Dossier infrastructures 2010 : la convergence au service de la réduction des coûts (2ème partie)
Dans cette seconde partie de notre dossier infrastructures 2010, nous faisons un point sur les perspectives du marché Unix après une année 2009 noire et alors que 2010 sera marqué par une refonte en profondeur des gammes d'HP, IBM et Sun. Nous nous intéressons aussi à la montée en puissance des architectures en cluster dans le stockage et à la convergence entre réseaux de données et réseaux de stockage, alors que Gartner vient de mettre en doute l'intérêt d'un des protocoles phares de cette convergence : FCoE.

AU SOMMAIRE...
1. La virtualisation dope la consolidation de serveurs
2. Pour Intel et AMD, 2010 sera l'année des serveurs
3. Power 7, Itanium, UltraSparc T3 : dans le monde Unix, 2010 s'annonce agité
4. Stockage : les tendances de 2010
5. 2010 année de la convergence des réseaux de données et de stockage ?
6. La tentation du Cloud
Les serveurs Unix sont-ils en passe de devenir des machines de niche, comme le sont devenus au fil des années les grands systèmes IBM ? C’est la question que l’on peut légitimement se poser à la lecture des derniers chiffres d’IDC. Ces derniers font état d’une année 2009 particulièrement noire pour les serveurs Unix, une année où aucun constructeur n’a réellement surnagé, même si IBM a continué à gagner du terrain sur ses concurrents avec ses serveurs Power. Sur le dernier trimestre 2009, les ventes de serveurs Unix ont ainsi reculé de 18,1 % en valeur par rapport à 2008, tandis que les ventes de grands systèmes IBM plongeaient de 27 %. Dans le même temps, les livraisons de serveurs Intel et AMD ont bondi de 3,8 % en unités et de 12,6 % en valeur. Cette évolution est d’autant plus marquante que le 4ème trimestre est, en général, un bon trimestre pour les serveurs Unix. Résultat, sur l’ensemble de 2009, les ventes de serveurs x86 ont représenté plus de 55% des ventes de serveurs en valeur, un record historique. IDC estime que cette tendance va se renforcer en 2010, «alors que les utilisateurs deviennent de plus en plus sensibles aux coûts et se tournent vers les serveurs x86 pour réduire leurs investissements et leurs coûts opérationnels".
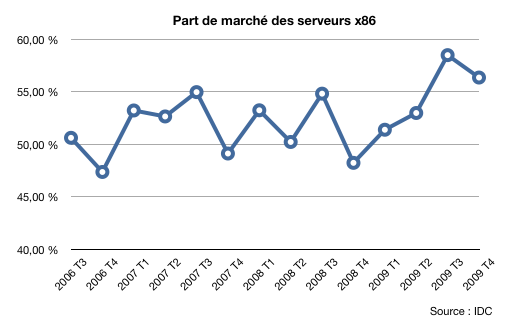
Une tendance accrue à la consolidation
Au cours des dernières années, les processeurs Risc ont largement perdu leur avantage en matière de performances par rapport aux puces x86 d’AMD et Intel. Après des années de dénégation, Intel commence d'ailleurs à l'admettre publiquement, comme nous l'a avoué récemment Scott A. Harrison l'un des directeurs des ventes entreprise d'Intel à l’occasion du lancement des derniers serveurs Dell : Sur bien des secteurs, le Xeon Nehalem-EX sera un redoutable concurrent des puces Itanium. Ce n’est pas faire offense à HP que de l’écrire, juste le constat froid d’une réalité qui plonge dans l’embarras tous les responsables du constructeur. HP n'est toutefois pas le seul concerné par la montée en puissance et en maturité des architectures x86. Sun et Fujitsu, avec leurs puces Sparc, et IBM, avec ses puces Power, doivent eux aussi faire face à la concurrence des plates-formes standards. Avec un bémol, toutefois. D'un point de vue réaliste, les serveurs x86 les plus évolués sont encore loin des capacités des serveurs Unix en matière de partitionnement, de virtualisation, de bande passante système ou d'aptitude à la montée en charge. De plus, l'étroite intégration entre logiciel et matériel dans les serveurs Unix joue encore en leur faveur. La vraie question est désormais de savoir si ces différences sont encore suffisantes pour que les clients acceptent le différentiel de prix. Une certitude : 2010 sera une année clé pour les systèmes Unix. Tour à tour, IBM, HP et Sun vont renouveler tout ou partie de leurs gammes, des gammes qui constitueront le coeur de leur offre pour les deux à trois prochaines années.
HP : Tukwila sera-t-il suffisant ?
Même si HP tente de faire bonne figure, les multiples retards que lui a fait subir Intel dans le développement des différentes versions d'Itanium ont largement handicapé le constructeur sur le marché Unix. Le feuilleton du développement de la dernière mouture d'Itanium en est d'ailleurs le parfait exemple. Alors qu'il aurait déjà dû refondre ses gammes il y a plus de dix huit mois, HP a été contraint de passer l'ensemble de l'année 2009 et une bonne partie de 2010 avec une gamme pour le moins surannée. Le constructeur californien a pourtant fait au mieux avec les armes dont il disposait, et il a finalement mieux résisté que Sun, il est vrai handicapé par les incertitudes liées à l'acquisition par Oracle.
Pour HP, l’avenir immédiat dans les serveurs Unix repose sur le succès des prochains serveurs à base de puces Itanium quadri-coeur 9300 «Tukwila». Finalement dévoilée par Intel en février, la puce devrait faire son apparition d’ici le mois de mai dans les serveurs Unix du constructeur. Le développement de l'Itanium 9300 (nom de code "Tukwila") a connu bien des péripéties. Attendu à l'origine en 2007, "Tukwila" a été repoussé à plusieurs reprises, dont la dernière à l'été 2009, officiellement pour travailler sur une nouvelle technologie d'extension mémoire et la valider avec la puce. Ces multiples retards n'ont fait que dégrader un peu plus l'image d'une plate-forme Itanium mal née et qui a accumulé les retards et déboires tout au long des années 2000. Selon les derniers chiffres de Gartner, les serveurs Itanium ne détiennent plus que 28% du marché Unix. IDC, quant à lui, estime que le chiffre d'affaires généré par les serveurs Itanium représente environ 9,3% du chiffre d'affaires mondial des serveurs, toutes plates-formes confondues (x86, RISC, Mainframes). Environ 95% des ventes de serveurs Itanium sont réalisées par HP.
Techniquement Tukwila devrait permettre à HP de redonner un peu de souffle à des serveurs qui en ont bien besoin. Tout d’abord, la puce devrait singulièrement doper les performances du fait de l'inclusion de quatre coeurs - chacun capable de traiter jusqu'à deux threads en parallèle. L’arrivée de Tukwila devrait aussi se traduire par une refonte en profondeur de l’architecture interne des serveurs HP, du fait notamment de l’arrivée du nouveau bus d'interconnexion QPI (QuickPath) déjà mis en oeuvre sur les derniers Xeon 5500, 5600 et Xeon 7500 (Nehalem EX). Le bus interne des serveurs HP n’avait en effet guère évolué depuis le lancement des premières puces Itanium. Au passage, l'inclusion du contrôleur mémoire directement dans les puces devrait aussi doper la bande passante mémoire de près de 500%. Il sera donc intéressant de voir comment ces modifications placeront HP en termes de performances par rapport à IBM. Notons pour terminer qu’HP ne fait pas mystère que ces serveurs Unix de milieu et de haut de gamme devraient s’appuyer sur une architecture en lames, dont il faudra voir si elle accroît la modularité de son offre, un point qui pourrait être important tant d’un point de vue tarifaire que pour faire face à la montée en puissance des Xeon et autre Opteron. Enfin, Tukwila ne devrait pas avoir l’avantage en matière de ratio performance/watt sur ses concurrents x86. La consommation moyenne est en effet annoncée entre 155W et 185W ( le prix à payer pour une gravure en 65 nm) alors que les Xeon et Opteron (gravés en 32 et 45nm) évoluent entre 80W et 130W.
Une vraie expertise de la production
S’il est une chose que la plupart des DSI reconnaissent, c’est l’expertise de leurs équipes de production Unix, des équipes - souvent internes mais aussi pour partie externes - souvent bien formées à l’exploitation pointue de ces machines. Au delà du débat sur les performances et sur les prix, cette expertise est un vrai rempart pour les serveurs Unix.
Car, si souvent les serveurs x86 sont utilisés pour fournir les services essentiels d’infrastructure (annuaire, partage de fichiers et d’imprimantes), les services de frontal web ainsi qu’une large part des fonctions de serveurs d’applications, les serveurs Unix continuent à être utilisés pour les applications les plus critiques, des applications dont les utilisateurs tolèrent mal l’indisponibilité. Les administrateurs Unix ont ainsi été parmi les premiers à se frotter aux technologies de cluster, de virtualisation ainsi qu’au réseaux de stockage. Des expertises précieuses tant pour les entreprises qui continuent à faire reposer leur production critique sur des serveurs Unix, que pour celles qui peu à peu adoptent les environnements AMD et Intel. D’autant que si ces derniers fonctionnent sous Linux ou Solaris x86, le pas à franchir n’est souvent pas si grand que cela.
IBM : «I’ve got the Power»
Depuis le lancement du Power6, IBM a le luxe de pouvoir articuler un discours sur la performance unitaire de ses puces, un discours que ne peuvent plus mener ses concurrents. Et ce discours s’est encore renforcé avec le lancement récent du Power7. Il faut reconnaitre à IBM qu’il a su préserver l’avantage technologique de Power mais, surtout, que ses roadmap n’ont pas connu les errements de celles de ses concurrents. Ce qui a permis à Big Blue de gagner de façon régulière du terrain sur HP et Sun, au cours des trois dernières années. Pour autant, comme ses concurrents, IBM n'a pas réussi à enrayer la baisse des ventes face à des serveurs x86 de plus en plus séduisants.
Dell expliquait récemment que la recette des serveurs x86 est leur capacité à allier l’économie (affordability), les fonctionnalités (capability), et l’ouverture (Openess). Et de tirer à vue sur les serveurs Unix, en expliquant que s’il est facile pour un IBM d’offrir les fonctionnalités à un prix élevé, il est bien plus difficile pour un serveur Unix d’allier ouverture, économie et fonctionnalité, par manque d’effet de volume. Pourtant, ce sera sans doute à l’aune de ce tryptique que seront jugés les serveurs Unix face aux serveurs x86 dans les années à venir. Et si IBM peut se prévaloir, au moins pour l'instant, de la supériorité technologique, il n’est pas certain que cela suffise à redynamiser le secteur des serveurs Unix. Reste que Big Blue peut très bien se satisfaire de continuer à grignoter des points sur ses concurrents sur un marché où chaque point de part de marché équivaut à 131 M$ chaque année (sur la base de 2009 - et ce sans compter les ventes de services et de logiciels liées aux serveurs Unix).
Larry au pays des merveilles
Quant à Sun (pardon, Oracle), bien malin qui pourrait dire quelle est en vérité sa stratégie. Les roadmap Sparc des deux dernières années n’ont pas été un modèle de stabilité. Les dernières ressemblent même à une de ces spécialités qu’avaient les responsables soviétiques : supprimer toute trace des vilains petits canards de la photo. La dernière version officielle de l'avenir de Sparc est digne de la Pravda : Sun a, sur ses roadmaps, quatre processeurs Sparc et n’en a jamais eu autant. Tout serait donc merveilleux au pays d’Alice (pardon, de Larry). La vérité est que l’UltraSparc Rock, longtemps présenté comme la puce qui devait marquer le renouveau technologique de Sparc a été jetée aux orties sans cérémonie et effacée de l’histoire. Il en va de même des serveurs qui devaient les accompagner, les mal nommés Supernova. Plus de cinq années de développement sont ainsi passés à la trappe, laissant un trou béant dans la gamme de Sun. Le constructeur aurait pourtant pu s’en douter : baptiser un serveur Supernova quand on s’appelle Sun n’était sans doute pas raisonnable, où alors c’était prémonitoire (NDLR : une supernova est le fruit certes momentanément très visible de l’effondrement ou de l’explosion d’une étoile mais marque, de fait, sa disparition). Notons que ce n’est pas la première fois qu’un tel désastre industriel frappe le constructeur qui avait déjà du jeter aux orties l’UltraSparc V et se résoudre à adopter les puces Sparc64 de Fujitsu (ce qui veut dire que, pour l’essentiel, le haut de gamme de l’offre de serveurs Sun est aujourd’hui largement inspiré - ou dépendant - des travaux du Japonais).
A court terme, Sun doit faire face à un double problème. A bien des égards, les serveurs à base d’UltraSparc T2+ ne sont plus compétitifs avec les serveurs x86 en matière de rapport performance par watt et par euro (ce qui est d'ailleurs le cas de l'entrée de gamme Unix de tous ses concurrents). Le haut de gamme est quant à lui distancé en matière de performances par les récents serveurs Power7. D'ici l'automne, le lancement des UltraSparc T3, des puces à 16 coeurs chacun capable de traiter 8 threads en parallèle devrait redonner du souffle à l’entrée/milieu de gamme de Sun. En revanche, le petit accroissement de fréquence prévu pour le second semestre sur le haut de gamme Sparc64 - avec le Sparc64 "Jupiter-E" - ne devrait rien changer à l’offre de Sun. Pour un vrai bond, il faudra attendre 2012 et la seconde génération de serveurs APL à base de puces Sparc64 VIII (nom de code Venus), autant dire une éternité. Reste que le monde Unix ne se juge pas qu'à l'aune des performances. Et chez Sun, le vrai joyau de la couronne, c'est Solaris, le système d'exploitation Unix de la marque. Alors que ses concurrents AIX et HP-UX ont tendance à évoluer à un rythme de sénateur, Solaris a été enrichi de multiples innovations au cours des trois dernières années. De l'avis même de nombreux administrateurs Unix, Solaris constitue sans doute aujourd’hui ce qui se fait de mieux en matière de système Unix avec notamment des points forts en matière de gestion du multithread, de supervision, de stockage et de virtualisation. De quoi pour certains faire oublier certaines des faiblesses de l'offre matérielle du constructeur...
A lire aussi sur LeMagIT :
- Les nouveaux serveurs Power7 éclipsent les serveurs Sparc et Itanium
- IBM mise sur Power 7 pour conforter sa suprématie sur le marché Unix
- La Mutualité Française tire le bilan de deux ans et demi de virtualisation avec l'hyperviseur HP
- Intel dévoile l'Itanium 9300 "Tukwila"
- La vision d'Ellison après le rachat de Sun : Oracle en 2010 = IBM en 1960
- Serveurs Unix : Sun et Fujitsu contrent le Power6 avec le Sparc64 VII quadri-coeur
Comme dans le monde des serveurs, les grands du stockage s’interrogent sur ce que sera l’avenir des systèmes de stockage dans les prochaines années avec une question primordiale : faut-il aller vers des architectures massivement distribuées ou se satisfaire d’une évolution des architectures actuelles des baies modulaires, qui ont peu à peu détrôné les grandes baies monolithiques.
Dans le monde des serveurs de fichiers NAS et des systèmes de gestion de contenus, la réponse semble de plus en plus évidente. Pour le NAS, des pionniers comme Exanet, Isilon, Panasas, Polyserve ou comme le français Active Circle ont ouvert la voie aux architectures massivement distribuées en permettant la constitution de gigantesques systèmes NAS raccordant parfois plusieurs centaines de noeuds chacun dotés à la fois de capacité de stockage, de capacités d’entrées/sorties et de capacité CPU. Le résultat, des systèmes dont les performances et la capacité s’accroissent avec le nombre de noeud et qui ont fait leur preuve dans des secteurs exigeants comme le calcul intensif, le stockage et la distributions de médias.
Une évolution similaire s’est produite dans l’archivage avec l’apparition de systèmes de stockage de contenus (CAS - pour Content Adressable Storage- ou Object Storage, selon le nom qu’on leur donne). Le Centera chez EMC, fruit des travaux menés dans les années 90 par FilePool) a ouvert une voie dans laquelle se sont ensuite engouffrés HP, Hitachi Data Systems (avec HCAP) et Sun (qui a toutefois fini par tuer dans l’oeuf son produit CAS Honeycomb, mais qui dispose toujours de plusieurs cartes avec Lustre, SAM-QFS et même pNFS) ainsi qu’une nouvelle génération de startups telles que Cleversafe ou Caringo (récemment retenu par Dell pour son DX6000). Tous ces systèmes ont généralement en commun le fait de distribuer et de répliquer - parfois à plusieurs exemplaires - leurs contenus entre plusieurs noeuds. En cas de perte d’un noeud, ses contenus - déjà répliqués et distribués sur d’autres noeuds - sont tout simplement rerépartis sur les noeuds survivants assurant ainsi une reconstruction souvent plus rapide qu’avec des systèmes RAID.
L'ère du NAS à grande échelle
Plus que jamais, les architectures distribuées semblent devoir s’imposer pour les NAS à grande échelle et pour le stockage de contenus. En faisant l’acquisition d’Ibrix (après avoir déjà acheté Polyserve), HP a ainsi clairement marqué son intention de faire des architectures massivement distribuées son avenir dans le NAS. IBM a fait de même en annonçant en février son offre SONAS destinée à la constitution de grands dépôts NAS assemblés à base de serveurs banalisés (côté logiciel, l’offre repose sur GPFS, le système de fichiers en cluster d’IBM et sur SOFS - Scale Out File Services - qui fournit les services de fichier en réseau au dessus des noeuds de stockage GPFS). EMC a lui aussi franchi le pas avec son offre pour les Cloud, baptisée Atmos, tandis que Dell semble lui aussi prendre la même route, même s’il n’a pas encore précisé ce qu’il entend faire de son acquisition des technologies d’Exanet.
Quoique moins radical, NetApp peut lui aussi offrir des solutions en cluster à grande échelle depuis son acquisition de Spinnaker et surtout depuis le lancement d’Ontap 8, la version de son OS qui fait converger le code historique de NetApp avec celui de Spinnaker. Mais, pour l’instant, le constructeur ne semble pas voir d’urgence à casser son modèle établi, même si Ontap 8 lui permet désormais de proposer des architectures en cluster de grande taille.
HDS s'appuie, quant à lui, sur l'offre de BlueArc pour son offre de NAS en cluster HNAS. Cette offre n'est pas vraiment batie sur des composants banalisés, mais elle a une caractéristique intéressante, celle de permettre d'agréger des stockage hétérogènes en un seul et unique namespace. Notons pour terminer ce point sur le NAS en cluster que des solutions open-source pré-assemblées commencent à faire leur chemin comme celle de Gluster.
Le SAN se met lui aussi aux clusters
Dans le monde du stockage en mode bloc, les architectures distribuées progressent elles aussi à pas rapide, même si elle ne sont pas encore le cas général. Parmi les grands, IBM est le premier a avoir souscrit à l’approche distribuée en acquérant XiV, la start-up cofondée par Moshe Yanai, connu pour avoir été le père des Symmetrix chez EMC. Comme dans le NAS en cluster, le principe est le même : chaque noeud est à la fois noeud de stockage, noeud de connexion et noeud CPU, ce qui permet d’améliorer tant la capacité que les performances à chaque ajout de noeud (le nombre maximum est en général dépendant du type d’interfaces utilisées pour connecter les noeuds). Le fait que chaque noeud dispose aussi de sa propre puissance CPU permet aussi d’envisager de confier aux noeuds de nouvelles fonctions (compression de données, déduplication...).
HP a également un pied dans le marché du SAN en cluster depuis le rachat de LeftHand Networks, de même que Dell qui permet de grouper jusqu’à 16 noeuds Equallogic P6000 dans un ensemble iSCSI unique. EMC en revanche s’est prononcé à plusieurs reprises contre les architectures distribuées pour le stockage en mode bloc et a fermement démenti tout intérêt pour ces approches lors du dernier EMC World. Il sera intéressant de voir si le constructeur tient toujours le même discours cette année. Hitachi s'est également tenu à l'écart des approches distribuées jusqu'à ce jour, et il sera donc intéressant d’observer ce que sera l'architectures des futures baies SAN du constructeur.
Notons pour terminer que les approches en cluster sont générales dans le cloud. Des start-ups telles de Zetta, mais aussi des grands noms comme Google, Yahoo ou FaceBook appuient leur stockage sur des architectures distribuées. C’est aussi le cas de l’offre de cloud de Canonical (sur base Eucalyptus) et de l’offre de Joyent.
En savoir plus :
Alors que tous les grands constructeurs chantent les louanges de la convergence, Gartner vient de donner un coup de pied dans la fourmilière en publiant un article intitulé « Mythe : un réseau de datacenter unique à base de FCoE = moins de ports, moins de complexité et moins de ports». Selon le cabinet d’analyse, c’est exactement le contraire : un réseau convergé requiert plus de commutateurs et de ports, est plus complexe à administrer et consomme plus d’énergie que deux réseaux séparés. « La promesse selon laquelle un réseau unique convergé dans le datacenter requerrait moins de ports et de commutateurs ne résiste pas à l’analyse », explique Joe Skorupa de Gartner. « Cela est lié au fait que lorsque le réseau croit au delà de la capacité d’un commutateur, il faut consacrer des ports à l’interconnexion de switch. Résultat, dans de grands réseaux maillés, des commutateurs entiers ne font rien d’autre que de connecter des switchs avec d’autres switchs. Le résultat est qu’un réseau convergé consomme plus de ports que deux réseaux séparés, l’un pour le LAN l’autre pour le SAN. De plus, dans la mesure où il faut plus de matériel, il est peu probable que les coûts de maintenance et de support soient réduits. »
Si le raisonnement de Skorupa est défendable, du moins sur certains points, il néglige quelques évidences, à commencer par le fait que l’on est encore loin de disposer d’une version standardisée de FCoE capable de supporter des réseaux à grande échelle. Notamment, aucun équipement du marché n’implémente pour l’instant les protocoles nécessaires pour constituer des SAN FCoE Multi-hop (quand ces protocoles existent). Il ignore aussi une autre réalité : ce n’est pas parce que les technologies seront convergées que les réseaux le seront nécessairement. Il est ainsi tout à fait possible que, pour les environnements les plus critiques, FCoE soit dans un premier temps déployé sur un réseau Ethernet physiquement séparé du réseau de données.
CIFS, NFS et iSCSI : la convergence déjà disponible
En attendant que FCoE ne mûrisse, les entreprises peuvent toutefois déjà goûter à la convergence entre réseaux de données et réseaux de stockage en utilisant des protocoles de stockage basés sur IP tels que CIFS, NFS ou iSCSI. Les deux premiers permettent de mettre en place des services de stockage en mode fichiers tandis que le dernier permet de délivrer des services de stockage en mode bloc. CIFS a une utilisation quasiment exclusivement limitée au partage de fichiers tandis que NFS est à la fois utilisé pour le partage de fichiers et pour le stockage de machines virtuelles. En environnement NetApp, par exemple, NFS est aujourd’hui le protocole le plus utilisé pour le déploiement de la virtualisation. iSCSI enfin, est le protocole qui a connu la plus forte croissance au cours des deux dernières années.

Les chiffres de l’observatoire du stockage le plus récent d'IDC révèlent ainsi que les ventes d'équipements de stockage iSCSI ont bondi de 25% au troisième trimestre 2009 par rapport au même trimestre en 2008, tandis que le marché mondial du stockage reculait de 7,6%. Les premier et second trimestres de 2009 avaient montré une tendance similaire, permettant aux équipements iSCSI d'atteindre 17% du marché total du stockage en réseau au troisième trimestre, selon IDC. Pour mémoire, iSCSI représentait 6% du marché du stockage en 2007 et 13% sur les trois premiers trimestres de 2009. Dans le même temps, Fibre Channel est passé de 72 à 61% des ventes. Les résultats d'une étude récente d'Enterprise Strategy Group (ESG), portant sur près de 1500 entreprises, révèlent par ailleurs que 28% des entreprises américaines utilisent maintenant les SAN iSCSI, et que 24 % supplémentaires entendent mettre en oeuvre prochainement la technologie.
iSCSI : moins cher et de plus en plus mûr
"Alors qu'on le trouvait traditionnellement plutôt dans l'entrée de gamme, iSCSI s'est largement déployé l'an dernier", estime quant à elle Natalya Yezhkova, pour le cabinet d'études IDC. "Nous avons vu iSCSI se déployer un peu dans tous les domaines, l'entrée de gamme, le milieu de gamme, et les systèmes d'entreprises". Les arguments de base en faveur d'iSCSI ont toujours été la facilité d'utilisation et le prix; et maintenant il dispose aussi de fonctionnalités avancées. Les fonctions de classe entreprise et de protection de données ajoutées récemment aux systèmes de stockage iSCSI en font des alternatives aux systèmes Fibre Channel, même pour les grands comptes." D'ailleurs, le sondage mené par l'Entreprise Strategy Group montre que les grands comptes ont adopté iSCSI de façon plus vigoureuse que les PME, avec 61% des grandes entreprises (plus de 20 000 employés) qui utilisent ou envisagent d'utiliser iSCSI, contre 47% des entreprises du "mid-market".
Chez l'éditeur bordelais Lectra, spécialiste des logiciels de design et de prototypage pour la mode et l'industrie, iSCSI est utilisé en complément de Fibre Channel pour des raisons économiques. Comme l'explique Jean-Christophe Glot, le DSI de Lectra, si l'utilisation de Fibre Channel se justifie pour les applications critiques de la société, iSCSI permet quant à lui de démocratiser la connexion SAN pour les autres applications. Dans un contexte de production largement virtualisée (pour l'essentiel sur serveurs x86 sous VMware ESX Server 3.5), iSCSI est aujourd'hui utilisé par environ la moitié des 250 serveurs de la société - ceux pour lesquels le coût de Fibre Channel ne se justifiait pas - pour accéder aux deux baies SAN EMC Clariion CX4. Selon Jean-Christophe Glot, l'usage d'iSCSI a permis à Lectra de faire l'économie de coûteux commutateurs FC et de HBA. "Nous utilisons des trunks Gigabit Ethernet (liaisons composées de plusieurs connexions agrégées, NDLR). Les performances sont un cran en dessous de ce que permet un SAN Fibre Channel 4 GBit/s, mais restent très acceptables".
Shawn Houston, le responsable technique au sein du Groupe de calcul en biotechnologie de l'Université d'Alaska Fairbanks, utilise de son côté un système de stockage iSCSI mixant des équipements Nexsan Technologies et des ponts iSCSI Sanrad depuis près de quatre ans. "Nous aurions préféré aller vers un SAN Fibre Channel, mais des considérations de prix nous ont amené à opter pour un système moins cher", explique-t-il. A posteriori, Houston ne regrette pas sa décision. "Quand je benchmarke le système, j'obtiens environ 80% de la performance d'un système FC, mais à une fraction du coût. En fait, le système ne nous a jamais déçu."
Le 10 Gigabit Ethernet pourrait doper iSCSI face à FCoE
Depuis son lancement, iSCSI s'appuie pour l'essentiel sur l'utilisation de liens Gigabit Ethernet alors que Fibre Channel a bénéficié de l'augmentation des débits du standard de 1 Gbit/s à 2 Gbit/s puis à 4 et 8 Gbit/s. La disponibilité du 10Gigabit Ethernet devrait apporter des améliorations, en matière de latence et de performances. Les systèmes LeftHand d'HP supportent ainsi le 10 Gigabit depuis un an, et Dell a récemment ajouté le support du 10 GbE aux systèmes EquaLogic. EMC a fait de même sur les Clariion CX4 à l'automne; NetApp propose aussi depuis l'an passé le support du 10GE sur ses baies.
Chez les analystes, le consensus général est que les PME devraient continuer à adopter iSCSI, tandis que les entreprises, avec un investissement lourd dans la technologie Fibre Channel, préféreront Fibre Channel over Ethernet. En attendant, iSCSI pourrait avoir une carte à jouer, puisqu'il faudra quelques années avant que l'usage de FCoE ne se banalise. Chez IDC, Natalya Yezhkova indique que FCoE va probablement ralentir un peu l'adoption d'iSCSI, mais pas l'arrêter. "Nous nous attendons à ce qu'iSCSI continue à grignoter des parts de marché aux dépens de Fibre Channel", dit-elle. Pour Andrew Reichman, analyste chez Forrester Research, "l'adoption d'iSCSI entraine moins de perturbations que FCoE, qui exige une migration massive vers des commutateurs 10 Gigabit de dernière génération conformes aux standards CEE.(...) C'est un avantage pour iSCSI qui peut être déployé plus progressivement et avec les équipements disponibles aujourd'hui".
Autant dire que si FCoE est présenté comme le protocole de la convergence, il n’est pas sûr qu’il ne soit pas supplanté dans ce rôle par d’autre protocoles. Si du moins la convergence annoncée se produit...




