comme une technologie de Datawarehouse permettant l’exécution de requête « quasi-SQL » via Map Reduce. Comme nous l’expliquait d’ailleurs HortonWorks il y a deux ans lors d’un entretien, Hive n’a pas à l’origine été conçu pour répondre à des besoins transactionnels, mais plutôt pour permettre l’exécution de requêtes sur de grands volumes de données en mode batch.
Hive : un composant qui connaît une évolution rapide
L’année écoulée a toutefois été marquée par de profondes évolutions pour Hive. Selon HortonWorks, près de 145 développeurs de 44 sociétés différentes ont travaillé ensemble pour doter le logiciel de capacités de requêtage interactif dans le cadre d’un projet baptisé « Stinger ». La dernière phase (phase 3) du projet Stinger a été délivrée avec la version 2.1 d’HDP (HortonWorks Data Platform), la distribution Hadoop d’HortonWorks. Cette nouvelle mouture du logiciel, la 0.13, s’appuie sur YARN, le nouveau gestionnaire de ressources d’Hadoop et sur le projet Apache Tez, un framework de traitement parallèle basé sur Yarn. Apache Tez traduit des requêtes SQL complexes sous la forme de graphes DAG (Directed Acyclic Graph) permettant d’optimiser dynamiquement l’exécution des requêtes en optimisant à la fois les paramètres de bande passante, de performance et de nombre de nœuds.
Parmi les autres améliorations figurent l’aptitude de Hive 0.13 à exécuter des requêtes de façon vectorielle (à l’instar de ce que propose Impala chez Cloudera), ainsi que d’un optimiseur basé sur les coûts (qui aurait notamment profité de l’expertise de Microsoft avec SQL Server). Toutes ces modifications permettraient de doper les performances et d’abaisser grandement la latence des requêtes. Selon HortonWorks, Hive 0.13 délivre des performances jusqu’à 100 fois meilleures que la mouture précédente sur des jeux de données à l’échelle du Pétaoctet.
Stinger. Next : Hive à l’heure du temps réel
Avec le projet Stinger. Next, l’objectif d’HortonWorks et de la communauté Hadoop est de doter Hive de capacités de traitement SQL d’entreprise et de répondre à des besoins de requêtes proches du temps réel.
Plus spécifiquement, Hortonworks indique vouloir apporter la gestion des transactions ACID à Hive pour permettre aux utilisateurs d’un cluster Hadoop d’insérer, modifier et supprimer des enregistrements. L’éditeur indique aussi viser des temps de réponse inférieurs à la seconde pour permettre l’utilisation de Hive pour des tableaux de bord interactifs ou pour des requêtes analytiques nécessitant des temps de réponse courts.
Enfin, l'un des objectifs de Stinger.Next est de renforcer la compatibilité d’Hive avec la sémantique SQL 2011
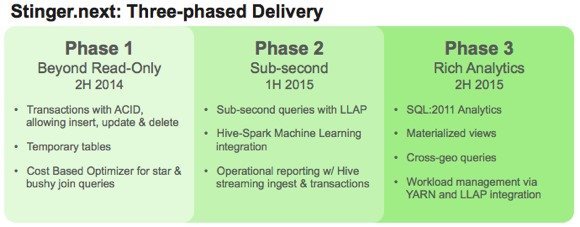
Le projet Stinger.Next sera délivré en trois phases, dont une, avant la fin de l’année, visant à apporter le support des transactions ACID et à étendre le spectre d’application de l’optimiseur à base de coûts intégré dans Hive 0.13.
Une seconde phase, prévue au premier semestre 2015, apportera des améliorations de performances — via un nouveau moteur hybride couplant Tez et LLAP (Live Long and Process), ce dernier intégrant notamment des mécanismes de cache in-memory de tables en colonnes- et l’intégration avec des frameworks de « machine learning ».
Enfin, la dernière phase, attendue au second semestre 2015, apportera notamment le support de la sémantique SQL : 2011 pour l’analytique, la possibilité de lancer des requêtes sur des clusters géographiquement distants et la possibilité de garder en mémoire plusieurs vues des mêmes données pour des raisons de performance (« materialized Views »).
De quoi encore étendre un peu plus les possibilités d’Hadoop, mais aussi de quoi inquiéter les éditeurs commerciaux dans le domaine du datawarehouse…
Pour approfondir sur Outils décisionnels et analytiques
-
![]()
Les principales distributions Hadoop sur le marché
Par: Linda Rosencrance
-
![]()
Presto se loge dans une fondation open source
Par: Jack Vaughan
-
![]()
S3 : une option de stockage de plus en plus utilisée pour Hadoop
Par: Christophe Bardy
-
![]()
Hortonworks ira désormais piocher dans le stockage objet de Google
Par: Jack Vaughan


